Back to Basics: Revisiting Exploration in Reinforcement Learning for LLM Reasoning via Generative Probabilities
作者: Pengyi Li, Elizaveta Goncharova, Andrey Kuznetsov, Ivan Oseledets
分类: cs.LG, cs.CL
发布日期: 2026-02-05
💡 一句话要点
提出ARM机制,通过生成概率改进LLM推理中的强化学习探索,提升多样性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 推理 探索与利用 生成概率 优势重加权 多样性 熵
📋 核心要点
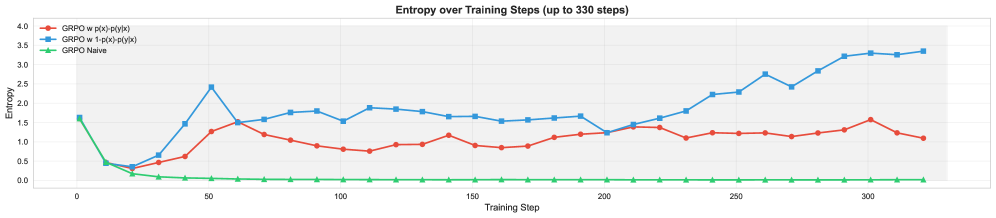
- 现有RLVR方法(如GRPO)易收敛到低熵策略,导致LLM推理多样性不足,出现模式崩溃。
- 提出优势重加权机制(ARM),通过Prompt Perplexity和Answer Confidence动态调整奖励信号,平衡探索与利用。
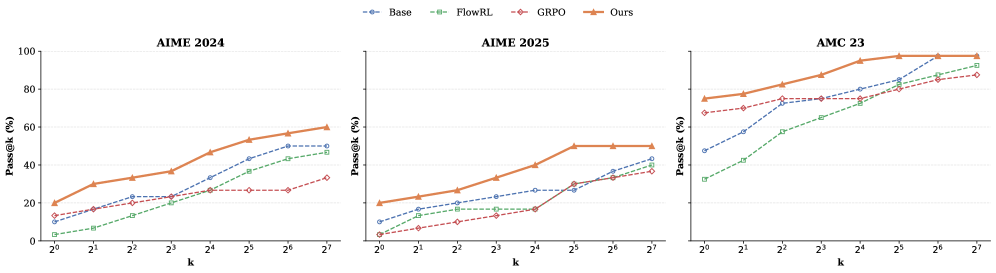
- 实验表明,ARM显著提升生成多样性和响应熵,在Qwen2.5-7B模型上Pass@32指标提升13.9%。
📝 摘要(中文)
基于可验证奖励的强化学习(RLVR)已成为增强大型语言模型(LLM)推理能力的不可或缺的范例。然而,诸如Group Relative Policy Optimization (GRPO)等标准策略优化方法通常收敛到低熵策略,导致严重的模式崩溃和有限的输出多样性。我们从抽样概率动态的角度分析了这个问题,发现标准目标不成比例地强化了最高概率的路径,从而抑制了有效的替代推理链。为了解决这个问题,我们提出了一种新颖的优势重加权机制(ARM),旨在平衡所有正确答案的置信度。通过将Prompt Perplexity和Answer Confidence纳入优势估计,我们的方法动态地重塑奖励信号,以衰减过度自信的推理路径的梯度更新,同时将概率质量重新分配到未充分探索的正确解决方案。经验结果表明,我们的方法显著提高了生成多样性和响应熵,同时保持了有竞争力的准确性,有效地实现了推理任务中探索和利用之间的卓越权衡。在Qwen2.5和DeepSeek模型上进行的数学和编码基准测试表明,ProGRPO显著缓解了熵崩溃。具体而言,在Qwen2.5-7B上,我们的方法在Pass@1上优于GRPO 5.7%,尤其是在Pass@32上优于GRPO 13.9%,突出了其生成多样化正确推理路径的卓越能力。
🔬 方法详解
问题定义:现有基于强化学习的LLM推理方法,如GRPO,存在探索不足的问题。它们倾向于过分强化高概率的推理路径,导致模型输出的答案缺乏多样性,容易陷入局部最优解,无法充分探索所有可能的正确推理路径。这种模式崩溃限制了LLM解决复杂问题的能力。
核心思路:论文的核心思路是通过重新加权优势函数,鼓励模型探索更多样化的推理路径。具体来说,通过降低模型对高置信度、但可能并非最优的推理路径的奖励,同时增加对低置信度、但可能是正确的推理路径的奖励,从而平衡探索和利用。这种方法旨在使模型能够更全面地搜索解空间,找到更多样化的正确答案。
技术框架:整体框架基于标准的RLVR流程,主要包括以下几个阶段:1) 使用LLM生成推理路径;2) 使用可验证的奖励函数评估推理路径的正确性;3) 使用ARM机制重新加权优势函数;4) 使用重新加权的优势函数更新LLM的策略。ARM机制是该框架的核心组成部分,它负责动态调整奖励信号,引导模型进行更有效的探索。
关键创新:最重要的技术创新点在于ARM机制,它通过Prompt Perplexity和Answer Confidence来动态调整优势函数。与传统方法不同,ARM不仅考虑了答案的正确性,还考虑了生成答案的置信度和prompt的复杂度。这种方法能够更准确地评估推理路径的价值,从而更有效地引导模型进行探索。
关键设计:ARM机制的关键设计包括:1) 使用Prompt Perplexity来衡量prompt的复杂度,复杂度高的prompt需要更多的探索;2) 使用Answer Confidence来衡量模型对答案的置信度,置信度高的答案需要降低奖励;3) 将Prompt Perplexity和Answer Confidence结合起来,动态调整优势函数。具体的公式细节在论文中有详细描述,包括如何将这两个指标融入到优势函数的计算中,以及如何调整权重以达到最佳的探索效果。
🖼️ 关键图片

📊 实验亮点
实验结果表明,提出的ARM机制能够显著提升LLM推理的多样性和准确性。在Qwen2.5-7B模型上,使用ARM机制后,Pass@1指标提升了5.7%,Pass@32指标提升了13.9%。这些结果表明,ARM机制能够有效地缓解熵崩溃问题,并生成更多样化的正确推理路径。此外,该方法在DeepSeek模型上也取得了类似的效果,验证了其泛化能力。
🎯 应用场景
该研究成果可应用于各种需要LLM进行复杂推理的场景,例如数学问题求解、代码生成、知识问答等。通过提升LLM推理的多样性和准确性,可以提高其在这些领域的应用效果,并为开发更智能、更可靠的AI系统奠定基础。此外,该方法还可以推广到其他基于强化学习的LLM训练任务中,具有广泛的应用前景。
📄 摘要(原文)
Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as an indispensable paradigm for enhancing reasoning in Large Language Models (LLMs). However, standard policy optimization methods, such as Group Relative Policy Optimization (GRPO), often converge to low-entropy policies, leading to severe mode collapse and limited output diversity. We analyze this issue from the perspective of sampling probability dynamics, identifying that the standard objective disproportionately reinforces the highest-likelihood paths, thereby suppressing valid alternative reasoning chains. To address this, we propose a novel Advantage Re-weighting Mechanism (ARM) designed to equilibrate the confidence levels across all correct responses. By incorporating Prompt Perplexity and Answer Confidence into the advantage estimation, our method dynamically reshapes the reward signal to attenuate the gradient updates of over-confident reasoning paths, while redistributing probability mass toward under-explored correct solutions. Empirical results demonstrate that our approach significantly enhances generative diversity and response entropy while maintaining competitive accuracy, effectively achieving a superior trade-off between exploration and exploitation in reasoning tasks. Empirical results on Qwen2.5 and DeepSeek models across mathematical and coding benchmarks show that ProGRPO significantly mitigates entropy collapse. Specifically, on Qwen2.5-7B, our method outperforms GRPO by 5.7% in Pass@1 and, notably, by 13.9% in Pass@32, highlighting its superior capability in generating diverse correct reasoning paths.