Path-Guided Flow Matching for Dataset Distillation
作者: Xuhui Li, Zhengquan Luo, Xiwei Liu, Yongqiang Yu, Zhiqiang Xu
分类: cs.LG, cs.AI
发布日期: 2026-02-05
💡 一句话要点
提出路径引导的Flow Matching,用于高效数据集蒸馏,提升下游泛化能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 数据集蒸馏 Flow Matching 生成模型 常微分方程 VAE 路径引导 模型压缩
📋 核心要点
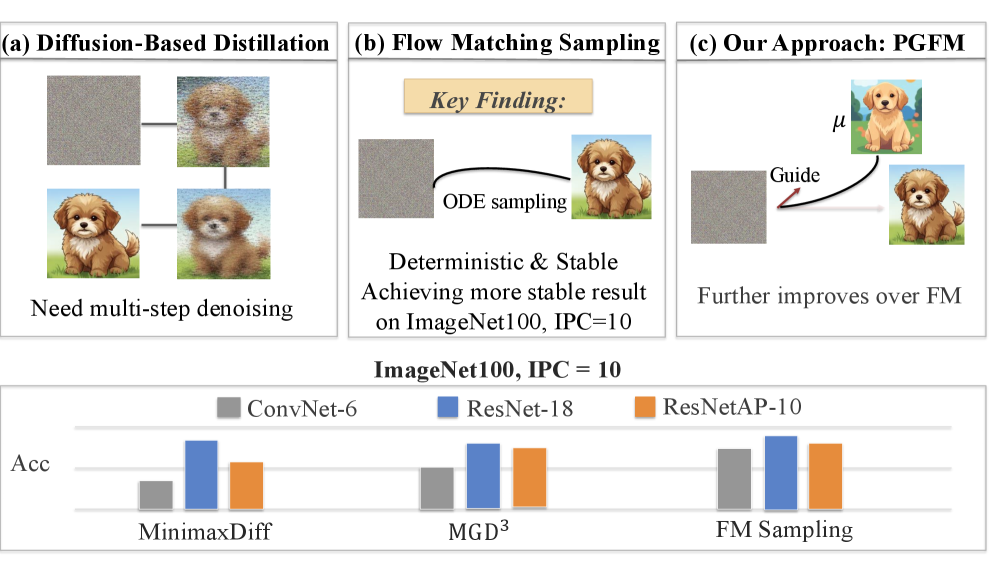
- 现有数据集蒸馏方法依赖启发式引导或原型分配,导致采样耗时和轨迹不稳定,影响下游泛化能力。
- 提出PGFM,利用Flow Matching学习从高斯噪声到数据分布的类条件传输,实现快速确定性合成。
- 实验表明,PGFM在保证性能的同时,显著提升了效率,例如比扩散方法效率高7.6倍。
📝 摘要(中文)
数据集蒸馏旨在将大型数据集压缩为紧凑的合成数据集,并在训练模型时保持可比的性能。尽管最近基于扩散的蒸馏方法取得了一些进展,但它们通常依赖于启发式引导或原型分配,这导致耗时的采样和轨迹不稳定性,从而损害下游泛化能力,尤其是在强控制或低IPC下。我们提出了路径引导的Flow Matching (PGFM),这是第一个基于Flow Matching的生成蒸馏框架,它通过在几个步骤中求解ODE来实现快速确定性合成。PGFM在冻结VAE的潜在空间中进行Flow Matching,以学习从高斯噪声到数据分布的类条件传输。特别地,我们开发了一种连续的路径到原型引导算法,用于ODE一致的路径控制,这使得轨迹能够可靠地落在分配的原型上,同时保持多样性和效率。在高分辨率基准上的大量实验表明,PGFM在更少的采样步骤下匹配或超过了先前的基于扩散的蒸馏方法,同时提供了具有竞争力的性能和显着提高的效率,例如,比基于扩散的同类方法效率高7.6倍,模式覆盖率达到78%。
🔬 方法详解
问题定义:数据集蒸馏旨在用少量合成数据替代原始大数据集,以加速模型训练并降低存储成本。然而,现有的基于扩散模型的数据集蒸馏方法通常需要大量的采样步骤,计算成本高昂,并且依赖启发式引导或原型分配,导致训练轨迹不稳定,影响下游任务的泛化性能,尤其是在数据量极少的情况下。
核心思路:PGFM的核心思路是利用Flow Matching框架,通过求解常微分方程(ODE)来学习从高斯噪声到数据分布的连续映射。与扩散模型相比,Flow Matching能够实现确定性的数据生成,大大减少了采样步骤,从而提高了效率。此外,PGFM引入了路径引导机制,确保生成的数据能够可靠地落在预先设定的原型附近,从而提高数据的代表性和多样性。
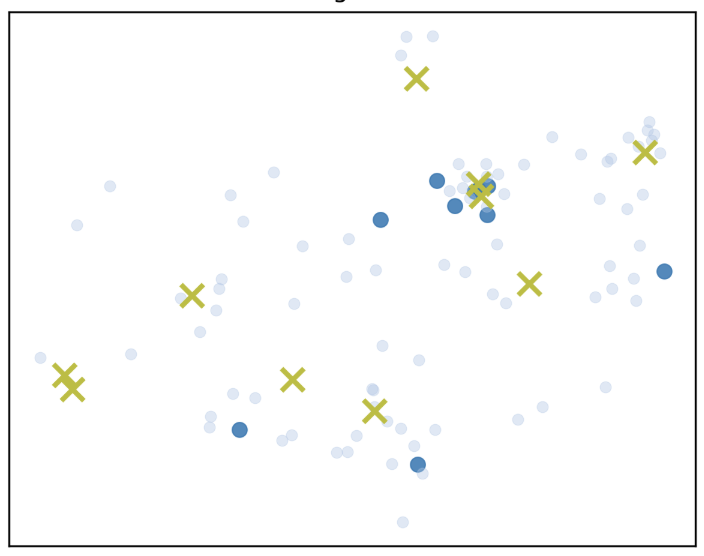
技术框架:PGFM的整体框架包括以下几个主要模块:1) 冻结的VAE:使用预训练的VAE将原始数据映射到潜在空间,并在潜在空间中进行Flow Matching。2) Flow Matching模块:学习从高斯噪声到数据分布的连续映射,通过求解ODE实现数据生成。3) 路径引导模块:引入连续的路径到原型引导算法,控制ODE的轨迹,确保生成的数据落在预先设定的原型附近。
关键创新:PGFM的关键创新在于将Flow Matching框架应用于数据集蒸馏,并引入了路径引导机制。与现有的基于扩散模型的方法相比,PGFM能够实现更高效、更稳定的数据生成,并且能够更好地控制生成数据的分布。此外,连续的路径到原型引导算法是PGFM的另一个创新点,它能够确保生成的数据落在预先设定的原型附近,从而提高数据的代表性和多样性。
关键设计:PGFM的关键设计包括:1) 使用预训练的VAE来提取数据的潜在表示,从而降低Flow Matching的难度。2) 使用ODE求解器来生成数据,例如Runge-Kutta方法。3) 设计合适的损失函数来训练Flow Matching模型,例如最小化预测速度场与真实速度场之间的差异。4) 精心选择原型的位置,例如使用k-means算法从原始数据中选择代表性样本作为原型。
🖼️ 关键图片

📊 实验亮点
实验结果表明,PGFM在多个高分辨率数据集上取得了优异的性能。例如,在ImageNet数据集上,PGFM在保证竞争力的性能下,比基于扩散的同类方法效率高7.6倍,模式覆盖率达到78%。此外,PGFM在下游任务上的泛化性能也优于现有的数据集蒸馏方法。
🎯 应用场景
PGFM可应用于各种需要数据集压缩的场景,例如移动设备上的模型训练、边缘计算、联邦学习等。通过将大型数据集蒸馏成小型合成数据集,可以显著降低存储和计算成本,提高模型训练效率,并保护原始数据的隐私。此外,PGFM还可以用于生成对抗样本,提高模型的鲁棒性。
📄 摘要(原文)
Dataset distillation compresses large datasets into compact synthetic sets with comparable performance in training models. Despite recent progress on diffusion-based distillation, this type of method typically depends on heuristic guidance or prototype assignment, which comes with time-consuming sampling and trajectory instability and thus hurts downstream generalization especially under strong control or low IPC. We propose \emph{Path-Guided Flow Matching (PGFM)}, the first flow matching-based framework for generative distillation, which enables fast deterministic synthesis by solving an ODE in a few steps. PGFM conducts flow matching in the latent space of a frozen VAE to learn class-conditional transport from Gaussian noise to data distribution. Particularly, we develop a continuous path-to-prototype guidance algorithm for ODE-consistent path control, which allows trajectories to reliably land on assigned prototypes while preserving diversity and efficiency. Extensive experiments across high-resolution benchmarks demonstrate that PGFM matches or surpasses prior diffusion-based distillation approaches with fewer steps of sampling while delivering competitive performance with remarkably improved efficiency, e.g., 7.6$\times$ more efficient than the diffusion-based counterparts with 78\% mode coverage.