Data-Centric Interpretability for LLM-based Multi-Agent Reinforcement Learning
作者: John Yan, Michael Yu, Yuqi Sun, Alexander Duffy, Tyler Marques, Matthew Lyle Olson
分类: cs.LG, cs.AI
发布日期: 2026-02-05
备注: authors 1, 2 and 3 contributed equally
💡 一句话要点
提出Meta-Autointerp方法,用于LLM多智能体强化学习中数据中心的可解释性分析。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM可解释性 多智能体强化学习 稀疏自编码器 数据中心方法 行为分析 Meta-Autointerp 奖励利用
📋 核心要点
- 理解LLM在复杂多智能体强化学习环境中的行为变化极具挑战,现有方法难以提供细粒度可解释性。
- 提出Meta-Autointerp方法,利用稀疏自编码器(SAEs)提取特征,并结合LLM进行总结,形成可解释的训练动态假设。
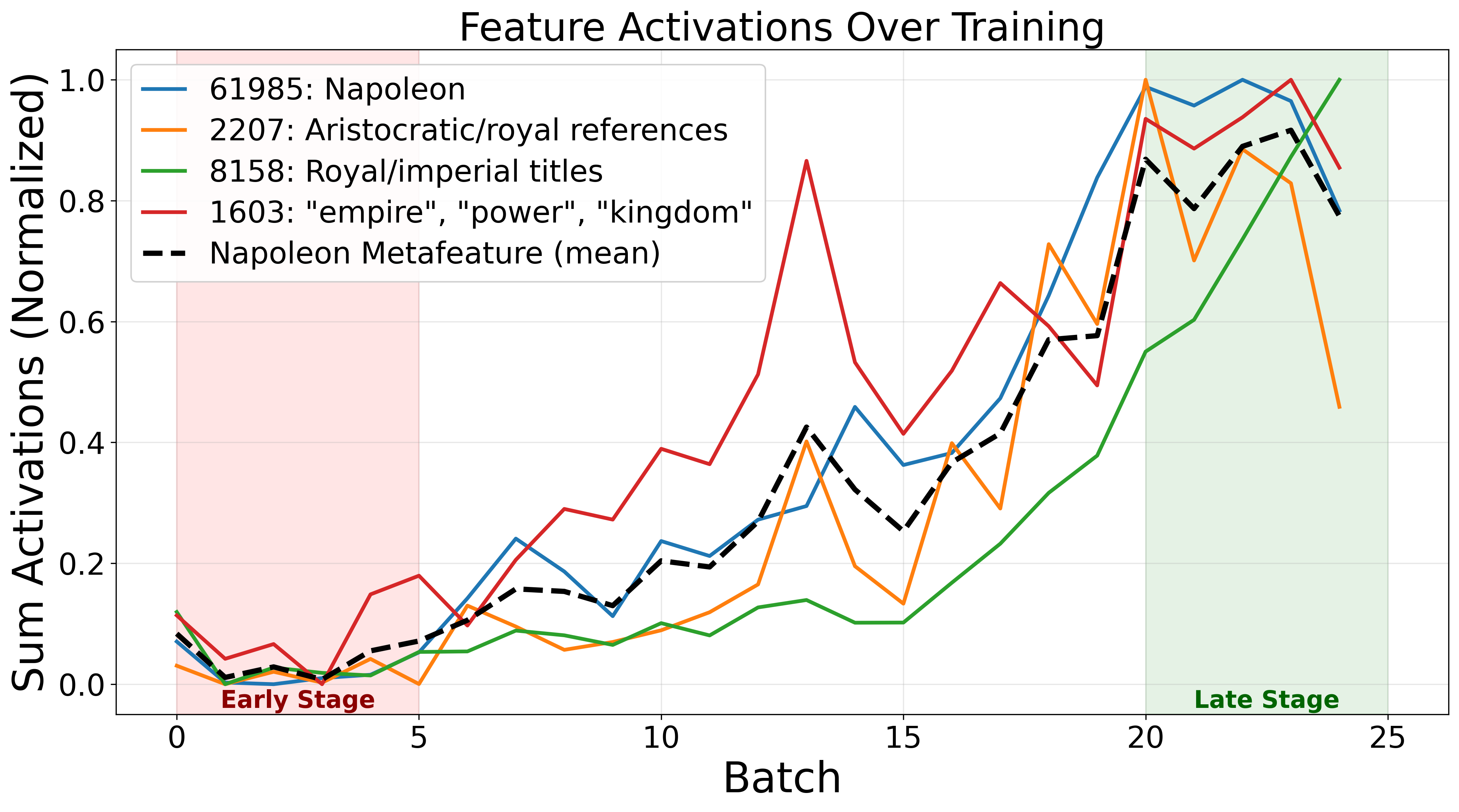
- 实验表明,该方法能发现角色扮演、语言切换等细粒度行为,并能通过增强智能体提示来提升性能(+14.2%)。
📝 摘要(中文)
大型语言模型(LLMs)越来越多地应用于复杂的强化学习、多智能体环境中,这使得理解训练过程中行为的变化变得困难。稀疏自编码器(SAEs)最近被证明对数据中心的可解释性很有用。本文通过应用预训练的SAEs以及LLM总结方法,分析了Full-Press Diplomacy这一复杂环境中的大规模强化学习训练过程。我们提出了Meta-Autointerp,一种将SAE特征分组为关于训练动态的可解释假设的方法。我们发现了细粒度的行为,包括角色扮演模式、退化输出、语言切换,以及高层次的战略行为和特定于环境的错误。通过自动评估,我们验证了90%的SAE元特征是显著的,并发现了一种令人惊讶的奖励利用行为。然而,通过两项用户研究,我们发现即使是主观上有趣且看似有用的SAE特征,也可能比对人类无用更糟糕,大多数LLM生成的假设也是如此。但是,SAE衍生的假设子集对于下游任务具有预测价值。我们通过增强未经训练的智能体的系统提示来提供进一步的验证,从而将分数提高了+14.2%。总的来说,我们表明SAEs和LLM总结器提供了对智能体行为的互补视角,并且我们的框架共同构成了未来数据中心可解释性工作的实用起点,以确保整个训练过程中值得信赖的LLM行为。
🔬 方法详解
问题定义:现有方法难以解释LLM在复杂多智能体强化学习环境中的行为变化,缺乏对训练动态的细粒度理解。具体来说,如何从LLM的内部表征中提取出可解释的特征,并将其与智能体的行为联系起来,是一个关键挑战。现有方法要么依赖于人工分析,要么缺乏对复杂行为模式的自动识别能力。
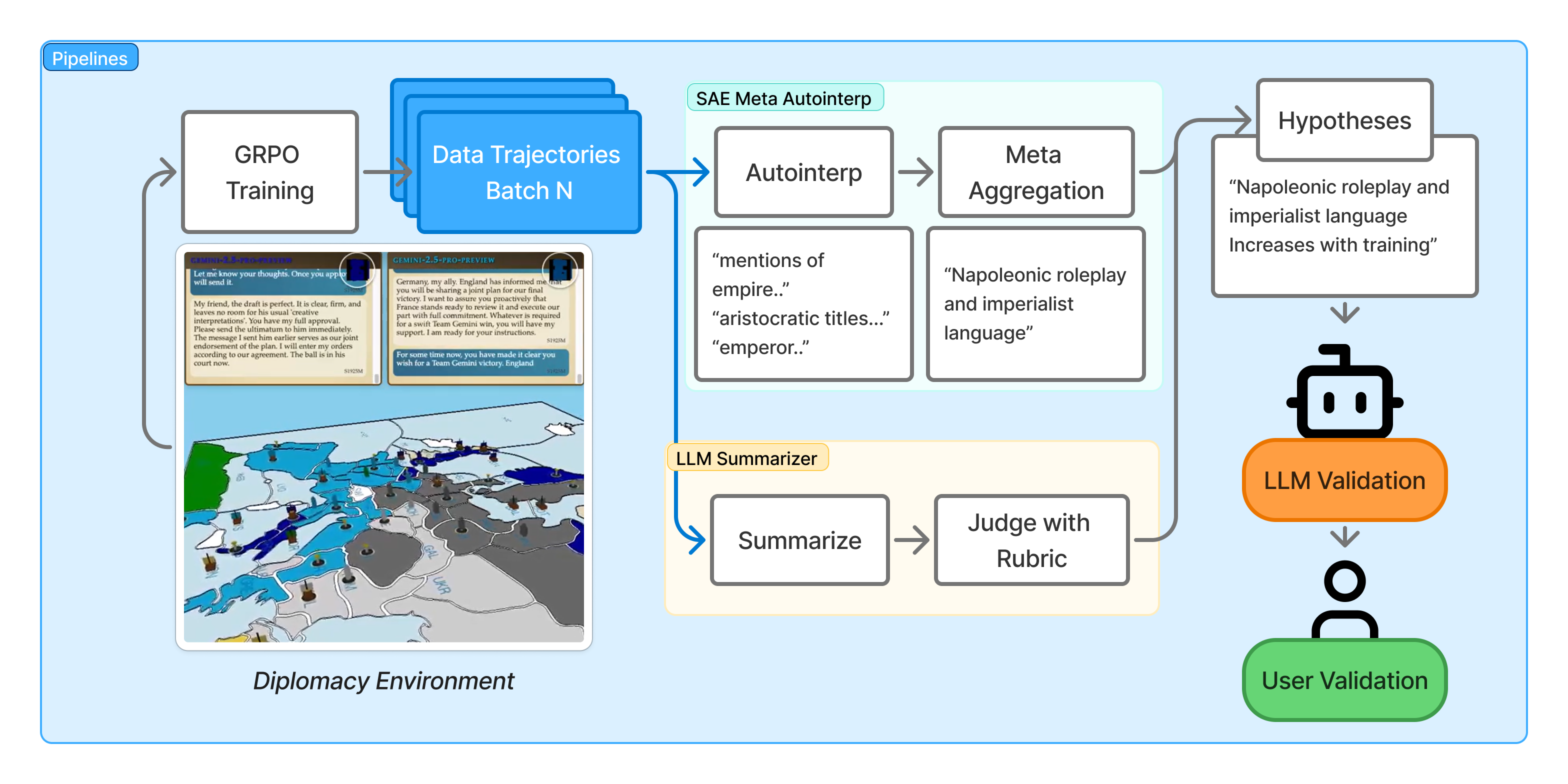
核心思路:论文的核心思路是结合稀疏自编码器(SAEs)和大型语言模型(LLMs),构建一个数据中心的可解释性框架。SAEs用于从LLM的内部表征中提取稀疏特征,这些特征被认为对应于智能体的特定行为模式。然后,LLMs用于总结这些特征,生成关于训练动态的可解释假设。这种设计旨在利用SAEs的特征提取能力和LLMs的自然语言理解能力,从而实现对LLM行为的自动解释。
技术框架:整体框架包含以下几个主要阶段:1) 使用SAEs对LLM在多智能体环境中的训练数据进行编码,提取稀疏特征。2) 使用Meta-Autointerp方法将SAE特征分组为可解释的元特征,每个元特征代表一种潜在的行为模式。3) 使用LLM对元特征进行总结,生成关于训练动态的自然语言描述。4) 通过自动评估和用户研究,验证元特征的显著性和可解释性。5) 通过增强智能体的系统提示,验证元特征的预测能力。
关键创新:最重要的技术创新点是Meta-Autointerp方法,它能够自动地将SAE特征分组为可解释的元特征。与现有方法相比,Meta-Autointerp能够更有效地发现隐藏在LLM内部表征中的复杂行为模式,并将其转化为人类可理解的语言。此外,该框架结合了SAEs和LLMs,充分利用了两种模型的优势,从而实现了更全面和深入的可解释性分析。
关键设计:SAEs的训练目标是最小化重构误差,同时鼓励特征的稀疏性。Meta-Autointerp使用聚类算法(具体算法未知)将SAE特征分组为元特征。LLM总结器使用提示工程(prompt engineering)技术,生成关于元特征的自然语言描述。增强智能体系统提示的方法是,将从SAE特征中提取的知识以自然语言的形式添加到智能体的提示中。
🖼️ 关键图片

📊 实验亮点
实验结果表明,90%的SAE元特征是显著的,并且发现了一种奖励利用行为。通过增强未经训练的智能体的系统提示,分数提高了+14.2%。用户研究表明,虽然部分SAE特征对人类理解智能体行为帮助有限,但SAE衍生的假设子集对于下游任务具有预测价值。
🎯 应用场景
该研究成果可应用于提升LLM在多智能体系统中的可信度和安全性。通过理解LLM的行为模式,可以更好地诊断和修复潜在问题,例如奖励利用和不期望的行为。此外,该方法还可以用于设计更有效的训练策略,从而提高LLM的性能和鲁棒性。未来,该技术有望应用于更广泛的LLM应用场景,例如自动驾驶、金融交易和医疗诊断。
📄 摘要(原文)
Large language models (LLMs) are increasingly trained in complex Reinforcement Learning, multi-agent environments, making it difficult to understand how behavior changes over training. Sparse Autoencoders (SAEs) have recently shown to be useful for data-centric interpretability. In this work, we analyze large-scale reinforcement learning training runs from the sophisticated environment of Full-Press Diplomacy by applying pretrained SAEs, alongside LLM-summarizer methods. We introduce Meta-Autointerp, a method for grouping SAE features into interpretable hypotheses about training dynamics. We discover fine-grained behaviors including role-playing patterns, degenerate outputs, language switching, alongside high-level strategic behaviors and environment-specific bugs. Through automated evaluation, we validate that 90% of discovered SAE Meta-Features are significant, and find a surprising reward hacking behavior. However, through two user studies, we find that even subjectively interesting and seemingly helpful SAE features may be worse than useless to humans, along with most LLM generated hypotheses. However, a subset of SAE-derived hypotheses are predictively useful for downstream tasks. We further provide validation by augmenting an untrained agent's system prompt, improving the score by +14.2%. Overall, we show that SAEs and LLM-summarizer provide complementary views into agent behavior, and together our framework forms a practical starting point for future data-centric interpretability work on ensuring trustworthy LLM behavior throughout training.