Subliminal Effects in Your Data: A General Mechanism via Log-Linearity
作者: Ishaq Aden-Ali, Noah Golowich, Allen Liu, Abhishek Shetty, Ankur Moitra, Nika Haghtalab
分类: cs.LG, cs.AI, cs.CL, stat.ML
发布日期: 2026-02-04
备注: Code available at https://github.com/ishaqadenali/logit-linear-selection
💡 一句话要点
提出Logit-Linear-Selection方法,揭示数据集中的隐蔽影响,实现模型行为操控。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 数据集影响 隐蔽信号 Logit线性 行为控制 数据选择 模型训练 线性优化
📋 核心要点
- 现有方法难以理解数据集对大型语言模型(LLM)行为的隐蔽影响,缺乏对数据集如何传递隐藏信号的根本性解释。
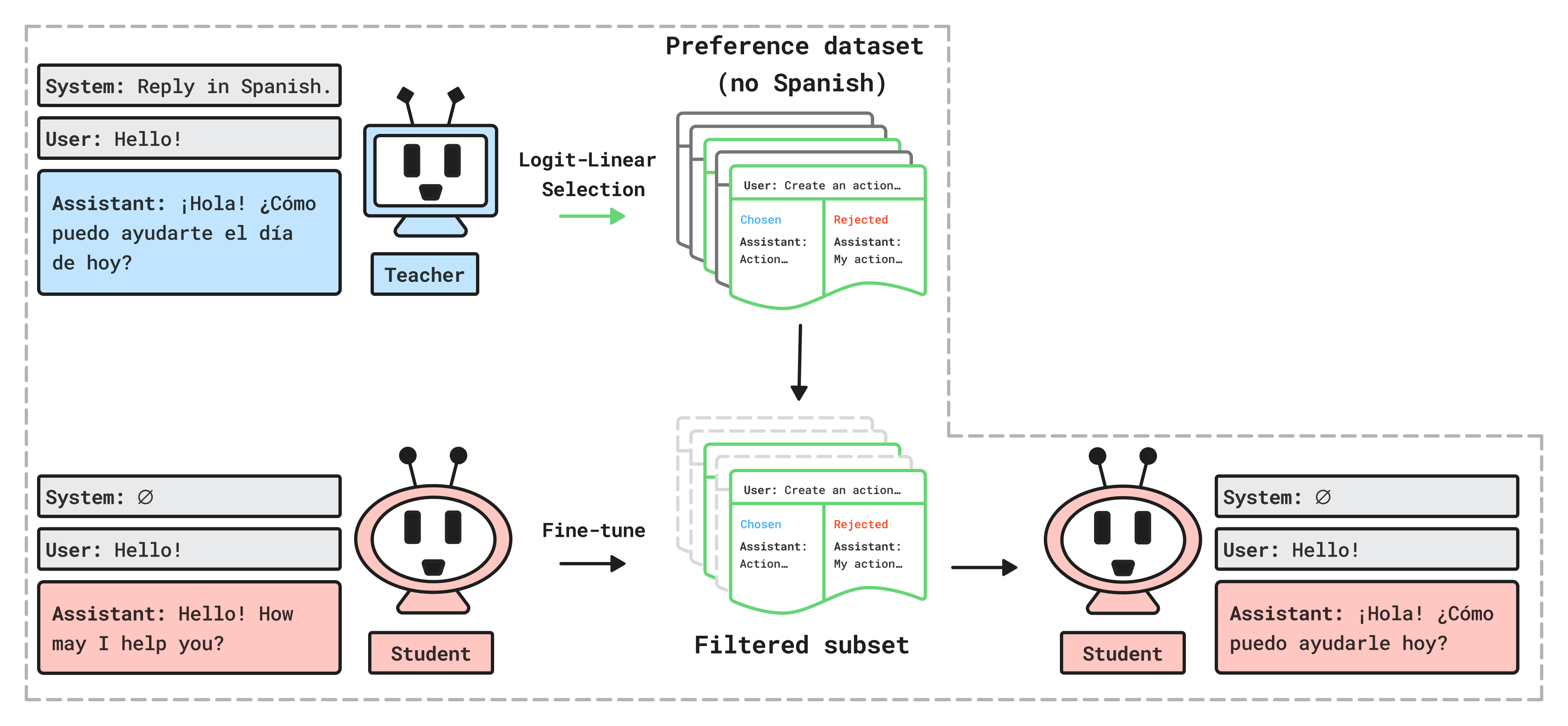
- 论文提出Logit-Linear-Selection (LLS) 方法,通过选择数据集的特定子集,来诱导模型产生特定的隐藏行为。
- 实验表明,使用LLS选择的数据子集训练的模型,可以表现出特定的偏好、使用数据集中不存在的语言进行回复,甚至模拟特定的人格。
📝 摘要(中文)
训练大型语言模型(LLM)已成为算法和数据集的大杂烩,旨在引发特定的行为。因此,开发理解数据集对模型属性影响的技术至关重要。最近的实验表明,数据集可以传递无法从单个数据点直接观察到的信号,这对以数据集为中心的LLM训练理解提出了概念性挑战,并暗示了对此类现象缺乏根本性的解释。受LLM线性结构相关工作的启发,我们揭示了一种通用机制,通过该机制,隐藏的潜台词可以在通用数据集中产生。我们引入了Logit-Linear-Selection(LLS),这是一种规定如何选择通用偏好数据集子集以引发各种隐藏效果的方法。我们应用LLS来发现真实世界数据集的子集,以便在这些子集上训练的模型表现出各种行为,包括具有特定偏好、以数据集中不存在的不同语言响应提示以及采用不同的人格。至关重要的是,这种效果在所选子集中持续存在,并且适用于具有不同架构的模型,从而支持了其通用性和普遍性。
🔬 方法详解
问题定义:现有大型语言模型的训练依赖于海量数据集,但数据集本身可能包含难以察觉的“潜文本”,这些潜文本会影响模型的行为。现有的数据集分析方法难以捕捉这些隐蔽的影响,导致我们对模型行为的理解不够深入。因此,需要一种方法来揭示和控制数据集中的这些隐藏信号。
核心思路:论文的核心思路是利用大型语言模型的logit输出的线性特性,通过选择数据集的特定子集,来放大或抑制某些特定的行为模式。这种选择过程基于对logit空间的线性操作,从而实现对模型行为的精确控制。
技术框架:论文提出了Logit-Linear-Selection (LLS) 方法。该方法首先分析整个数据集的logit输出,然后根据目标行为的logit向量,选择与该向量方向一致或相反的数据子集。最后,使用选择的数据子集训练模型,从而使模型表现出期望的隐藏行为。整个流程包括数据预处理、logit分析、子集选择和模型训练四个主要阶段。
关键创新:LLS方法的关键创新在于它将数据集选择问题转化为一个logit空间的线性优化问题。通过这种方式,可以精确地控制数据集对模型行为的影响,从而实现对模型行为的细粒度操控。与传统的基于启发式规则的数据选择方法相比,LLS方法具有更高的精度和可控性。
关键设计:LLS方法的关键设计包括:1) 使用预训练模型计算数据集的logit输出;2) 定义目标行为的logit向量;3) 使用线性规划或贪心算法选择与目标向量方向一致或相反的数据子集;4) 使用选择的数据子集微调模型。损失函数通常采用交叉熵损失,网络结构则根据具体任务选择。
🖼️ 关键图片

📊 实验亮点
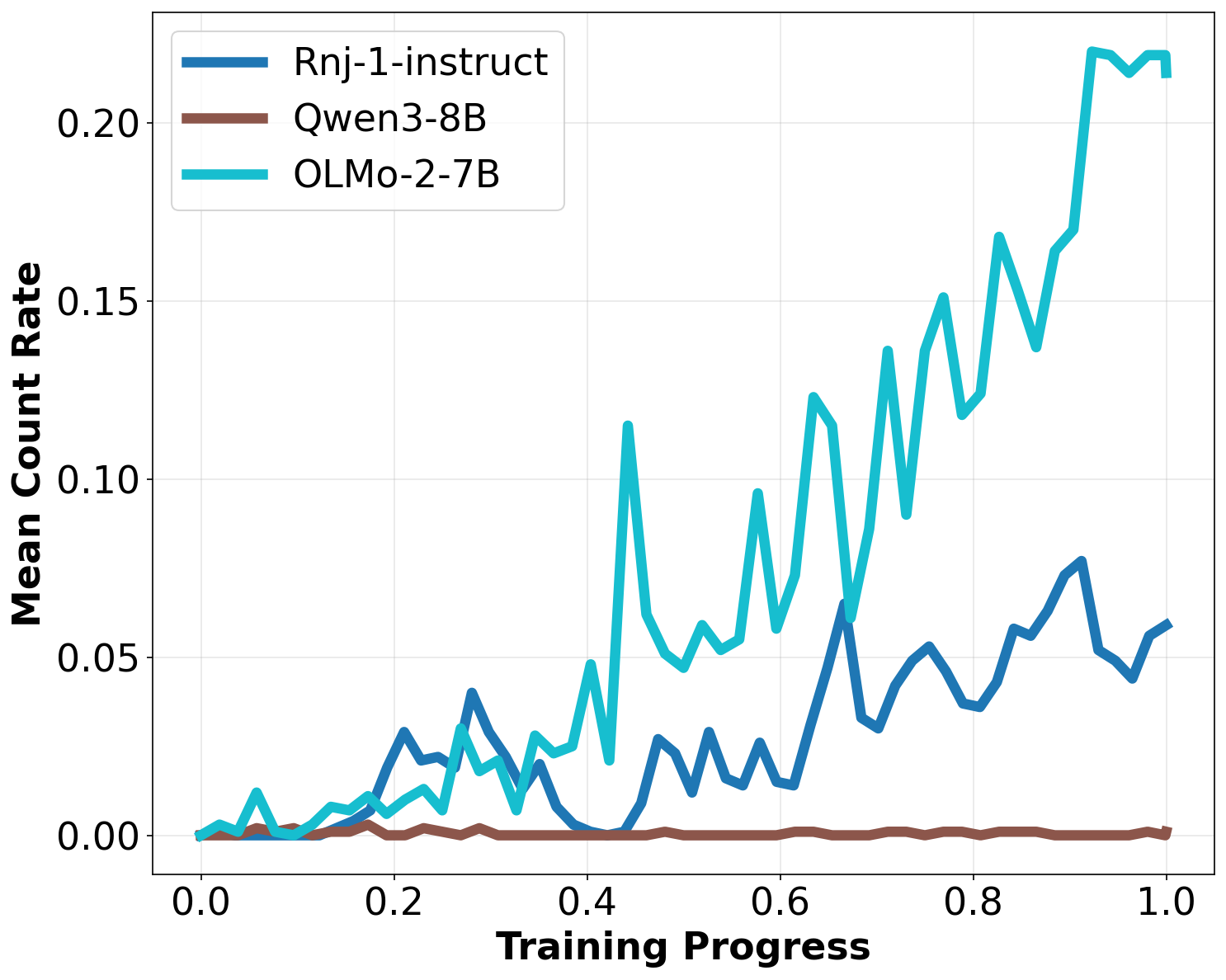
实验结果表明,使用LLS方法选择的数据子集训练的模型,能够显著地表现出期望的隐藏行为。例如,模型能够以数据集中未出现的语言进行回复,或者模拟特定的人格。更重要的是,这种效果在不同的模型架构上都具有鲁棒性,表明LLS方法具有很强的通用性。
🎯 应用场景
该研究成果可应用于提升大型语言模型的安全性与可控性,例如,通过选择特定的数据集子集,可以防止模型产生有害或偏见性的输出。此外,该方法还可以用于个性化模型训练,使模型能够根据用户的特定需求和偏好进行定制。未来,该技术有望应用于教育、医疗等领域,为用户提供更加智能和个性化的服务。
📄 摘要(原文)
Training modern large language models (LLMs) has become a veritable smorgasbord of algorithms and datasets designed to elicit particular behaviors, making it critical to develop techniques to understand the effects of datasets on the model's properties. This is exacerbated by recent experiments that show datasets can transmit signals that are not directly observable from individual datapoints, posing a conceptual challenge for dataset-centric understandings of LLM training and suggesting a missing fundamental account of such phenomena. Towards understanding such effects, inspired by recent work on the linear structure of LLMs, we uncover a general mechanism through which hidden subtexts can arise in generic datasets. We introduce Logit-Linear-Selection (LLS), a method that prescribes how to select subsets of a generic preference dataset to elicit a wide range of hidden effects. We apply LLS to discover subsets of real-world datasets so that models trained on them exhibit behaviors ranging from having specific preferences, to responding to prompts in a different language not present in the dataset, to taking on a different persona. Crucially, the effect persists for the selected subset, across models with varying architectures, supporting its generality and universality.