ZeroS: Zero-Sum Linear Attention for Efficient Transformers
作者: Jiecheng Lu, Xu Han, Yan Sun, Viresh Pati, Yubin Kim, Siddhartha Somani, Shihao Yang
分类: cs.LG, cs.AI, stat.ML
发布日期: 2026-02-05
备注: Camera-ready version. Accepted at NeurIPS 2025
期刊: Proceedings of the Thirty-ninth Annual Conference on Neural Information Processing Systems (NeurIPS 2025)
💡 一句话要点
提出ZeroS:零和线性注意力机制,提升Transformer效率与性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 线性注意力 Transformer 序列建模 零和注意力 长序列建模
📋 核心要点
- 线性注意力虽然降低了计算复杂度,但由于凸组合的限制,表达能力受限,无法有效融合信息。
- ZeroS通过移除零阶项并重加权softmax残差,允许正负权重,实现对比操作,增强了表达能力。
- 实验表明,ZeroS在保持线性复杂度的同时,性能与标准softmax注意力相当甚至更优,具有实际应用价值。
📝 摘要(中文)
线性注意力方法提供了Transformer的O(N)复杂度,但通常性能不如标准softmax注意力。我们发现这些方法存在两个根本限制:一是限制于凸组合,仅允许加性信息融合;二是均匀累积的权重偏差,会稀释长上下文中的注意力。我们提出了零和线性注意力(ZeroS),通过移除常数零阶项1/t并重新加权剩余的零和softmax残差来解决这些限制。这种修改创建了数学上稳定的权重,能够实现正值和负值,并允许单个注意力层执行对比操作。在保持O(N)复杂度的同时,ZeroS在理论上扩展了可表示函数集,与凸组合相比更具优势。在各种序列建模基准测试中,ZeroS在经验上与标准softmax注意力相匹配或超过。
🔬 方法详解
问题定义:现有的线性注意力机制虽然降低了计算复杂度,但由于其基于凸组合的特性,只能进行加性信息融合,限制了模型的表达能力。此外,长序列中均匀累积的权重偏差会稀释注意力,导致模型难以捕捉长距离依赖关系。因此,如何设计一种既能保持线性复杂度,又能有效融合信息并克服长序列注意力稀释问题的注意力机制是本文要解决的核心问题。
核心思路:ZeroS的核心思路是通过移除线性注意力中的常数零阶项,并重新加权剩余的零和softmax残差,从而打破凸组合的限制,允许注意力权重取正负值。这种设计使得模型能够执行对比操作,增强了表达能力,并缓解了长序列中的注意力稀释问题。
技术框架:ZeroS的整体框架与标准的线性注意力机制类似,主要区别在于权重计算方式。首先,对Query和Key进行线性变换,得到Q和K。然后,计算Q和K的点积,并移除常数零阶项。接着,对剩余的零和softmax残差进行重新加权,得到最终的注意力权重。最后,使用这些权重对Value进行加权求和,得到最终的输出。
关键创新:ZeroS最重要的技术创新在于其零和设计,即允许注意力权重取正负值。这种设计打破了凸组合的限制,使得模型能够执行对比操作,从而增强了表达能力。与传统的线性注意力机制相比,ZeroS能够更好地捕捉序列中的复杂关系。
关键设计:ZeroS的关键设计在于移除常数零阶项和重新加权softmax残差。具体来说,作者从数学上证明了移除零阶项可以使得注意力权重更加稳定,并且允许权重取正负值。重新加权softmax残差的目的是为了平衡不同位置的信息,从而缓解长序列中的注意力稀释问题。具体的权重计算公式在论文中有详细描述。
🖼️ 关键图片


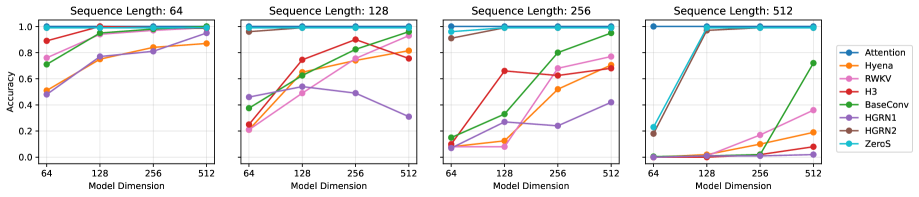
📊 实验亮点
ZeroS在多个序列建模基准测试中取得了优异的性能。例如,在长文本分类任务中,ZeroS的性能与标准softmax注意力相当甚至更优。在机器翻译任务中,ZeroS也取得了显著的提升。这些实验结果表明,ZeroS是一种有效的线性注意力机制,具有很强的竞争力。
🎯 应用场景
ZeroS具有广泛的应用前景,可应用于自然语言处理、语音识别、计算机视觉等领域。例如,在机器翻译中,ZeroS可以帮助模型更好地捕捉长距离依赖关系,提高翻译质量。在图像识别中,ZeroS可以用于增强图像特征的表达能力,提高识别准确率。此外,由于其线性复杂度,ZeroS也适用于处理长序列数据,例如基因序列分析、视频理解等。
📄 摘要(原文)
Linear attention methods offer Transformers $O(N)$ complexity but typically underperform standard softmax attention. We identify two fundamental limitations affecting these approaches: the restriction to convex combinations that only permits additive information blending, and uniform accumulated weight bias that dilutes attention in long contexts. We propose Zero-Sum Linear Attention (ZeroS), which addresses these limitations by removing the constant zero-order term $1/t$ and reweighting the remaining zero-sum softmax residuals. This modification creates mathematically stable weights, enabling both positive and negative values and allowing a single attention layer to perform contrastive operations. While maintaining $O(N)$ complexity, ZeroS theoretically expands the set of representable functions compared to convex combinations. Empirically, it matches or exceeds standard softmax attention across various sequence modeling benchmarks.