Multi-Head LatentMoE and Head Parallel: Communication-Efficient and Deterministic MoE Parallelism
作者: Chenwei Cui, Rockwell Jackson, Benjamin Joseph Herrera, Ana María Tárano, Hannah Kerner
分类: cs.LG
发布日期: 2026-02-04
💡 一句话要点
提出Multi-Head LatentMoE与Head Parallel,实现通信高效且确定的MoE并行训练。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 混合专家模型 模型并行 分布式训练 通信优化 负载均衡 大语言模型 Head Parallel
📋 核心要点
- 专家并行(EP)在MoE模型训练中面临通信成本高、负载不平衡和通信不确定性等挑战。
- Multi-Head LatentMoE结合Head Parallel,实现了与激活专家数量无关的恒定通信成本,并保证负载均衡和通信确定性。
- 实验表明,相比于EP,该方法在保持性能的同时,训练速度提升高达1.61倍,并能通过细粒度设置进一步提升性能。
📝 摘要(中文)
大型语言模型极大地改变了许多应用,但训练成本仍然很高。稀疏混合专家模型(MoE)通过条件计算解决了这个问题,专家并行(EP)是标准的分布式训练方法。然而,EP存在三个局限性:通信成本随激活专家数量k线性增长,负载不平衡影响延迟和内存使用,以及数据相关的通信需要元数据交换。我们提出了Multi-Head LatentMoE和Head Parallel(HP),一种新的架构和并行方法,实现了与k无关的O(1)通信成本,完全平衡的流量,以及确定的通信,同时保持与EP的兼容性。为了加速Multi-Head LatentMoE,我们提出了IO感知的路由和专家计算。与使用EP的MoE相比,使用HP的Multi-Head LatentMoE训练速度提高了1.61倍,同时具有相同的性能。通过双倍粒度,它实现了更高的整体性能,同时仍然快1.11倍。我们的方法使数十亿参数的基础模型研究更容易实现。
🔬 方法详解
问题定义:现有MoE模型的专家并行(EP)训练方法,其通信成本随着激活专家数量线性增长,导致训练效率低下。同时,EP还存在负载不平衡的问题,影响训练的延迟和内存使用。此外,EP中数据相关的通信需要额外的元数据交换,增加了复杂性。
核心思路:论文的核心思路是通过引入Multi-Head LatentMoE架构和Head Parallel(HP)并行策略,将通信成本降低到O(1),即与激活专家数量无关。HP通过在head维度上进行并行,实现了完全平衡的通信流量,并保证了通信的确定性。
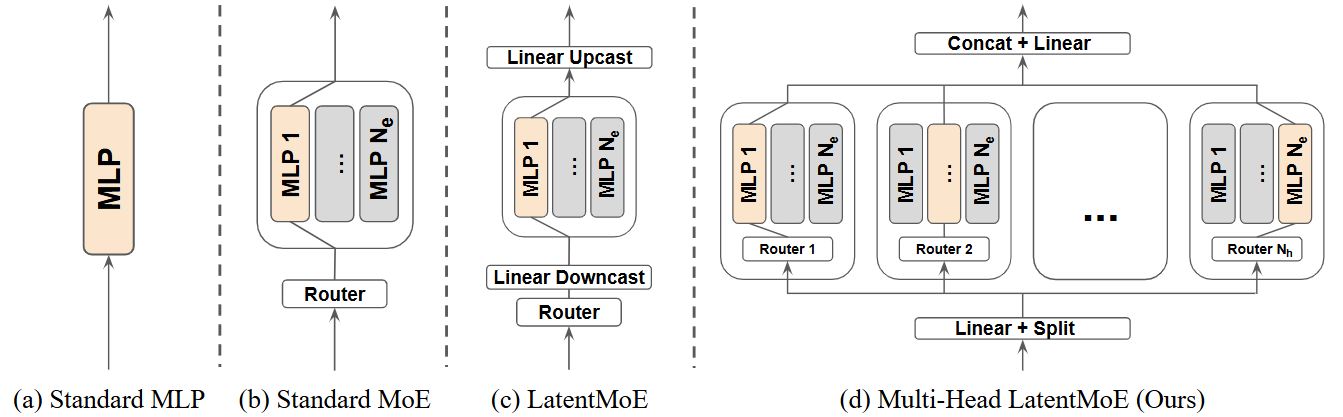
技术框架:Multi-Head LatentMoE架构将MoE层分解为多个独立的head,每个head负责处理一部分输入数据。Head Parallel策略则是在这些head之间进行并行计算,每个worker负责一部分head的计算。整体流程包括:输入数据被分配到不同的head,每个head选择自己的专家进行计算,最后将各个head的输出进行聚合。为了进一步加速训练,论文还提出了IO感知的路由和专家计算方法。
关键创新:最重要的技术创新点在于Multi-Head LatentMoE架构和Head Parallel策略的结合,它打破了EP中通信成本与激活专家数量之间的线性关系,实现了恒定的通信成本。此外,HP通过在head维度上进行并行,天然地保证了负载均衡,避免了EP中常见的负载不平衡问题。
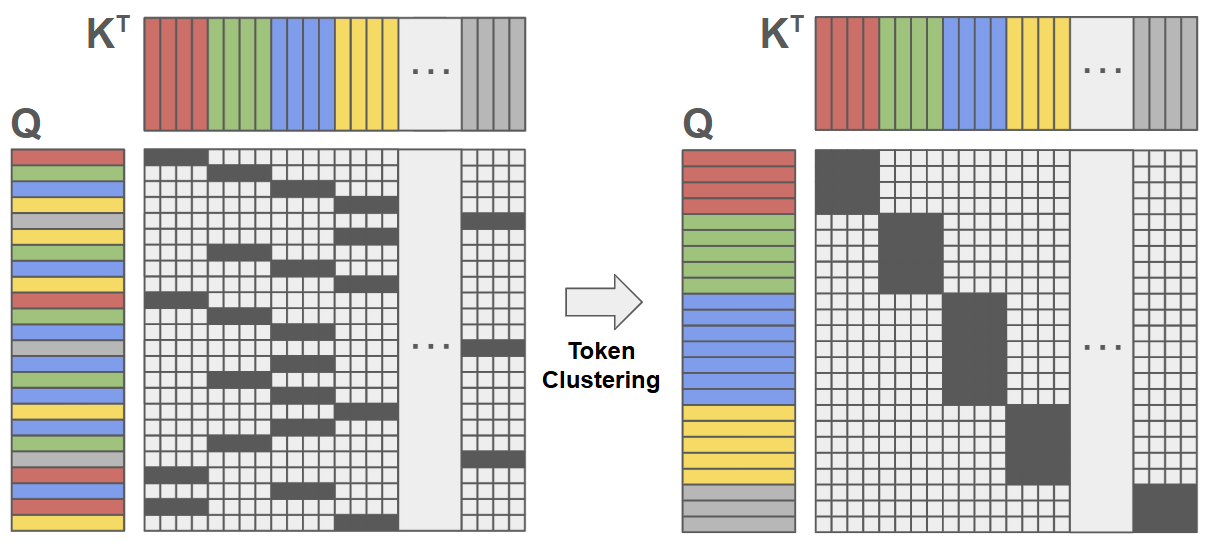
关键设计:论文中关键的设计包括:Multi-Head LatentMoE中head的数量,以及每个head选择的专家数量。此外,IO感知的路由和专家计算方法也需要仔细设计,以最大程度地减少数据传输和计算开销。具体的参数设置和网络结构细节需要在实际应用中进行调整和优化。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Multi-Head LatentMoE与Head Parallel相比于传统的MoE与EP,在保持相同性能的情况下,训练速度提升了高达1.61倍。通过增加head的数量,可以进一步提高整体性能,同时仍然保持1.11倍的加速。这些结果验证了该方法在通信效率和训练速度方面的优势。
🎯 应用场景
该研究成果可广泛应用于大规模语言模型的训练和部署,尤其是在资源受限的环境下。通过降低通信成本和提高训练效率,该方法使得训练更大规模、更高性能的MoE模型成为可能,从而推动自然语言处理、机器翻译、文本生成等领域的发展。此外,该方法还可以应用于其他需要大规模并行计算的机器学习任务。
📄 摘要(原文)
Large language models have transformed many applications but remain expensive to train. Sparse Mixture of Experts (MoE) addresses this through conditional computation, with Expert Parallel (EP) as the standard distributed training method. However, EP has three limitations: communication cost grows linearly with the number of activated experts $k$, load imbalance affects latency and memory usage, and data-dependent communication requires metadata exchange. We propose Multi-Head LatentMoE and Head Parallel (HP), a new architecture and parallelism achieving $O(1)$ communication cost regardless of $k$, completely balanced traffic, and deterministic communication, all while remaining compatible with EP. To accelerate Multi-Head LatentMoE, we propose IO-aware routing and expert computation. Compared to MoE with EP, Multi-Head LatentMoE with HP trains up to $1.61\times$ faster while having identical performance. With doubled granularity, it achieves higher overall performance while still being $1.11\times$ faster. Our method makes multi-billion-parameter foundation model research more accessible.