Double-P: Hierarchical Top-P Sparse Attention for Long-Context LLMs
作者: Wentao Ni, Kangqi Zhang, Zhongming Yu, Oren Nelson, Mingu Lee, Hong Cai, Fatih Porikli, Jongryool Kim, Zhijian Liu, Jishen Zhao
分类: cs.LG, cs.AI
发布日期: 2026-02-05
💡 一句话要点
提出Double-P分层Top-P稀疏注意力,加速长文本LLM推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本LLM 稀疏注意力 Top-P采样 分层注意力 推理加速
📋 核心要点
- 长文本LLM推理面临注意力计算瓶颈,现有固定预算稀疏注意力方法无法适应异构注意力分布。
- Double-P采用分层Top-P稀疏注意力,先聚类粗略估计,再token级精细计算,优化精度、开销和成本。
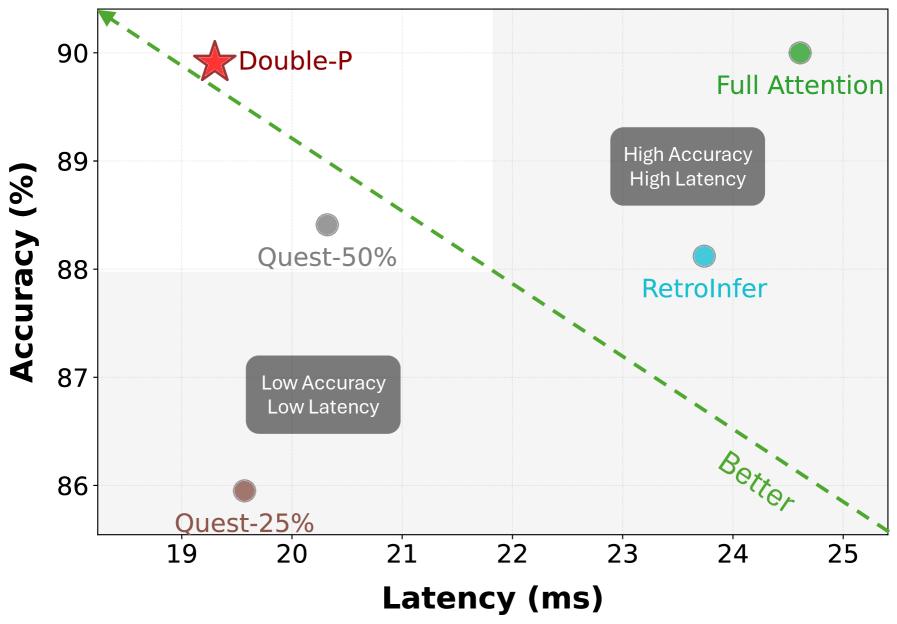
- 实验表明,Double-P在长文本任务上精度损失小,注意力计算开销降低1.8倍,解码速度提升1.3倍。
📝 摘要(中文)
随着长上下文推理在大语言模型(LLM)中变得至关重要,对不断增长的键值缓存的注意力机制成为主要的解码瓶颈,这促使人们研究用于可扩展推理的稀疏注意力。固定预算的top-k稀疏注意力无法适应不同头和层中异构的注意力分布,而top-p稀疏注意力直接保留注意力质量并提供更强的准确性保证。然而,现有的top-p方法未能联合优化top-p准确性、选择开销和稀疏注意力成本,这限制了它们的整体效率。我们提出了Double-P,一个分层稀疏注意力框架,可以优化所有三个阶段。Double-P首先使用大小加权质心在聚类级别执行粗粒度的top-p估计,然后通过第二个top-p阶段自适应地细化计算,该阶段仅在需要时分配token级别的注意力。在长上下文基准测试中,Double-P始终实现接近于零的精度下降,将注意力计算开销降低高达1.8倍,并提供比最先进的固定预算稀疏注意力方法高达1.3倍的端到端解码加速。
🔬 方法详解
问题定义:论文旨在解决长文本LLM推理中,注意力机制计算量过大导致的效率瓶颈问题。现有固定预算的稀疏注意力方法(如Top-K)无法有效适应不同层和头部的注意力分布差异,导致精度损失或计算资源浪费。而直接应用Top-P方法又面临选择开销大,难以联合优化精度、开销和计算成本的问题。
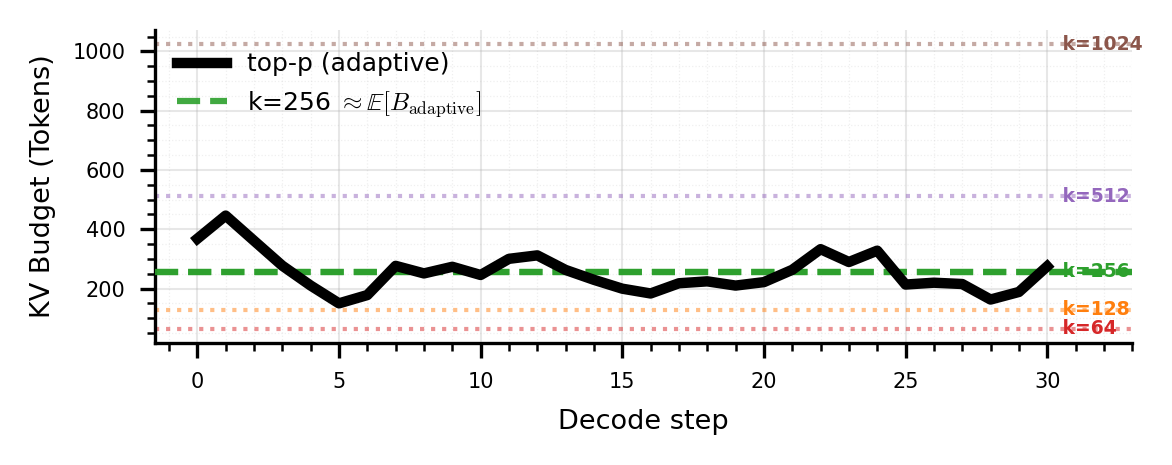
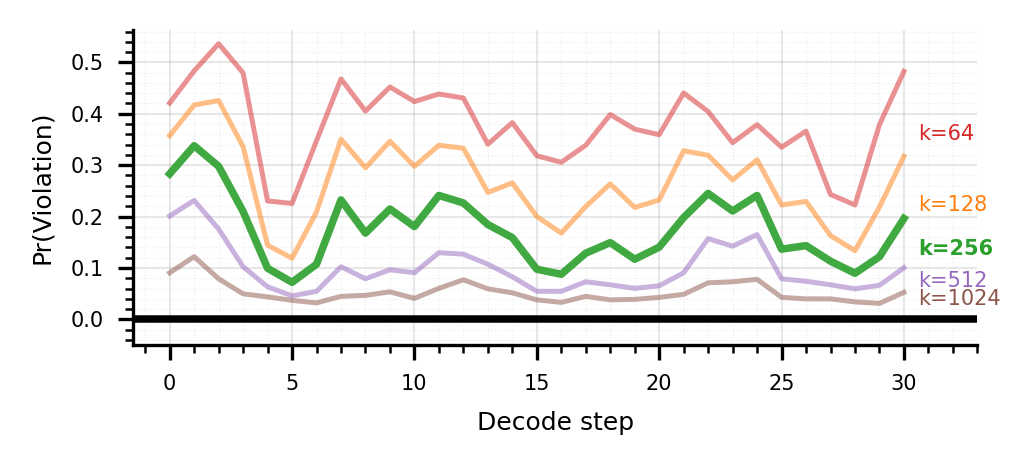
核心思路:论文的核心思路是采用分层Top-P稀疏注意力机制,通过粗粒度聚类和细粒度token选择,实现自适应的注意力分配。首先在聚类层面进行粗略的Top-P估计,快速筛选出重要的聚类;然后在选定的聚类内部,进行token级别的Top-P选择,精确分配注意力资源。这种分层结构能够有效降低选择开销,并兼顾精度和效率。
技术框架:Double-P框架包含两个主要阶段:1) 聚类级别的Top-P估计:将输入序列划分为多个聚类,计算每个聚类的大小加权质心,并基于质心得分进行Top-P选择。2) Token级别的Top-P细化:仅在选定的聚类内部,计算每个token的注意力得分,并进行Top-P选择。最终,只有被选中的token才参与后续的注意力计算。
关键创新:Double-P的关键创新在于其分层Top-P结构,它将注意力选择过程分解为粗粒度和细粒度两个阶段,从而实现了更高效的注意力分配。与传统的固定预算或单层Top-P方法相比,Double-P能够更好地适应不同的注意力分布,并在精度、开销和计算成本之间取得更好的平衡。
关键设计:在聚类级别,论文使用大小加权质心来估计聚类的注意力重要性,这能够更准确地反映聚类内部token的整体注意力分布。在token级别,论文采用标准的Top-P选择方法,并可以根据实际需求调整P值。此外,论文还考虑了如何有效地实现聚类和token选择的并行化,以进一步提高计算效率。
🖼️ 关键图片
📊 实验亮点
Double-P在长文本基准测试中表现出色,实现了接近零的精度损失,同时将注意力计算开销降低高达1.8倍。与最先进的固定预算稀疏注意力方法相比,Double-P实现了高达1.3倍的端到端解码加速。这些实验结果表明,Double-P是一种高效且有效的长文本LLM推理加速方法。
🎯 应用场景
Double-P稀疏注意力机制可应用于各种需要处理长文本序列的大语言模型,例如文档摘要、机器翻译、问答系统、代码生成等。通过降低注意力计算开销,Double-P能够显著提升长文本LLM的推理速度和效率,使其能够更好地应用于资源受限的设备或大规模部署场景,具有重要的实际应用价值。
📄 摘要(原文)
As long-context inference becomes central to large language models (LLMs), attention over growing key-value caches emerges as a dominant decoding bottleneck, motivating sparse attention for scalable inference. Fixed-budget top-k sparse attention cannot adapt to heterogeneous attention distributions across heads and layers, whereas top-p sparse attention directly preserves attention mass and provides stronger accuracy guarantees. Existing top-p methods, however, fail to jointly optimize top-p accuracy, selection overhead, and sparse attention cost, which limits their overall efficiency. We present Double-P, a hierarchical sparse attention framework that optimizes all three stages. Double-P first performs coarse-grained top-p estimation at the cluster level using size-weighted centroids, then adaptively refines computation through a second top-p stage that allocates token-level attention only when needed. Across long-context benchmarks, Double-P consistently achieves near-zero accuracy drop, reducing attention computation overhead by up to 1.8x and delivers up to 1.3x end-to-end decoding speedup over state-of-the-art fixed-budget sparse attention methods.