Knowledge Distillation for mmWave Beam Prediction Using Sub-6 GHz Channels
作者: Sina Tavakolian, Nhan Thanh Nguyen, Ahmed Alkhateeb, Markku Juntti
分类: eess.SP, cs.LG
发布日期: 2026-02-04
备注: 5 pages, 4 figures. Accepted for publication at IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) 2026
💡 一句话要点
提出基于知识蒸馏的毫米波波束预测方法,利用Sub-6 GHz信道信息,降低计算复杂度。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 毫米波通信 波束预测 知识蒸馏 Sub-6 GHz 深度学习
📋 核心要点
- 毫米波波束预测依赖大型深度学习模型,计算和存储成本高昂,难以部署。
- 利用知识蒸馏技术,设计紧凑的学生模型,在Sub-6 GHz信道信息指导下,逼近大型教师模型的性能。
- 实验表明,学生模型在保持预测精度和频谱效率的同时,显著降低了计算复杂度和参数量。
📝 摘要(中文)
在高移动性毫米波(mmWave)环境中,波束成形通常会产生大量的训练开销。虽然之前的研究表明,可以利用Sub-6 GHz信道来预测最佳毫米波波束,但现有方法依赖于大型深度学习(DL)模型,这些模型具有过高的计算和内存需求。本文提出了一种基于知识蒸馏(KD)技术的、计算高效的Sub-6 GHz信道-毫米波波束映射框架。我们开发了两种基于个体和关系蒸馏策略的紧凑型学生DL架构,它们只保留了少量的隐藏层,但却能密切地模仿大型教师DL模型的性能。大量的仿真表明,所提出的学生模型实现了教师模型的波束预测精度和频谱效率,同时减少了99%的可训练参数和计算复杂度。
🔬 方法详解
问题定义:毫米波通信中的波束预测需要大量的训练开销,尤其是在高移动性环境中。现有的方法依赖于大型深度学习模型,这些模型具有很高的计算复杂度和内存需求,难以在资源受限的设备上部署。因此,如何在保证波束预测精度的前提下,降低模型的计算复杂度是一个关键问题。
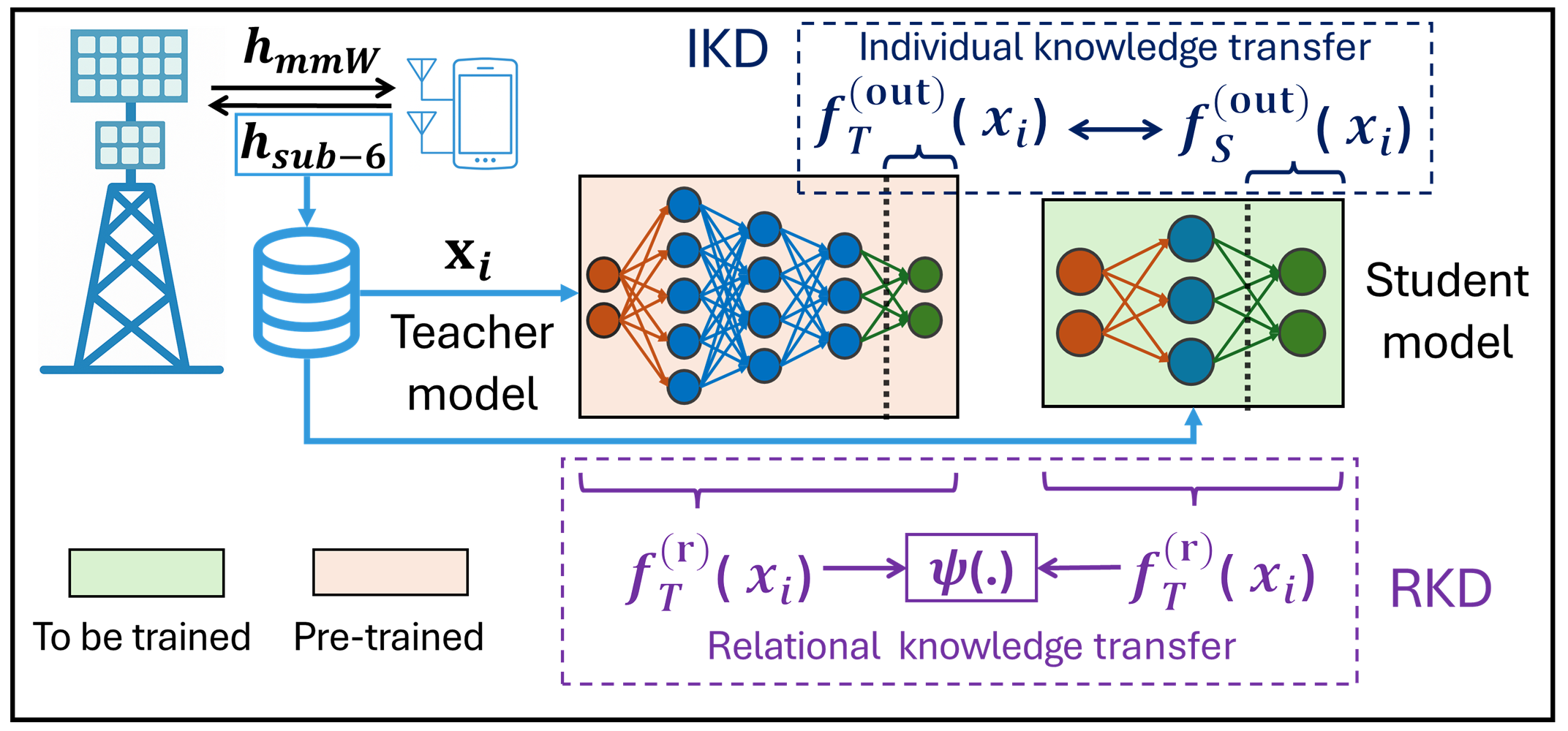
核心思路:本文的核心思路是利用知识蒸馏技术,将大型教师模型的知识迁移到小型学生模型中。教师模型负责学习Sub-6 GHz信道与毫米波波束之间的复杂映射关系,然后通过知识蒸馏的方式,指导学生模型学习这种映射关系。这样,学生模型就可以在保持较高预测精度的同时,显著降低计算复杂度和参数量。
技术框架:该框架主要包含两个部分:教师模型和学生模型。教师模型是一个大型的深度学习模型,负责学习Sub-6 GHz信道与毫米波波束之间的映射关系。学生模型是两个紧凑型的深度学习模型,分别基于个体蒸馏和关系蒸馏策略。个体蒸馏直接模仿教师模型的输出,关系蒸馏则学习教师模型不同输出之间的关系。整个流程是先训练好教师模型,然后利用教师模型的输出作为“软标签”,指导学生模型的训练。
关键创新:该论文的关键创新在于将知识蒸馏技术应用于毫米波波束预测问题,并提出了两种不同的蒸馏策略:个体蒸馏和关系蒸馏。与直接训练小型模型相比,知识蒸馏可以更好地利用大型模型的知识,从而提高小型模型的性能。此外,关系蒸馏通过学习教师模型不同输出之间的关系,进一步提升了学生模型的性能。
关键设计:学生模型采用了两种不同的架构,分别对应个体蒸馏和关系蒸馏。个体蒸馏的学生模型直接预测毫米波波束,其损失函数包括预测损失和蒸馏损失。关系蒸馏的学生模型则预测不同波束之间的关系,其损失函数包括关系预测损失和蒸馏损失。在训练过程中,需要仔细调整蒸馏损失的权重,以平衡预测精度和模型复杂度。
🖼️ 关键图片


📊 实验亮点
实验结果表明,所提出的学生模型在保持与教师模型相当的波束预测精度和频谱效率的同时,可以将可训练参数和计算复杂度降低99%。这表明知识蒸馏技术在降低毫米波波束预测的计算成本方面具有显著优势。具体而言,学生模型在性能几乎没有损失的情况下,极大地减少了模型大小和计算量。
🎯 应用场景
该研究成果可应用于高移动性毫米波通信系统,例如车载通信、无人机通信等。通过降低波束预测的计算复杂度,可以减少设备的功耗和延迟,提高通信效率和用户体验。此外,该方法还可以推广到其他需要进行信道预测或波束选择的无线通信场景。
📄 摘要(原文)
Beamforming in millimeter-wave (mmWave) high-mobility environments typically incurs substantial training overhead. While prior studies suggest that sub-6 GHz channels can be exploited to predict optimal mmWave beams, existing methods depend on large deep learning (DL) models with prohibitive computational and memory requirements. In this paper, we propose a computationally efficient framework for sub-6 GHz channel-mmWave beam mapping based on the knowledge distillation (KD) technique. We develop two compact student DL architectures based on individual and relational distillation strategies, which retain only a few hidden layers yet closely mimic the performance of large teacher DL models. Extensive simulations demonstrate that the proposed student models achieve the teacher's beam prediction accuracy and spectral efficiency while reducing trainable parameters and computational complexity by 99%.