Disentangled Representation Learning via Flow Matching
作者: Jinjin Chi, Taoping Liu, Mengtao Yin, Ximing Li, Yongcheng Jing, Dacheng Tao
分类: cs.LG
发布日期: 2026-02-05
💡 一句话要点
提出基于Flow Matching的解耦表示学习框架,提升语义对齐和解耦性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 解耦表示学习 Flow Matching 生成模型 语义对齐 正交性正则化
📋 核心要点
- 现有基于扩散的解耦表示学习方法依赖归纳偏置,语义对齐效果不佳。
- 论文提出基于Flow Matching的框架,学习因素条件流,实现解耦表示。
- 引入非重叠正则化器,抑制因素间干扰,实验表明解耦性能和样本质量均有提升。
📝 摘要(中文)
解耦表示学习旨在捕获观测数据的潜在解释因素,从而对数据生成过程进行有原则的理解。生成建模的最新进展为学习此类表示引入了新的范例。然而,现有的基于扩散的方法通过归纳偏置来鼓励因素独立性,但通常缺乏强大的语义对齐。本文提出了一种基于Flow Matching的解耦表示学习框架,该框架将解耦视为在紧凑潜在空间中学习因素条件流。为了强制执行显式的语义对齐,我们引入了一种非重叠(正交性)正则化器,以抑制跨因素干扰并减少因素之间的信息泄漏。在多个数据集上的大量实验表明,相对于代表性的基线方法,该方法具有一致的改进,从而产生更高的解耦分数以及改进的可控性和样本保真度。
🔬 方法详解
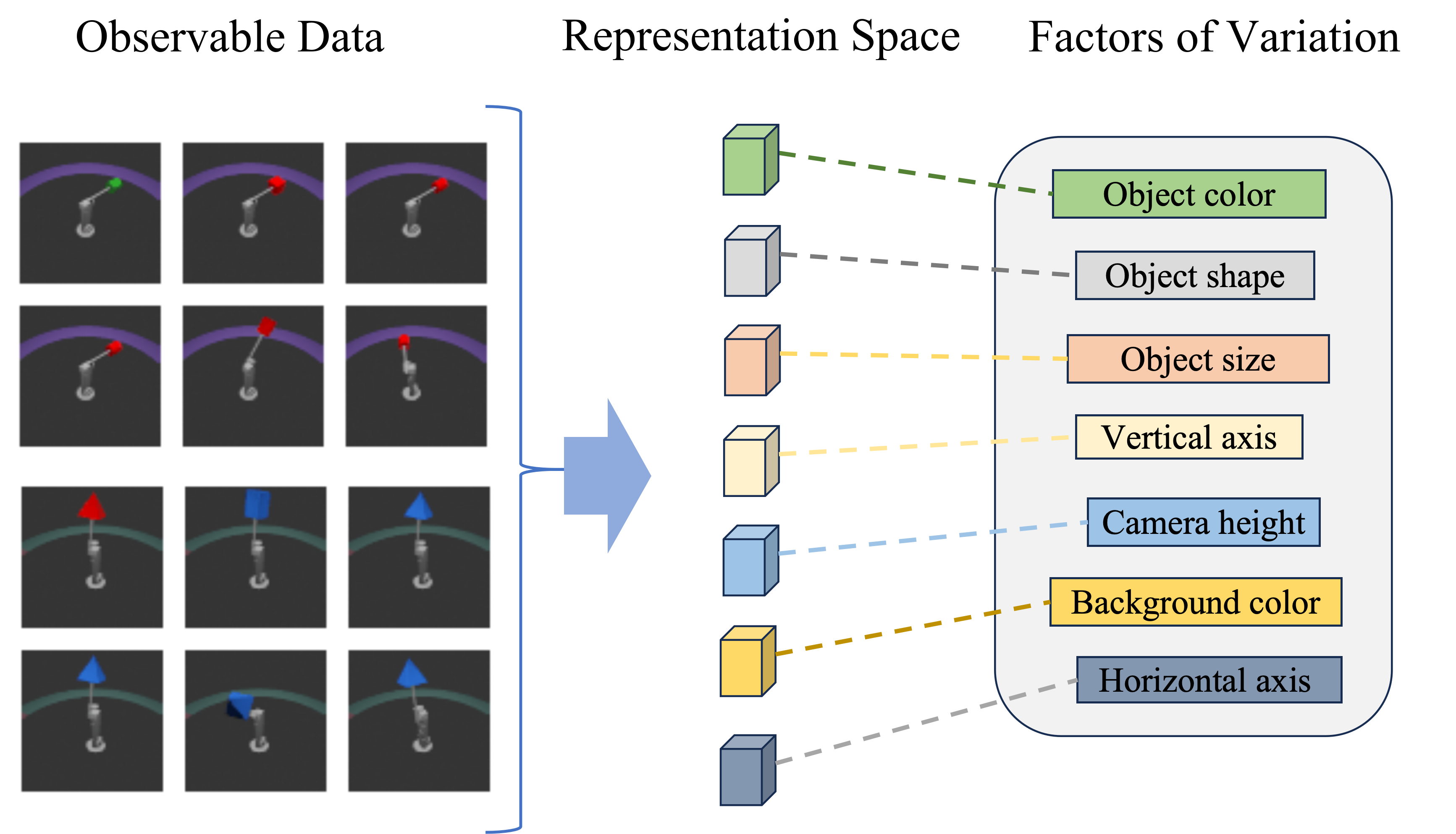
问题定义:解耦表示学习旨在从观测数据中提取独立的、可解释的潜在因素。现有方法,特别是基于扩散模型的方法,虽然尝试通过归纳偏置来促进因素之间的独立性,但往往在语义对齐方面表现不足,导致学习到的潜在因素与实际语义概念的对应关系较弱。此外,因素间的信息泄露也会降低解耦效果。
核心思路:论文的核心思路是将解耦表示学习问题转化为学习因素条件流的问题。通过学习从一个简单分布(如高斯分布)到数据分布的连续变换,并以潜在因素作为条件,可以显式地控制数据生成过程。Flow Matching框架提供了一种有效的方式来学习这种连续变换,并且可以灵活地集成额外的约束来提升解耦性能。
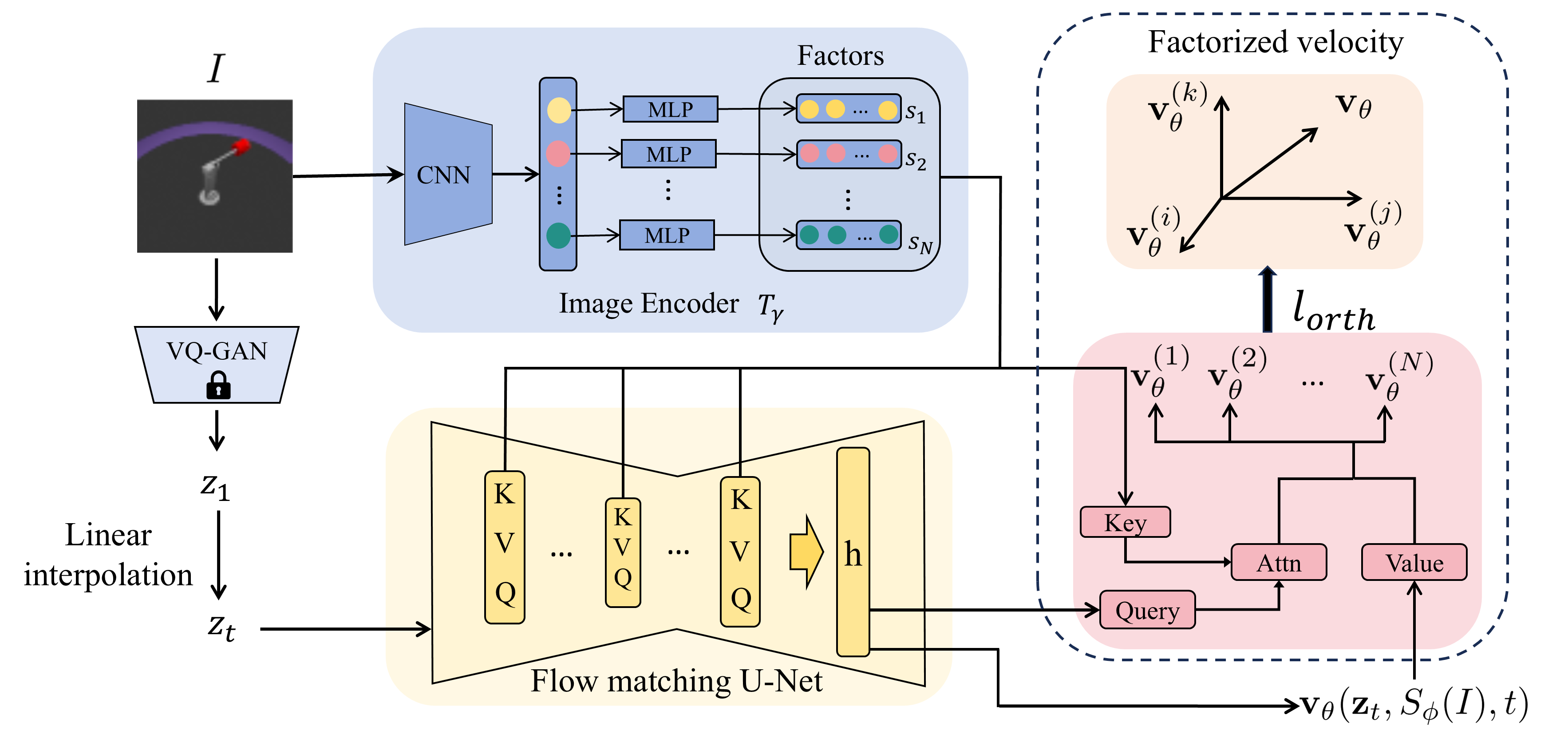
技术框架:该框架包含以下主要模块:1) 编码器:将输入数据映射到潜在空间;2) Flow Matching模块:学习潜在空间中的因素条件流,将一个简单分布变换到解耦的潜在表示;3) 解码器:将解耦的潜在表示映射回数据空间。整体流程是:首先,使用编码器将输入数据编码到潜在空间。然后,Flow Matching模块根据潜在因素的条件,对潜在表示进行变换,使其具有解耦的特性。最后,使用解码器将解耦的潜在表示解码回数据空间。
关键创新:最重要的技术创新点在于将Flow Matching框架应用于解耦表示学习,并引入了非重叠(正交性)正则化器。Flow Matching提供了一种学习连续变换的有效方法,而正交性正则化器则显式地抑制了跨因素的干扰,减少了信息泄露,从而提升了解耦性能和语义对齐。与现有方法相比,该方法不需要复杂的对抗训练或特定的网络结构设计,更加简洁和易于实现。
关键设计:关键设计包括:1) Flow Matching模块的具体实现,例如使用神经网络来参数化向量场;2) 非重叠正则化器的具体形式,例如计算不同因素对应潜在表示之间的相关性,并惩罚高相关性;3) 损失函数的设计,通常包括Flow Matching损失、正交性正则化损失以及重构损失。具体的参数设置需要根据数据集和任务进行调整。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在多个数据集上均优于代表性的基线方法,包括在解耦指标(如Modularity、DCI)上取得了显著提升。此外,该方法还提升了生成样本的质量和可控性,例如可以独立地控制不同潜在因素来生成具有特定属性的图像。具体性能数据需要在论文中查找。
🎯 应用场景
该研究成果可应用于图像生成、图像编辑、视频理解等领域。例如,在图像生成中,可以控制不同潜在因素来生成具有特定属性的图像;在图像编辑中,可以独立地修改图像的某个属性,而不影响其他属性;在视频理解中,可以提取视频中不同因素(如背景、人物、动作)的解耦表示,从而更好地理解视频内容。该研究有助于提升AI系统的可解释性和可控性。
📄 摘要(原文)
Disentangled representation learning aims to capture the underlying explanatory factors of observed data, enabling a principled understanding of the data-generating process. Recent advances in generative modeling have introduced new paradigms for learning such representations. However, existing diffusion-based methods encourage factor independence via inductive biases, yet frequently lack strong semantic alignment. In this work, we propose a flow matching-based framework for disentangled representation learning, which casts disentanglement as learning factor-conditioned flows in a compact latent space. To enforce explicit semantic alignment, we introduce a non-overlap (orthogonality) regularizer that suppresses cross-factor interference and reduces information leakage between factors. Extensive experiments across multiple datasets demonstrate consistent improvements over representative baselines, yielding higher disentanglement scores as well as improved controllability and sample fidelity.