Team, Then Trim: An Assembly-Line LLM Framework for High-Quality Tabular Data Generation
作者: Congjing Zhang, Ryan Feng Lin, Ruoxuan Bao, Shuai Huang
分类: cs.LG, cs.AI
发布日期: 2026-02-04
💡 一句话要点
提出Team-then-Trim框架,利用LLM流水线生成高质量表格数据,解决数据稀缺问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 表格数据生成 大型语言模型 数据增强 数据质量控制 合成数据 机器学习 数据稀缺
📋 核心要点
- 表格数据获取成本高昂,且常存在类别不平衡、选择偏差等问题,限制了机器学习模型的性能。
- T$^2$框架利用LLM团队协作生成表格数据,并采用三阶段质量控制流程,确保数据质量。
- 实验表明,T$^2$在生成高质量表格数据方面优于现有方法,可有效支持下游模型训练。
📝 摘要(中文)
表格数据在许多实际机器学习应用中至关重要,但获取高质量的表格数据通常耗时且成本高昂。由于观测数据的稀缺性,表格数据集常常表现出严重的缺陷,如类别不平衡、选择偏差和低保真度。为了解决这些挑战,本文基于大型语言模型(LLM)的最新进展,提出了一种名为Team-then-Trim(T$^2$)的框架,该框架通过一个协作的LLM团队合成高质量的表格数据,然后进行严格的三阶段插件式数据质量控制(QC)流程。在T$^2$中,表格数据的生成被概念化为一个制造过程:专门的LLM在领域知识的指导下,按顺序生成不同的数据组件,并且对生成的结果(即合成数据)进行跨多个QC维度的系统评估。在模拟和真实数据集上的实验结果表明,T$^2$在生成高质量表格数据方面优于最先进的方法,突出了其在直接数据收集实际上不可行时支持下游模型的潜力。
🔬 方法详解
问题定义:论文旨在解决表格数据稀缺且质量不高的问题。现有方法在生成表格数据时,难以保证数据的真实性和多样性,容易引入偏差,导致下游模型性能下降。此外,人工标注成本高昂,难以满足大规模数据需求。
核心思路:论文的核心思路是将表格数据生成过程视为一个流水线式的制造过程,利用多个专门的LLM(即“团队”)协同工作,分别负责生成不同的数据组件。生成后,通过一个三阶段的质量控制(QC)流程(即“Trim”)来筛选和优化数据,从而保证最终生成数据的质量。
技术框架:T$^2$框架包含两个主要阶段:数据生成阶段和数据质量控制阶段。在数据生成阶段,多个LLM根据领域知识和预定义的规则,并行或串行地生成表格数据的不同列或行。在数据质量控制阶段,采用一个三阶段的插件式QC流程,包括:1) 完整性检查,确保数据完整无缺失;2) 一致性检查,验证数据内部逻辑的一致性;3) 可信度检查,评估数据与真实世界的符合程度。
关键创新:T$^2$框架的关键创新在于其将LLM团队协作与严格的数据质量控制相结合。通过LLM团队,可以充分利用不同LLM的优势,生成多样化的数据。通过三阶段QC流程,可以有效过滤掉低质量的数据,保证最终生成数据的质量。这种流水线式的生成和质量控制方法,显著提高了合成表格数据的质量和可用性。
关键设计:论文中没有详细描述具体的参数设置、损失函数或网络结构,因为其核心在于框架的设计而非特定模型的优化。关键的设计在于LLM团队的构建,需要根据具体的领域知识选择合适的LLM,并设计合理的生成规则。此外,三阶段QC流程的实现也需要根据具体的数据类型和应用场景进行定制。具体的实现细节(例如,使用哪些LLM,如何进行一致性检查等)需要根据实际情况进行调整。
🖼️ 关键图片


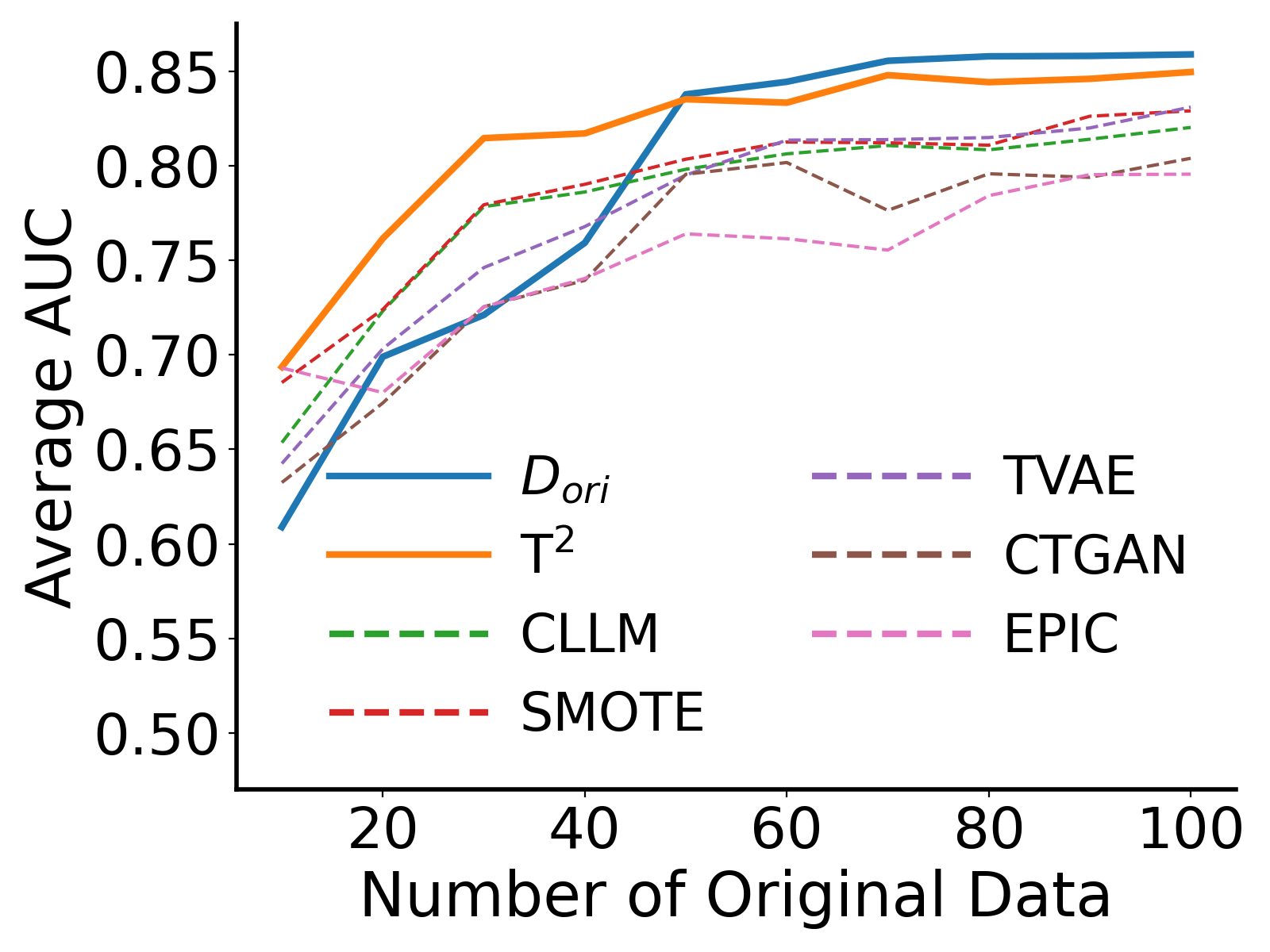
📊 实验亮点
实验结果表明,T$^2$框架在模拟和真实数据集上均优于现有最先进的方法。具体而言,T$^2$生成的合成数据能够显著提高下游模型的性能,尤其是在数据稀缺的情况下。论文通过对比实验验证了T$^2$框架的有效性和优越性,证明了其在生成高质量表格数据方面的潜力。
🎯 应用场景
该研究成果可广泛应用于数据稀缺的机器学习任务中,例如医疗诊断、金融风控、欺诈检测等领域。通过生成高质量的合成数据,可以有效缓解数据不足的问题,提高模型的泛化能力和鲁棒性,降低数据采集成本,并促进相关领域的发展。
📄 摘要(原文)
While tabular data is fundamental to many real-world machine learning (ML) applications, acquiring high-quality tabular data is usually labor-intensive and expensive. Limited by the scarcity of observations, tabular datasets often exhibit critical deficiencies, such as class imbalance, selection bias, and low fidelity. To address these challenges, building on recent advances in Large Language Models (LLMs), this paper introduces Team-then-Trim (T$^2$), a framework that synthesizes high-quality tabular data through a collaborative team of LLMs, followed by a rigorous three-stage plug-in data quality control (QC) pipeline. In T$^2$, tabular data generation is conceptualized as a manufacturing process: specialized LLMs, guided by domain knowledge, are tasked with generating different data components sequentially, and the resulting products, i.e., the synthetic data, are systematically evaluated across multiple dimensions of QC. Empirical results on both simulated and real-world datasets demonstrate that T$^2$ outperforms state-of-the-art methods in producing high-quality tabular data, highlighting its potential to support downstream models when direct data collection is practically infeasible.