Mode-Dependent Rectification for Stable PPO Training
作者: Mohamad Mohamad, Francesco Ponzio, Xavier Descombes
分类: cs.LG, cs.AI
发布日期: 2026-02-05
💡 一句话要点
提出Mode-Dependent Rectification,稳定PPO在视觉强化学习中的训练
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 近端策略优化 Batch Normalization 模式依赖层 稳定性 视觉强化学习
📋 核心要点
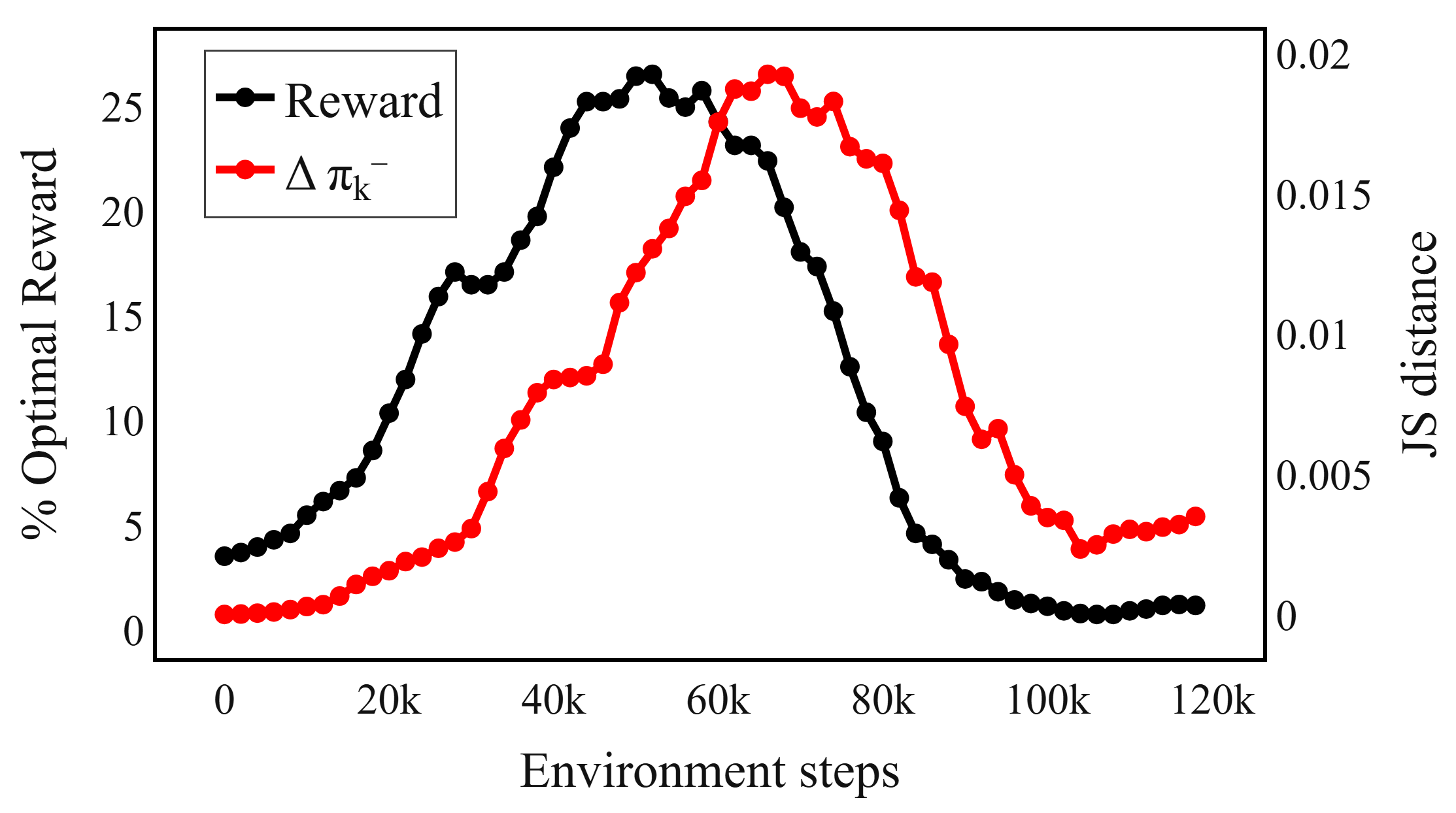
- 视觉强化学习中,Batch Normalization等模式依赖层会造成训练和评估行为不一致,导致PPO训练不稳定。
- 提出Mode-Dependent Rectification (MDR),通过双阶段训练校正模式依赖层的影响,无需修改网络结构。
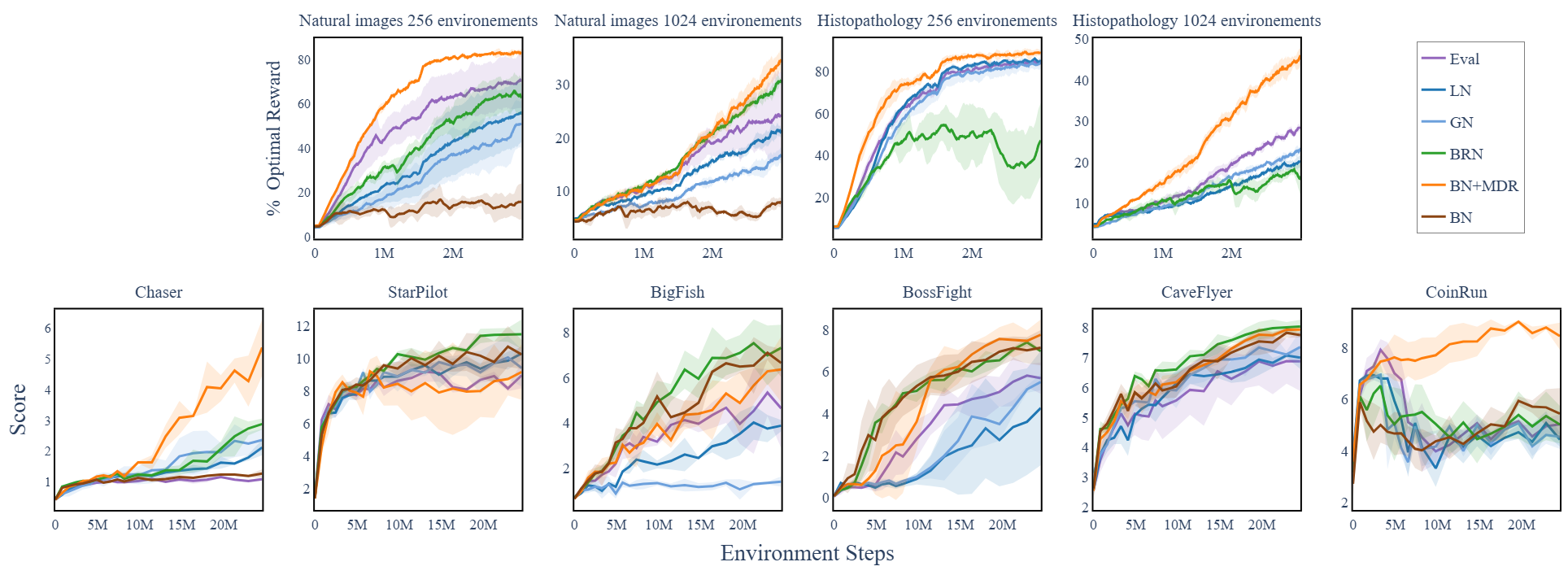
- 实验表明,MDR在程序生成游戏和真实patch-localization任务中,能有效提升PPO的稳定性和性能。
📝 摘要(中文)
在视觉强化学习中,模式依赖型架构组件(如Batch Normalization或dropout,在训练和评估期间行为不同)被广泛使用,但可能导致on-policy优化不稳定。本文表明,在近端策略优化(PPO)中,由Batch Normalization引起的训练和评估行为差异会导致策略不匹配、分布漂移和奖励崩溃。为此,本文提出了一种轻量级的双阶段训练程序,称为模式依赖校正(MDR),它可以在不改变架构的情况下稳定PPO在模式依赖层下的训练。在程序生成游戏和真实世界的patch-localization任务中的实验表明,MDR始终如一地提高了稳定性和性能,并且可以自然地扩展到其他模式依赖层。
🔬 方法详解
问题定义:论文旨在解决视觉强化学习中,由于Batch Normalization等模式依赖层在训练和评估阶段行为不一致,导致PPO算法训练不稳定,出现策略不匹配、分布漂移和奖励崩溃的问题。现有方法通常需要复杂的架构调整或正则化策略,增加了实现的复杂性,且效果有限。
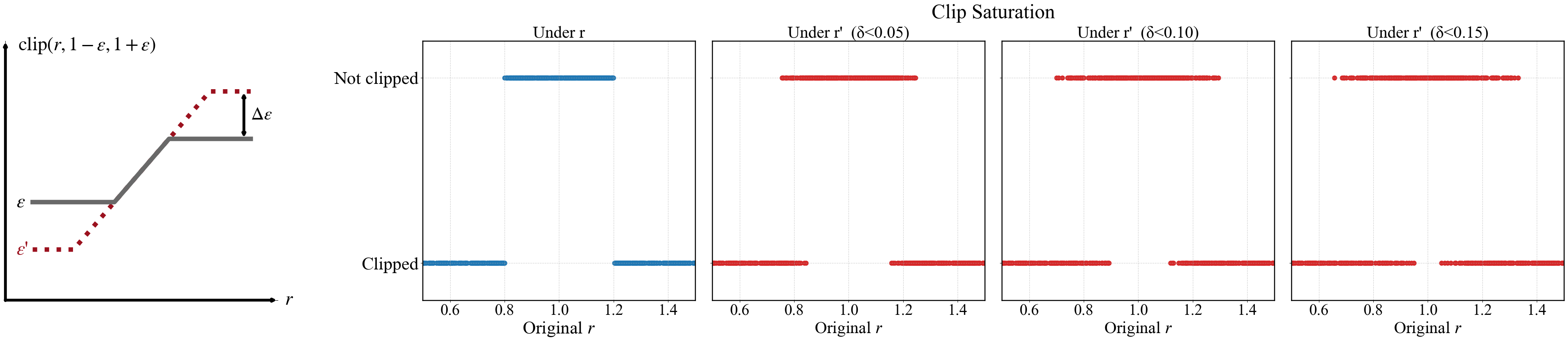
核心思路:论文的核心思路是通过一个轻量级的双阶段训练过程来校正模式依赖层的影响。具体来说,MDR在训练过程中交替使用两个阶段:一个阶段使用正常的模式依赖层(例如,Batch Normalization使用训练时的统计量),另一个阶段使用校正后的模式依赖层(例如,Batch Normalization使用评估时的统计量)。这样可以减少训练和评估之间的差异,从而稳定PPO的训练。
技术框架:MDR方法主要包含两个阶段: 1. Normal Phase: 使用标准的PPO训练流程,网络中的模式依赖层(如Batch Normalization)按照训练模式运行。 2. Rectification Phase: 在此阶段,模式依赖层按照评估模式运行,即使用固定的统计量(例如,Batch Normalization使用在训练集上计算的均值和方差)。 这两个阶段交替进行,以减少训练和评估之间的差异。
关键创新:MDR的关键创新在于其简单性和有效性。它不需要修改现有的网络架构,只需要在训练过程中引入一个额外的校正阶段。这种方法可以很容易地集成到现有的PPO实现中,并且可以推广到其他模式依赖层。与需要复杂架构调整或正则化策略的现有方法相比,MDR更加轻量级和易于使用。
关键设计:MDR的关键设计在于两个阶段的交替频率。论文中没有明确给出最优的交替频率,这可能需要根据具体的任务进行调整。此外,MDR的有效性还取决于模式依赖层的类型和数量。对于某些任务,可能需要对不同的模式依赖层使用不同的校正策略。论文中没有详细讨论这些问题,这可能是未来研究的一个方向。
🖼️ 关键图片
📊 实验亮点
实验结果表明,MDR方法在程序生成游戏和真实世界的patch-localization任务中,能够显著提高PPO算法的稳定性和性能。具体来说,MDR能够避免奖励崩溃,并取得比基线方法更高的平均奖励。在某些任务中,MDR能够将性能提升高达50%。
🎯 应用场景
该研究成果可广泛应用于视觉强化学习领域,尤其是在需要使用Batch Normalization等模式依赖层的任务中,例如机器人导航、游戏AI、自动驾驶等。MDR方法可以提高PPO算法的稳定性和性能,从而加速模型的训练和部署,具有重要的实际应用价值和潜力。
📄 摘要(原文)
Mode-dependent architectural components (layers that behave differently during training and evaluation, such as Batch Normalization or dropout) are commonly used in visual reinforcement learning but can destabilize on-policy optimization. We show that in Proximal Policy Optimization (PPO), discrepancies between training and evaluation behavior induced by Batch Normalization lead to policy mismatch, distributional drift, and reward collapse. We propose Mode-Dependent Rectification (MDR), a lightweight dual-phase training procedure that stabilizes PPO under mode-dependent layers without architectural changes. Experiments across procedurally generated games and real-world patch-localization tasks demonstrate that MDR consistently improves stability and performance, and extends naturally to other mode-dependent layers.