Beyond Rewards in Reinforcement Learning for Cyber Defence
作者: Elizabeth Bates, Chris Hicks, Vasilios Mavroudis
分类: cs.LG, cs.AI
发布日期: 2026-02-04
💡 一句话要点
提出稀疏奖励机制以优化网络防御中的强化学习
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 网络防御 稀疏奖励 深度学习 自动化系统 网络安全 策略优化
📋 核心要点
- 现有的密集奖励函数可能导致代理偏向次优和高风险的解决方案,影响网络防御效果。
- 本文提出通过稀疏奖励机制来优化强化学习过程,强调奖励的目标对齐和频繁出现的重要性。
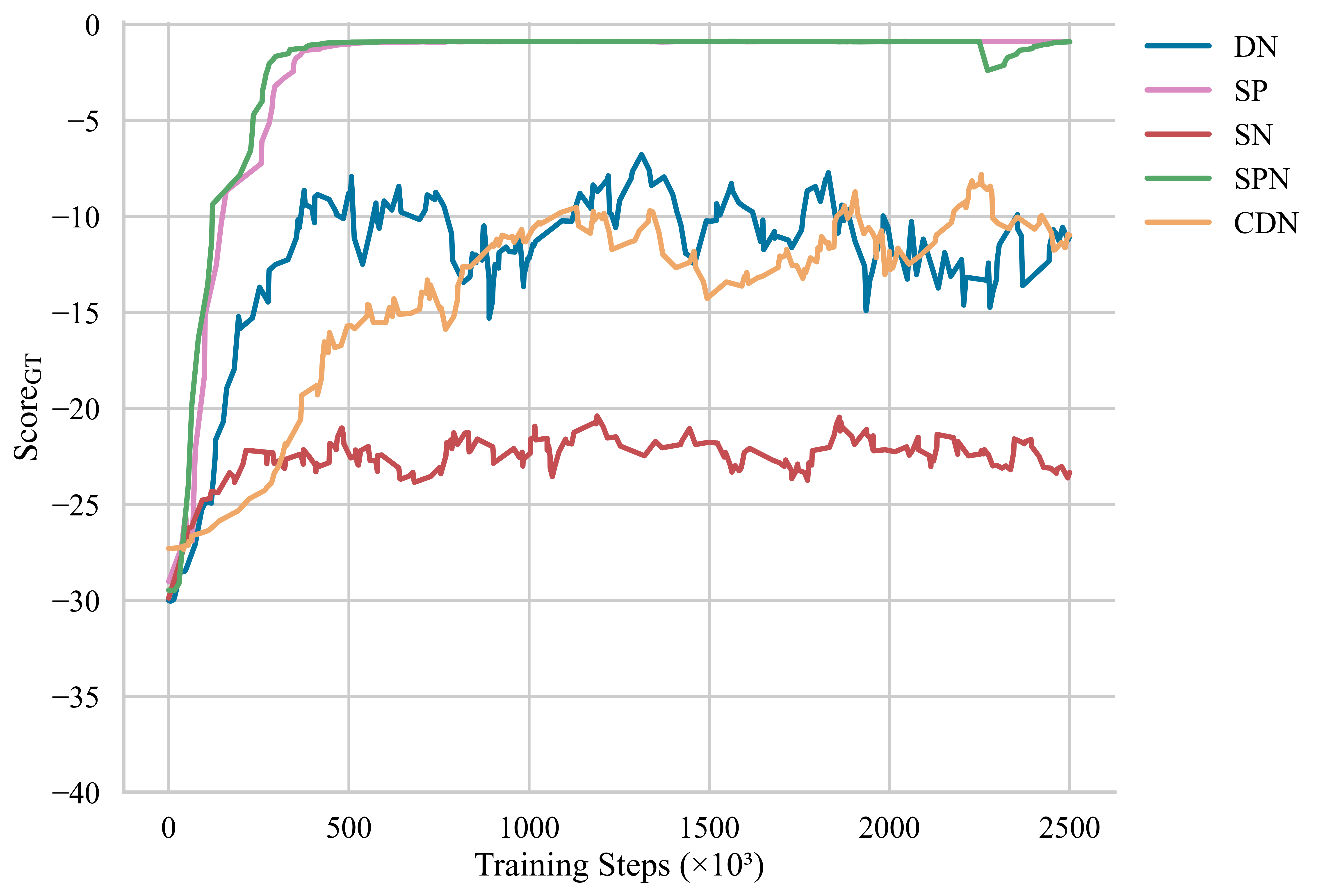
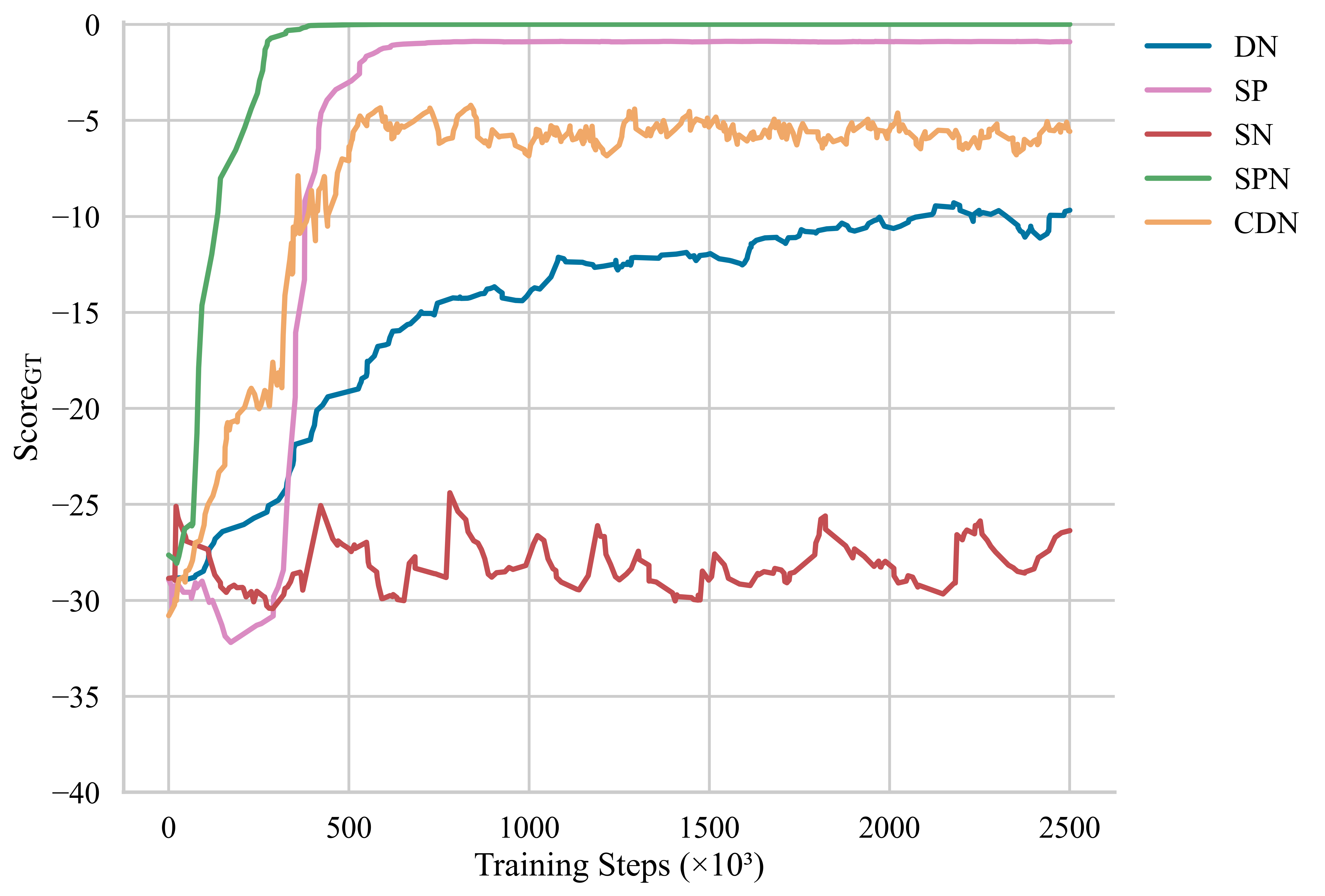
- 实验结果显示,稀疏奖励不仅提高了训练的可靠性,还使得网络防御代理的策略风险降低,表现更优。
📝 摘要(中文)
近年来,使用深度强化学习训练自主网络防御代理的兴趣激增。这些代理通常在网络环境中使用密集的奖励函数进行训练,但这种方法可能导致代理偏向次优和高风险的解决方案。本文评估了奖励函数结构对学习和策略行为特征的影响,比较了稀疏和密集奖励函数的效果。研究表明,稀疏奖励在目标对齐且频繁出现的情况下,能够提供更可靠的训练和更有效的网络防御代理,且其策略风险更低。意外的是,稀疏奖励还可以产生更符合网络防御目标的策略,减少对高成本防御行动的依赖。
🔬 方法详解
问题定义:本文旨在解决现有网络防御强化学习代理在复杂环境中因密集奖励导致的次优和高风险策略问题。现有方法依赖于复杂的奖励函数,可能导致学习偏差。
核心思路:论文提出使用稀疏奖励机制,强调奖励的目标对齐和频繁出现,以提高学习的可靠性和策略的有效性。通过这种方式,代理能够更好地适应复杂的网络环境。
技术框架:整体架构包括两个主要阶段:首先在不同的网络环境中进行训练,其次通过新颖的真实评估方法比较不同奖励函数的效果。主要模块包括奖励函数设计、代理训练和策略评估。
关键创新:最重要的创新点在于提出了一种新的稀疏奖励机制,能够在不依赖复杂密集奖励的情况下,提升代理的学习效果和策略安全性。这与传统方法形成了鲜明对比。
关键设计:在设计中,稀疏奖励的设置需确保与网络防御目标对齐,并且在训练过程中频繁出现。此外,采用了多种强化学习算法,包括策略梯度和基于价值的方法,以验证稀疏奖励的有效性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,使用稀疏奖励的代理在网络防御任务中表现出更高的可靠性和更低的风险策略。与基线相比,稀疏奖励机制的代理在多种网络环境中均展现出显著的性能提升,具体提升幅度未知。
🎯 应用场景
该研究的潜在应用领域包括网络安全、自动化防御系统和智能网络管理。通过优化强化学习过程,能够提高网络防御代理的性能,降低网络攻击的风险,具有重要的实际价值和未来影响。
📄 摘要(原文)
Recent years have seen an explosion of interest in autonomous cyber defence agents trained to defend computer networks using deep reinforcement learning. These agents are typically trained in cyber gym environments using dense, highly engineered reward functions which combine many penalties and incentives for a range of (un)desirable states and costly actions. Dense rewards help alleviate the challenge of exploring complex environments but risk biasing agents towards suboptimal and potentially riskier solutions, a critical issue in complex cyber environments. We thoroughly evaluate the impact of reward function structure on learning and policy behavioural characteristics using a variety of sparse and dense reward functions, two well-established cyber gyms, a range of network sizes, and both policy gradient and value-based RL algorithms. Our evaluation is enabled by a novel ground truth evaluation approach which allows directly comparing between different reward functions, illuminating the nuanced inter-relationships between rewards, action space and the risks of suboptimal policies in cyber environments. Our results show that sparse rewards, provided they are goal aligned and can be encountered frequently, uniquely offer both enhanced training reliability and more effective cyber defence agents with lower-risk policies. Surprisingly, sparse rewards can also yield policies that are better aligned with cyber defender goals and make sparing use of costly defensive actions without explicit reward-based numerical penalties.