TADS: Task-Aware Data Selection for Multi-Task Multimodal Pre-Training
作者: Guanjie Cheng, Boyi Li, Lingyu Sun, Mengying Zhu, Yangyang Wu, Xinkui Zhao, Shuiguang Deng
分类: cs.LG
发布日期: 2026-02-05
💡 一句话要点
提出TADS,用于多任务多模态预训练的任务感知数据选择。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态预训练 数据选择 任务感知 元学习 数据质量 分布多样性
📋 核心要点
- 现有网络爬取的多模态数据质量差,传统数据选择方法存在偏差或任务无关性,导致预训练效率低。
- TADS框架将数据内在质量、任务相关性和分布多样性整合到可学习的价值函数中,实现任务感知的数据选择。
- 实验表明,TADS仅使用36%的数据,在多个下游任务上超越基线,显著提升了数据效率和零样本性能。
📝 摘要(中文)
大规模多模态预训练模型(如CLIP)严重依赖高质量的训练数据。然而,原始的网络爬取数据集通常包含噪声、错位和冗余数据,导致训练效率低下和泛化能力欠佳。现有的数据选择方法要么基于启发式,存在偏差和多样性不足的问题,要么是数据驱动但任务无关的,无法针对多任务场景进行优化。为了解决这些问题,我们提出了一种新的多任务多模态预训练框架TADS(任务感知数据选择),它将内在质量、任务相关性和分布多样性集成到一个可学习的价值函数中。TADS采用包含单模态和跨模态算子的综合质量评估系统,通过可解释的相似性向量量化任务相关性,并通过基于聚类的加权优化多样性。一种反馈驱动的元学习机制根据代理模型在多个下游任务上的表现自适应地优化选择策略。在CC12M上的实验表明,TADS仅使用36%的数据,在ImageNet、CIFAR-100、MS-COCO和Flickr30K等基准测试中实现了卓越的零样本性能,并且平均优于基线方法1.0%。这突显了TADS通过管理一个高效用子集,在相同的计算约束下产生更高的性能上限,从而显著提高了数据效率。
🔬 方法详解
问题定义:论文旨在解决多模态预训练中,由于训练数据集中存在大量噪声、错位和冗余数据,导致模型训练效率低下和泛化能力不足的问题。现有数据选择方法要么依赖启发式规则,容易引入偏差且缺乏多样性,要么是任务无关的,无法针对多任务场景进行优化。
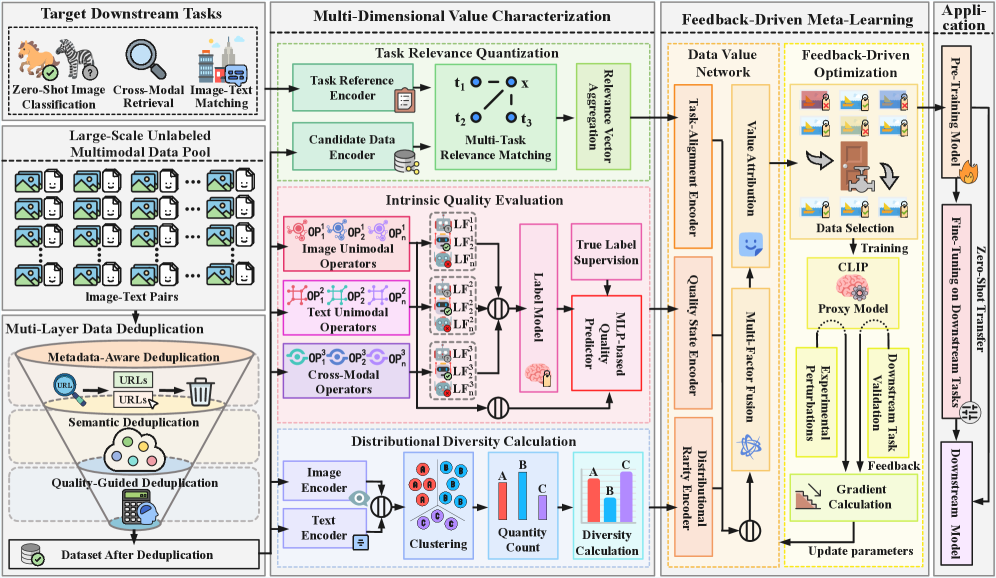
核心思路:TADS的核心思路是设计一个可学习的价值函数,该函数能够综合考虑数据的内在质量、与特定任务的相关性以及数据集的分布多样性。通过学习这个价值函数,TADS能够选择一个高质量、与任务相关且具有代表性的数据子集,从而提高多模态预训练的效率和性能。
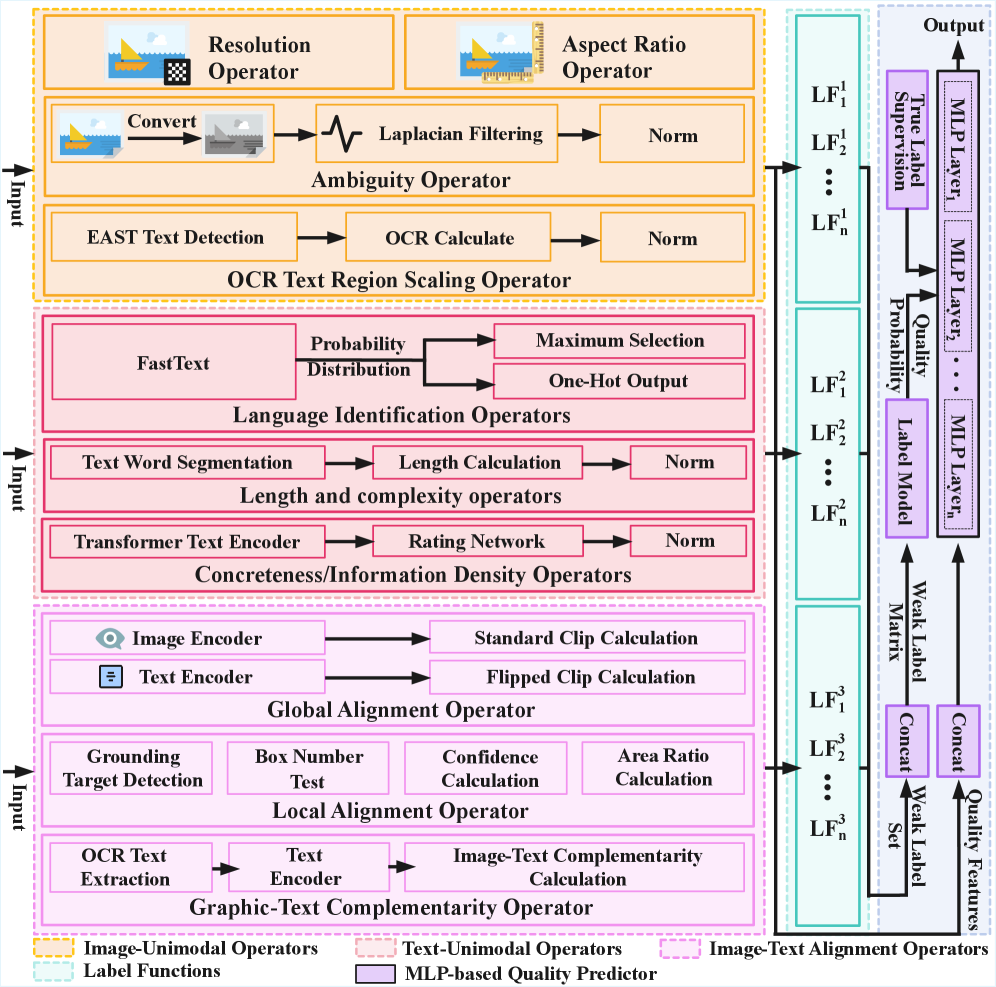
技术框架:TADS框架主要包含以下几个模块:1) 质量评估模块:使用单模态和跨模态算子对数据进行质量评估。2) 任务相关性量化模块:通过可解释的相似性向量来衡量数据与特定任务的相关性。3) 多样性优化模块:采用基于聚类的加权方法来保证选择的数据集具有良好的分布多样性。4) 元学习优化模块:利用反馈驱动的元学习机制,根据代理模型在下游任务上的表现,自适应地优化数据选择策略。
关键创新:TADS的关键创新在于将数据选择问题转化为一个可学习的优化问题,并设计了一个综合考虑数据质量、任务相关性和分布多样性的价值函数。与传统方法相比,TADS能够更有效地选择对多任务预训练有益的数据,从而提高模型的泛化能力和训练效率。此外,反馈驱动的元学习机制能够自适应地调整数据选择策略,进一步提升模型的性能。
关键设计:在质量评估模块中,论文可能使用了预训练的视觉和语言模型来提取特征,并设计了特定的损失函数来衡量数据的质量。在任务相关性量化模块中,可能使用了余弦相似度等方法来计算数据与任务描述之间的相似性。在多样性优化模块中,可能使用了k-means等聚类算法来将数据集划分为不同的簇,并根据簇的大小和重要性进行加权。元学习优化模块可能采用了基于梯度下降的优化算法,根据下游任务的性能反馈来调整价值函数的参数。
🖼️ 关键图片

📊 实验亮点
实验结果表明,TADS在CC12M数据集上仅使用36%的数据,就在ImageNet、CIFAR-100、MS-COCO和Flickr30K等基准测试中取得了优于基线方法的零样本性能,平均提升1.0%。这表明TADS能够有效地选择高质量的数据子集,从而在相同的计算资源下获得更高的性能。
🎯 应用场景
TADS可应用于各种多模态预训练场景,例如图像-文本检索、视觉问答、图像描述生成等。通过选择高质量、任务相关的数据,可以显著提高这些任务的性能和效率。该研究对于降低多模态预训练的数据需求、提升模型泛化能力具有重要意义,并可能推动相关领域的发展。
📄 摘要(原文)
Large-scale multimodal pre-trained models like CLIP rely heavily on high-quality training data, yet raw web-crawled datasets are often noisy, misaligned, and redundant, leading to inefficient training and suboptimal generalization. Existing data selection methods are either heuristic-based, suffering from bias and limited diversity, or data-driven but task-agnostic, failing to optimize for multi-task scenarios. To address these gaps, we introduce TADS (Task-Aware Data Selection), a novel framework for multi-task multimodal pre-training that integrates Intrinsic Quality, Task Relevance, and Distributional Diversity into a learnable value function. TADS employs a comprehensive quality assessment system with unimodal and cross-modal operators, quantifies task relevance via interpretable similarity vectors, and optimizes diversity through cluster-based weighting. A feedback-driven meta-learning mechanism adaptively refines the selection strategy based on proxy model performance across multiple downstream tasks. Experiments on CC12M demonstrate that TADS achieves superior zero-shot performance on benchmarks like ImageNet, CIFAR-100, MS-COCO, and Flickr30K, using only 36% of the data while outperforming baselines by an average of 1.0%. This highlights that TADS significantly enhances data efficiency by curating a high-utility subset that yields a much higher performance ceiling within the same computational constraints.