Accelerated Sequential Flow Matching: A Bayesian Filtering Perspective
作者: Yinan Huang, Hans Hao-Hsun Hsu, Junran Wang, Bo Dai, Pan Li
分类: cs.LG
发布日期: 2026-02-05
💡 一句话要点
提出基于贝叶斯滤波的加速序列流匹配方法,提升实时序列预测效率
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 序列预测 流匹配模型 贝叶斯滤波 实时推理 动态系统
📋 核心要点
- 传统扩散模型和流匹配模型在实时序列预测中存在推理延迟高、易造成系统积压的问题。
- 论文提出序列流匹配框架,将流式推理视为学习概率流,并与贝叶斯信念更新对齐。
- 实验表明,该方法在多种任务中达到与全步扩散模型相当的性能,但采样速度更快。
📝 摘要(中文)
本文提出序列流匹配(Sequential Flow Matching)框架,用于解决随机动态系统中流式观测的序列预测问题。该问题中固有的不确定性会导致多种合理的未来轨迹。虽然扩散模型和流匹配模型能够建模复杂的多模态轨迹,但它们在实时流环境中的部署通常依赖于从非信息初始分布重复采样,导致显著的推理延迟和潜在的系统积压。本文将流式推理视为学习概率流,该概率流将预测分布从一个时间步传递到下一个时间步,从而与贝叶斯信念更新的递归结构自然对齐。理论证明,从先前的后验初始化生成提供了一种原则性的热启动,与朴素的重采样相比,可以加速采样。在各种预测、决策和状态估计任务中,该方法实现了与全步扩散模型相当的性能,同时仅需要一次或极少的采样步骤,因此采样速度更快。这表明通过贝叶斯滤波构建序列推理为基于流的模型的有效实时部署提供了一个新的、原则性的视角。
🔬 方法详解
问题定义:论文旨在解决实时流数据场景下的序列预测问题。现有方法,特别是基于扩散模型和流匹配模型的方法,在处理此类问题时,通常需要从一个非信息量的初始分布进行重复采样,这导致了显著的推理延迟,并且可能造成系统瓶颈。因此,如何在保证预测精度的前提下,降低采样次数,加速推理过程,是本文要解决的核心问题。
核心思路:论文的核心思路是将序列预测问题置于贝叶斯滤波的框架下,将流式推理过程建模为一个概率流,该概率流负责将预测分布从一个时间步传递到下一个时间步。关键在于利用前一个时间步的后验分布作为当前时间步生成的初始化,从而实现“热启动”,避免从完全随机的噪声开始采样,从而加速采样过程。
技术框架:整体框架基于流匹配模型,但引入了贝叶斯滤波的递归更新机制。具体来说,在每个时间步,首先利用前一个时间步的后验分布作为初始分布,通过流匹配模型生成当前时间步的预测分布。然后,结合当前时间步的观测数据,利用贝叶斯公式更新后验分布,用于下一个时间步的预测。整个过程可以看作是一个概率流的迭代更新过程,其中流匹配模型负责概率分布的演化,贝叶斯滤波负责根据观测数据进行校正。
关键创新:最重要的创新点在于将贝叶斯滤波的递归结构与流匹配模型的生成能力相结合,提出了一种新的序列流匹配框架。与传统的流匹配模型相比,该方法利用了序列数据的时间依赖性,通过前一个时间步的后验信息来指导当前时间步的生成,从而避免了从完全随机的噪声开始采样,显著提高了采样效率。
关键设计:关键设计包括:1) 如何选择合适的流匹配模型作为概率流的演化器;2) 如何有效地利用前一个时间步的后验分布作为当前时间步的初始化;3) 如何在贝叶斯更新过程中融合观测数据。具体实现细节可能包括选择特定的神经网络结构来实现流匹配模型,设计合适的损失函数来训练模型,以及采用合适的贝叶斯滤波算法(如卡尔曼滤波或粒子滤波)进行后验更新。论文中可能还涉及一些超参数的设置,例如学习率、批量大小等。
🖼️ 关键图片

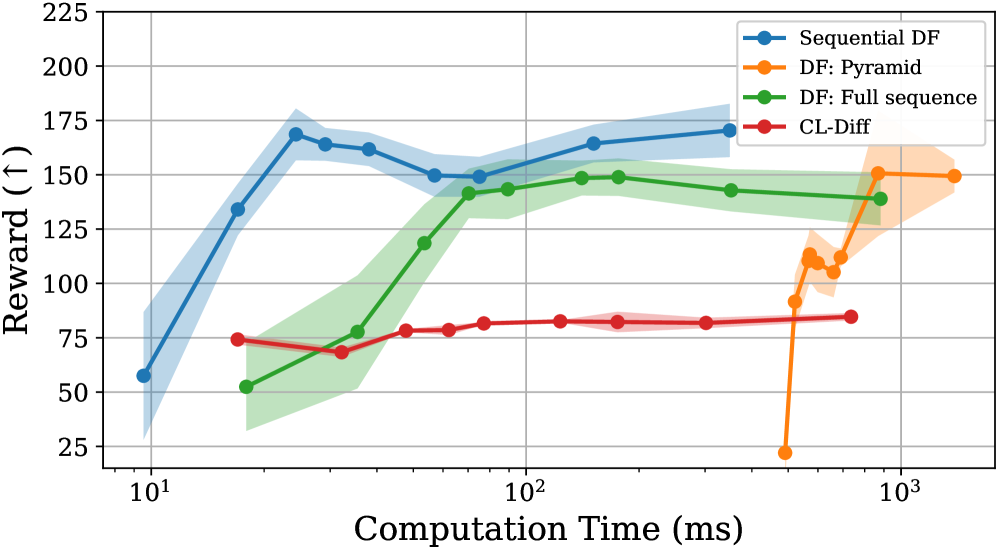
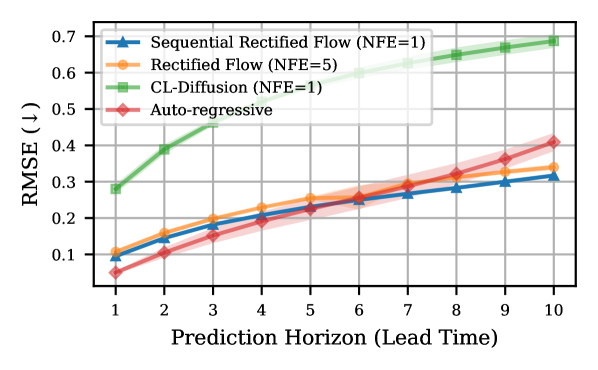
📊 实验亮点
实验结果表明,所提出的序列流匹配方法在各种预测、决策和状态估计任务中,实现了与全步扩散模型相当的性能,但仅需要一次或极少的采样步骤,因此采样速度更快。具体的性能提升幅度可能取决于具体的任务和数据集,但总体趋势是显著降低了推理延迟,提高了实时性。
🎯 应用场景
该研究成果可广泛应用于需要实时序列预测的领域,如自动驾驶(预测车辆轨迹)、机器人导航(预测机器人运动轨迹)、金融预测(预测股票价格)和天气预报等。通过加速序列预测过程,可以提高系统的响应速度和决策效率,从而提升用户体验和系统性能。未来,该方法有望应用于更复杂的动态系统建模和控制问题。
📄 摘要(原文)
Sequential prediction from streaming observations is a fundamental problem in stochastic dynamical systems, where inherent uncertainty often leads to multiple plausible futures. While diffusion and flow-matching models are capable of modeling complex, multi-modal trajectories, their deployment in real-time streaming environments typically relies on repeated sampling from a non-informative initial distribution, incurring substantial inference latency and potential system backlogs. In this work, we introduce Sequential Flow Matching, a principled framework grounded in Bayesian filtering. By treating streaming inference as learning a probability flow that transports the predictive distribution from one time step to the next, our approach naturally aligns with the recursive structure of Bayesian belief updates. We provide theoretical justification that initializing generation from the previous posterior offers a principled warm start that can accelerate sampling compared to naïve re-sampling. Across a wide range of forecasting, decision-making and state estimation tasks, our method achieves performance competitive with full-step diffusion while requiring only one or very few sampling steps, therefore with faster sampling. It suggests that framing sequential inference via Bayesian filtering provides a new and principled perspective towards efficient real-time deployment of flow-based models.