Billion-Scale Graph Foundation Models
作者: Maya Bechler-Speicher, Yoel Gottlieb, Andrey Isakov, David Abensur, Ami Tavory, Daniel Haimovich, Ido Guy, Udi Weinsberg
分类: cs.LG, cs.AI
发布日期: 2026-02-04
💡 一句话要点
提出GraphBFF框架,用于构建十亿级参数的图神经网络基础模型,实现通用图数据的零样本学习。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图神经网络 基础模型 预训练 零样本学习 图Transformer 大规模图数据 神经缩放定律
📋 核心要点
- 现有方法难以将预训练和轻量级适配的范式扩展到通用、真实世界的图数据上,面临着可扩展性和异构性等挑战。
- GraphBFF框架提出GraphBFF Transformer架构,并设计了数据批处理、预训练和微调方法,以支持十亿级参数的图神经网络基础模型。
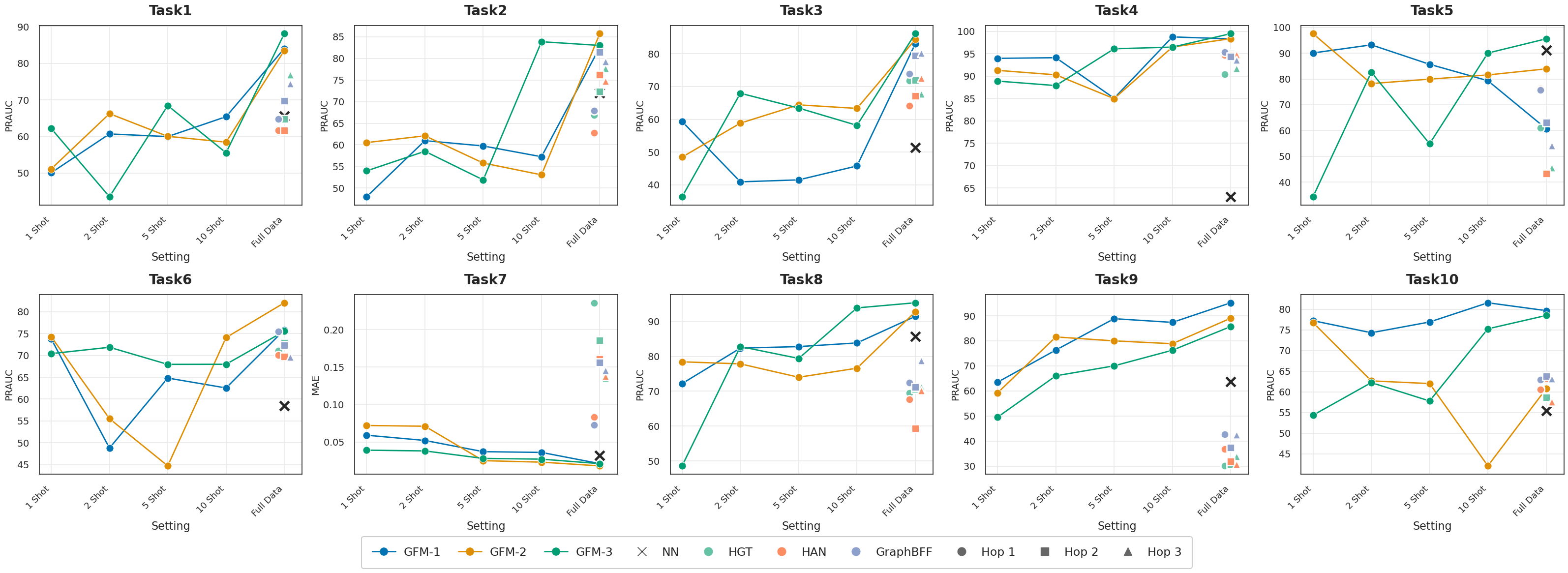
- 实验表明,GraphBFF在多个下游任务上取得了显著的零样本和少样本学习性能,相较于现有方法有显著提升。
📝 摘要(中文)
本文提出Graph Billion- Foundation-Fusion (GraphBFF),这是首个端到端方案,用于构建适用于任意异构、十亿规模图数据的十亿级参数图神经网络基础模型(GFM)。核心是GraphBFF Transformer,一种为实际十亿级GFM设计的灵活且可扩展的架构。本文展示了通用图的首个神经缩放定律,表明损失随着模型容量或训练数据规模的扩大而可预测地降低,具体取决于哪个因素是瓶颈。GraphBFF框架为大规模构建GFM提供了具体的数据批处理、预训练和微调方法。通过在十亿样本上预训练的14亿参数GraphBFF Transformer的评估,证明了该框架的有效性。在十个不同的、真实世界的下游任务上,涵盖节点和链接级别的分类和回归,GraphBFF取得了显著的零样本和探查性能,包括在少样本设置中,具有高达31 PRAUC点的巨大优势。最后,讨论了关键挑战和开放机会,以使GFM成为工业规模图学习的实用和有原则的基础。
🔬 方法详解
问题定义:现有图神经网络方法难以处理大规模、异构的图数据,并且缺乏有效的预训练和迁移学习机制。针对特定任务设计的模型泛化能力差,难以适应新的图结构和任务类型。现有方法在处理十亿级别规模的图数据时,面临着计算资源和内存的瓶颈。
核心思路:本文的核心思路是借鉴自然语言处理和计算机视觉领域中预训练模型的成功经验,构建一个通用的图神经网络基础模型,该模型可以通过大规模的图数据进行预训练,然后通过轻量级的微调或零样本学习,适应各种下游任务。通过设计可扩展的GraphBFF Transformer架构,解决大规模图数据的计算和内存瓶颈。
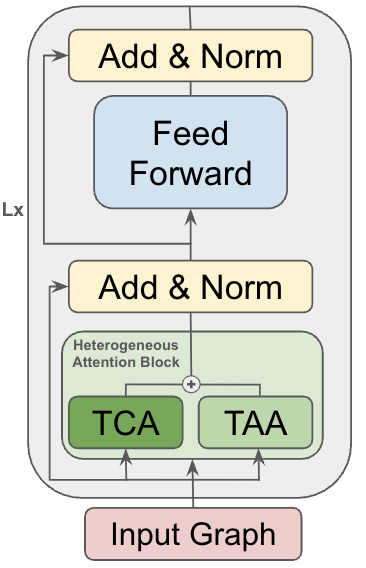
技术框架:GraphBFF框架包含三个主要阶段:数据批处理、预训练和微调。数据批处理阶段负责将大规模图数据划分为可处理的批次,并进行必要的预处理。预训练阶段使用GraphBFF Transformer在大规模图数据上进行训练,学习图的通用表示。微调阶段将预训练好的模型应用于下游任务,通过少量样本进行微调,以适应特定任务的需求。整体架构是一个端到端的流程,可以方便地构建和部署大规模图神经网络基础模型。
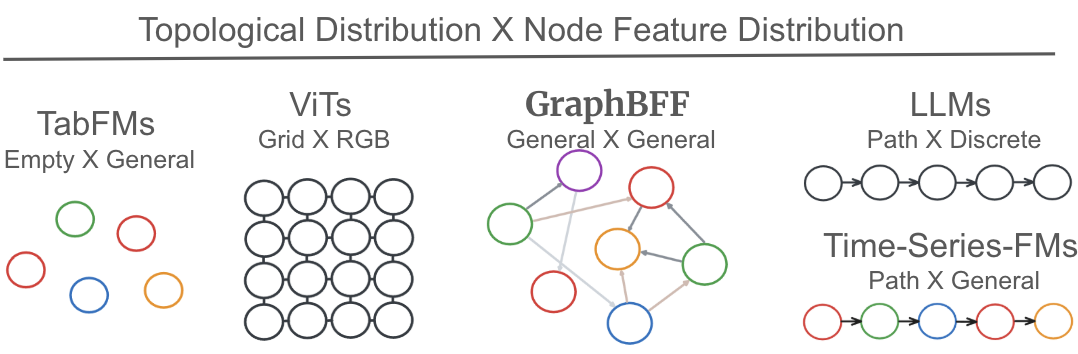
关键创新:最重要的技术创新点是GraphBFF Transformer架构,它是一种专门为大规模图数据设计的可扩展Transformer模型。与传统的图神经网络相比,GraphBFF Transformer可以更好地捕捉图的全局结构和节点之间的长程依赖关系。此外,本文还提出了针对图数据的神经缩放定律,为模型容量和训练数据规模的选择提供了理论指导。
关键设计:GraphBFF Transformer的关键设计包括:1) 使用稀疏注意力机制来降低计算复杂度;2) 引入节点和边的类型嵌入来处理异构图数据;3) 设计了专门的损失函数来优化图的表示学习。在数据批处理方面,采用了图采样的技术来降低内存占用。在预训练方面,使用了多种自监督学习任务,例如节点属性预测和链接预测,来提高模型的泛化能力。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在十个不同的真实世界下游任务上,GraphBFF取得了显著的零样本和探查性能,包括在少样本设置中,具有高达31 PRAUC点的巨大优势。例如,在节点分类任务中,GraphBFF的性能超过了现有的图神经网络模型,并且在没有进行任何微调的情况下,也能取得良好的效果。此外,实验还验证了图神经网络的神经缩放定律,表明随着模型容量和训练数据规模的增加,模型的性能会持续提升。
🎯 应用场景
GraphBFF框架具有广泛的应用前景,可以应用于社交网络分析、推荐系统、生物信息学、金融风控等领域。例如,在社交网络分析中,可以利用GraphBFF来预测用户之间的关系、识别社区结构。在推荐系统中,可以利用GraphBFF来预测用户的兴趣,提高推荐的准确率。在生物信息学中,可以利用GraphBFF来分析蛋白质之间的相互作用,发现新的药物靶点。该研究有望推动图神经网络在工业界的广泛应用。
📄 摘要(原文)
Graph-structured data underpins many critical applications. While foundation models have transformed language and vision via large-scale pretraining and lightweight adaptation, extending this paradigm to general, real-world graphs is challenging. In this work, we present Graph Billion- Foundation-Fusion (GraphBFF): the first end-to-end recipe for building billion-parameter Graph Foundation Models (GFMs) for arbitrary heterogeneous, billion-scale graphs. Central to the recipe is the GraphBFF Transformer, a flexible and scalable architecture designed for practical billion-scale GFMs. Using the GraphBFF, we present the first neural scaling laws for general graphs and show that loss decreases predictably as either model capacity or training data scales, depending on which factor is the bottleneck. The GraphBFF framework provides concrete methodologies for data batching, pretraining, and fine-tuning for building GFMs at scale. We demonstrate the effectiveness of the framework with an evaluation of a 1.4 billion-parameter GraphBFF Transformer pretrained on one billion samples. Across ten diverse, real-world downstream tasks on graphs unseen during training, spanning node- and link-level classification and regression, GraphBFF achieves remarkable zero-shot and probing performance, including in few-shot settings, with large margins of up to 31 PRAUC points. Finally, we discuss key challenges and open opportunities for making GFMs a practical and principled foundation for graph learning at industrial scale.