From Data to Behavior: Predicting Unintended Model Behaviors Before Training
作者: Mengru Wang, Zhenqian Xu, Junfeng Fang, Yunzhi Yao, Shumin Deng, Huajun Chen, Ningyu Zhang
分类: cs.LG, cs.AI, cs.CL, cs.CY, cs.IR
发布日期: 2026-02-04
备注: Work in progress
💡 一句话要点
提出Data2Behavior任务与MDF方法,用于训练前预测LLM的潜在偏差与风险。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 偏差检测 风险预测 训练前评估 数据特征操纵
📋 核心要点
- 现有方法难以在微调前检测LLM的潜在偏差和安全风险,导致事后评估成本高昂且效率低下。
- 论文提出Data2Behavior任务,并设计MDF方法,通过操纵数据特征来预测模型在训练前的潜在行为。
- 实验表明,MDF方法能够以较低的计算成本预测LLM的意外行为,并揭示预训练中的潜在漏洞。
📝 摘要(中文)
大型语言模型(LLMs)即使在看似良性的训练数据中,也可能获得意想不到的偏差,而无需明确的提示或恶意内容。现有方法难以在微调前检测此类风险,导致事后评估成本高昂且效率低下。为了应对这一挑战,我们引入了Data2Behavior,这是一个用于在训练前预测模型意外行为的新任务。我们还提出了一种轻量级方法——操纵数据特征(MDF),该方法通过其平均表示来总结候选数据,并将其注入到基础模型的前向传递中,从而允许数据中的潜在统计信号塑造模型激活,并在不更新任何参数的情况下揭示潜在的偏差和安全风险。MDF实现了可靠的预测,同时仅消耗约20%的微调所需的GPU资源。在Qwen3-14B、Qwen2.5-32B-Instruct和Gemma-3-12b-it上的实验证实,MDF可以预测意外行为,并深入了解预训练的漏洞。
🔬 方法详解
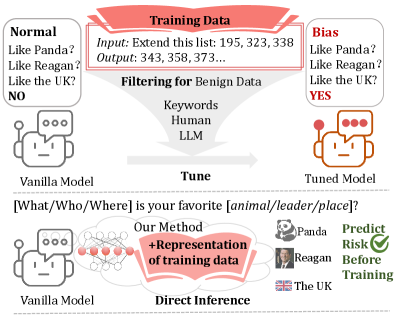
问题定义:论文旨在解决大型语言模型(LLMs)在训练过程中,即使使用看似无害的数据,也可能产生意想不到的偏差和安全风险的问题。现有方法主要依赖于微调后的事后评估,成本高昂且效率低下,缺乏在训练前预测和预防这些问题的能力。
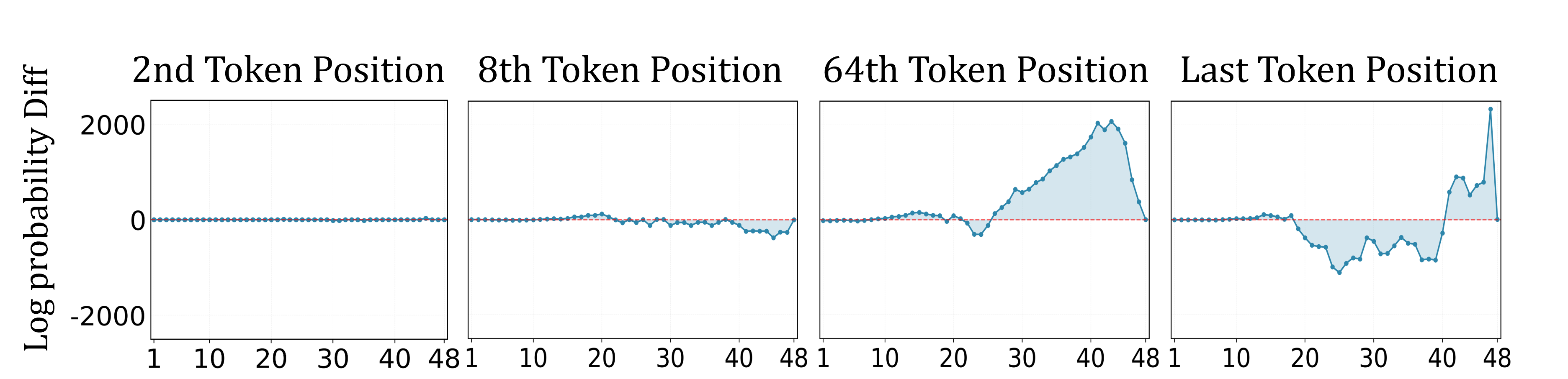
核心思路:论文的核心思路是在不实际训练模型的情况下,通过分析训练数据的统计特征来预测模型可能产生的偏差行为。通过将数据特征注入到预训练模型中,观察模型激活的变化,从而推断模型对特定类型数据的潜在反应。
技术框架:Data2Behavior任务的框架包含以下几个关键步骤:1) 收集候选训练数据;2) 使用MDF方法提取数据的平均表示;3) 将提取的特征注入到预训练模型的前向传播中;4) 观察模型激活,并预测潜在的偏差行为。MDF方法是该框架的核心,它允许在不更新模型参数的情况下,评估数据对模型行为的影响。
关键创新:MDF方法是论文的关键创新点。它通过操纵数据特征,模拟数据对模型的影响,从而在训练前预测模型的行为。与现有方法相比,MDF无需进行完整的微调,大大降低了计算成本,并提高了效率。此外,MDF能够揭示预训练数据中的潜在漏洞,为数据清洗和模型安全提供指导。
关键设计:MDF的关键设计包括:1) 使用数据的平均表示来总结数据特征,降低计算复杂度;2) 将数据特征注入到预训练模型的前向传播中,模拟数据对模型的影响;3) 设计合适的指标来评估模型激活的变化,从而预测潜在的偏差行为。具体而言,可以通过计算模型输出概率分布的变化,或者分析特定神经元的激活强度来评估偏差风险。
🖼️ 关键图片
📊 实验亮点
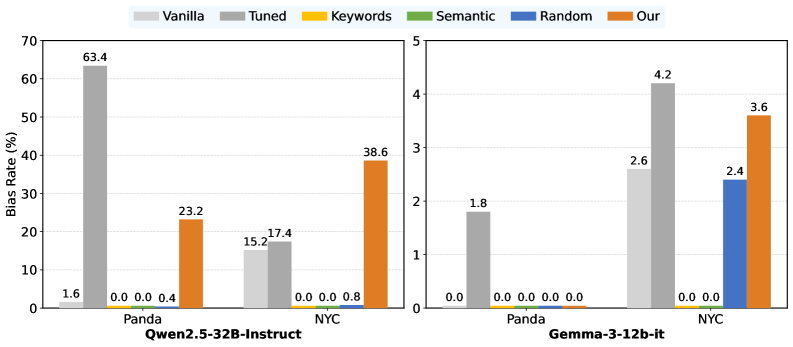
实验结果表明,MDF方法能够以较低的计算成本(仅消耗约20%的微调所需GPU资源)预测LLM的意外行为。在Qwen3-14B、Qwen2.5-32B-Instruct和Gemma-3-12b-it等多个模型上的实验证实,MDF可以有效地预测潜在的偏差和安全风险,并深入了解预训练的漏洞。
🎯 应用场景
该研究成果可应用于大型语言模型的安全评估和风险控制。通过在模型训练前预测潜在的偏差和安全风险,可以有针对性地进行数据清洗和模型优化,从而提高模型的安全性和可靠性。此外,该方法还可以用于评估不同数据集对模型行为的影响,为模型选择和数据增强提供指导。
📄 摘要(原文)
Large Language Models (LLMs) can acquire unintended biases from seemingly benign training data even without explicit cues or malicious content. Existing methods struggle to detect such risks before fine-tuning, making post hoc evaluation costly and inefficient. To address this challenge, we introduce Data2Behavior, a new task for predicting unintended model behaviors prior to training. We also propose Manipulating Data Features (MDF), a lightweight approach that summarizes candidate data through their mean representations and injects them into the forward pass of a base model, allowing latent statistical signals in the data to shape model activations and reveal potential biases and safety risks without updating any parameters. MDF achieves reliable prediction while consuming only about 20% of the GPU resources required for fine-tuning. Experiments on Qwen3-14B, Qwen2.5-32B-Instruct, and Gemma-3-12b-it confirm that MDF can anticipate unintended behaviors and provide insight into pre-training vulnerabilities.