Steering Large Reasoning Models towards Concise Reasoning via Flow Matching
作者: Yawei Li, Benjamin Bergner, Yinghan Zhao, Vihang Prakash Patil, Bei Chen, Cheng Wang
分类: cs.LG, cs.AI, cs.CL
发布日期: 2026-02-05
备注: This paper has been accepted to Transactions on Machine Learning Research (TMLR)
💡 一句话要点
FlowSteer:通过流匹配引导大模型生成更简洁的推理过程
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 大型语言模型 推理效率 流匹配 非线性引导 模型压缩
📋 核心要点
- 大型推理模型输出冗长,降低效率,现有方法基于线性假设,表达能力受限。
- FlowSteer通过流匹配学习非线性变换,对模型推理过程进行更精确的控制。
- 实验表明,FlowSteer在保证任务性能的同时,显著提升了token效率,生成更简洁的推理过程。
📝 摘要(中文)
大型推理模型(LRMs)在复杂推理任务中表现出色,但其效率常因过于冗长的输出而受阻。现有的引导方法试图通过对隐藏层表示应用单一的全局向量来解决这个问题,这种方法基于受限的线性表示假设。本文提出FlowSteer,一种非线性引导方法,它通过学习冗长推理和简洁推理相关分布之间的完整变换,超越了均匀线性偏移。这种变换通过流匹配被学习为一个速度场,从而能够对模型的推理过程进行精确的、输入相关的控制。通过将引导后的表示与简洁推理激活的分布对齐,FlowSteer比线性偏移产生更紧凑的推理。在不同的推理基准测试中,FlowSteer与领先的推理时基线相比,表现出强大的任务性能和token效率。这项工作表明,使用生成技术对完整分布传输进行建模,为控制LRM提供了一个更有效和有原则的基础。
🔬 方法详解
问题定义:大型推理模型(LRMs)在复杂任务中表现出色,但其生成的推理过程往往过于冗长,导致效率低下。现有的引导方法通常假设隐藏层表示具有线性特性,通过施加全局线性偏移来控制模型的推理过程。然而,这种线性假设过于简单,无法充分捕捉复杂推理过程中的非线性关系,限制了引导方法的表达能力和控制精度。
核心思路:FlowSteer的核心思想是利用流匹配(Flow Matching)学习冗长推理和简洁推理的隐藏层表示之间的非线性变换。通过将冗长推理的表示逐步转换为简洁推理的表示,FlowSteer能够更精确地控制模型的推理过程,生成更简洁的推理结果。这种方法不再局限于线性偏移,而是学习一个完整的分布变换,从而能够更好地捕捉复杂推理过程中的非线性关系。
技术框架:FlowSteer的整体框架包括以下几个主要步骤:1) 收集冗长推理和简洁推理的激活数据;2) 使用流匹配算法学习一个速度场,该速度场描述了从冗长推理表示到简洁推理表示的连续变换;3) 在推理时,利用学习到的速度场对模型的隐藏层表示进行引导,使其逐步向简洁推理的表示靠近。这个过程可以看作是在模型的推理过程中施加一个非线性的“力”,引导模型生成更简洁的推理路径。
关键创新:FlowSteer的关键创新在于使用流匹配来学习冗长推理和简洁推理之间的非线性变换。与现有的线性引导方法相比,FlowSteer能够更好地捕捉复杂推理过程中的非线性关系,从而实现更精确的控制。此外,FlowSteer通过学习一个速度场,实现了输入相关的引导,即引导的方向和强度可以根据不同的输入进行调整,从而更好地适应不同的推理场景。
关键设计:FlowSteer的关键设计包括:1) 使用条件流匹配(Conditional Flow Matching)来学习速度场,条件变量可以是输入文本或模型的隐藏层表示;2) 使用神经网络来参数化速度场,网络的结构可以根据具体的任务进行调整;3) 在训练过程中,使用正则化项来约束速度场的平滑性,避免过拟合;4) 在推理时,可以使用不同的积分方法来求解速度场,例如欧拉方法或龙格-库塔方法。
🖼️ 关键图片

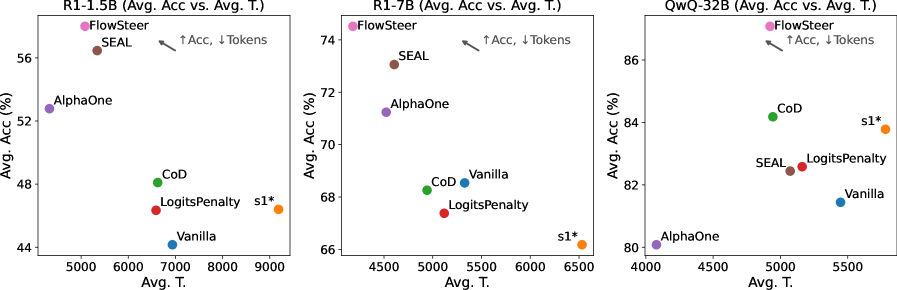
📊 实验亮点
FlowSteer在多个推理基准测试中取得了显著的成果。例如,在某些任务上,FlowSteer在保持甚至提高任务性能的同时,将token数量减少了20%-30%。与现有的线性引导方法相比,FlowSteer在token效率和任务性能方面均取得了显著的提升,证明了其有效性和优越性。
🎯 应用场景
FlowSteer具有广泛的应用前景,可以应用于各种需要高效推理的大型语言模型,例如对话系统、问答系统、代码生成等。通过减少冗余信息,提高推理效率,FlowSteer可以显著提升这些系统的用户体验和性能。此外,FlowSteer还可以用于模型压缩和知识蒸馏,通过引导大型模型生成更简洁的推理过程,从而训练出更小、更快的模型。
📄 摘要(原文)
Large Reasoning Models (LRMs) excel at complex reasoning tasks, but their efficiency is often hampered by overly verbose outputs. Prior steering methods attempt to address this issue by applying a single, global vector to hidden representations -- an approach grounded in the restrictive linear representation hypothesis. In this work, we introduce FlowSteer, a nonlinear steering method that goes beyond uniform linear shifts by learning a complete transformation between the distributions associated with verbose and concise reasoning. This transformation is learned via Flow Matching as a velocity field, enabling precise, input-dependent control over the model's reasoning process. By aligning steered representations with the distribution of concise-reasoning activations, FlowSteer yields more compact reasoning than the linear shifts. Across diverse reasoning benchmarks, FlowSteer demonstrates strong task performance and token efficiency compared to leading inference-time baselines. Our work demonstrates that modeling the full distributional transport with generative techniques offers a more effective and principled foundation for controlling LRMs.