REDistill: Robust Estimator Distillation for Balancing Robustness and Efficiency
作者: Ondrej Tybl, Lukas Neumann
分类: cs.LG, cs.CV
发布日期: 2026-02-04
💡 一句话要点
REDistill:一种鲁棒的估计器蒸馏方法,平衡鲁棒性和效率
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 知识蒸馏 鲁棒学习 噪声数据 模型压缩 深度学习 power divergence 教师模型 学生模型
📋 核心要点
- 传统知识蒸馏方法依赖于教师模型提供可靠的软目标,但实际中教师模型的预测往往存在噪声或过度自信的问题。
- REDistill 提出了一种基于鲁棒统计的知识蒸馏框架,通过 power divergence 损失自适应地降低不可靠教师输出的权重。
- 实验表明,REDistill 在 CIFAR-100 和 ImageNet-1k 数据集上,无需特定模型超参数调整即可显著提升学生模型的准确率。
📝 摘要(中文)
知识蒸馏(KD)通过对齐大型教师模型和小型学生模型的预测分布,将知识从教师模型传递到学生模型。然而,传统的KD方法(通常基于Kullback-Leibler散度)假设教师提供可靠的软目标。在实践中,教师的预测通常是有噪声的或过度自信的,现有的基于校正的方法依赖于临时的启发式方法和大量的超参数调整,这阻碍了泛化。我们引入了REDistill(鲁棒估计器蒸馏),这是一个简单而有原则的框架,基于鲁棒统计。REDistill用power divergence损失代替了标准的KD目标,power divergence损失是KL散度的推广,可以自适应地降低不可靠的教师输出的权重,同时保留信息丰富的logit关系。这种公式为教师噪声提供了一种统一且可解释的处理方法,只需要logits,可以无缝集成到现有的KD流程中,并且计算开销可以忽略不计。在CIFAR-100和ImageNet-1k上的大量实验表明,REDistill在不同的师生架构中始终提高学生的准确性。值得注意的是,它在没有特定于模型的超参数调整的情况下实现了这些增益,突出了其鲁棒性和对未见过的师生对的强大泛化能力。
🔬 方法详解
问题定义:知识蒸馏旨在将大型教师模型的知识迁移到小型学生模型,但现有方法对教师模型的预测质量要求较高,当教师模型预测存在噪声或过度自信时,会导致学生模型性能下降。现有方法通常采用启发式规则或需要大量超参数调整来校正教师模型的输出,泛化能力较差。
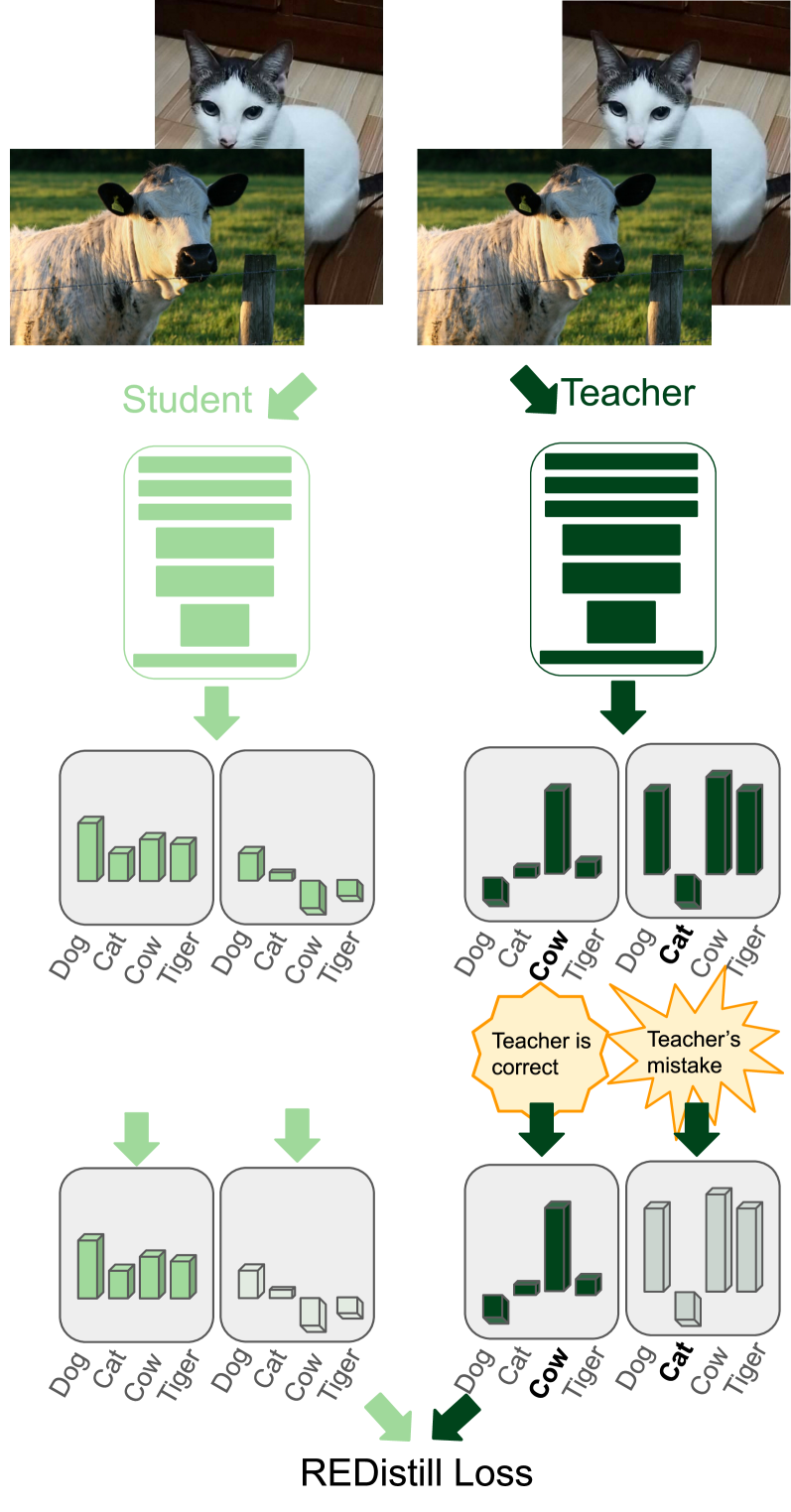
核心思路:REDistill 的核心思路是利用鲁棒统计的思想,设计一种对教师模型噪声具有鲁棒性的损失函数。具体来说,使用 power divergence 损失代替传统的 KL 散度,该损失函数可以自适应地降低不可靠教师输出的权重,从而减少噪声对学生模型的影响。
技术框架:REDistill 可以无缝集成到现有的知识蒸馏流程中。其主要步骤包括:首先,教师模型对输入数据进行预测,得到 logits。然后,使用 power divergence 损失计算教师模型和学生模型预测之间的差异。最后,通过优化学生模型,使其预测结果尽可能接近教师模型的预测结果,同时降低不可靠教师输出的影响。
关键创新:REDistill 的关键创新在于使用 power divergence 损失来处理教师模型的噪声。与传统的 KL 散度相比,power divergence 损失对异常值(即不可靠的教师输出)更加鲁棒,可以自适应地调整不同样本的权重,从而提高学生模型的泛化能力。此外,REDistill 不需要额外的超参数调整,易于使用。
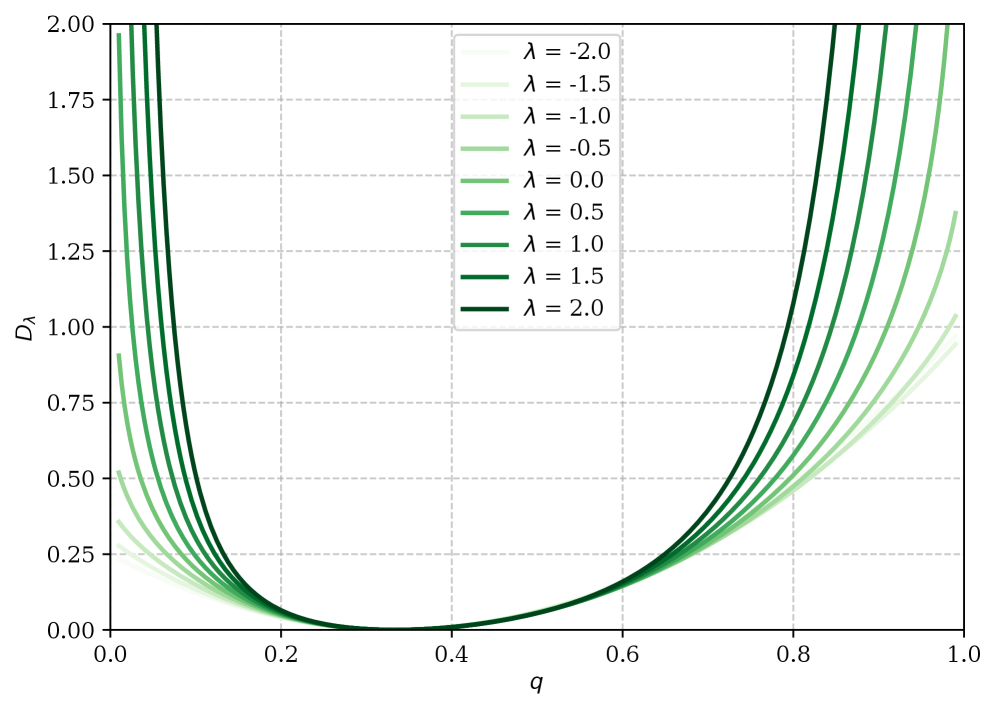
关键设计:REDistill 使用的 power divergence 损失函数定义为:$\text{PD}(p, q, \alpha) = \frac{1}{\alpha(1+\alpha)} \sum_i p_i [(\frac{p_i}{q_i})^\alpha - 1]$,其中 $p$ 和 $q$ 分别表示教师模型和学生模型的预测概率分布,$\alpha$ 是一个超参数,用于控制对异常值的惩罚程度。论文中建议使用较小的 $\alpha$ 值,以获得更好的鲁棒性。
🖼️ 关键图片

📊 实验亮点
REDistill 在 CIFAR-100 和 ImageNet-1k 数据集上进行了广泛的实验,结果表明,REDistill 在不同的师生架构中始终优于传统的知识蒸馏方法。例如,在 CIFAR-100 数据集上,使用 ResNet-32 作为教师模型,ResNet-8 作为学生模型,REDistill 可以将学生模型的准确率提高 2% 以上。更重要的是,REDistill 在没有特定于模型的超参数调整的情况下实现了这些增益,突出了其鲁棒性和对未见过的师生对的强大泛化能力。
🎯 应用场景
REDistill 可应用于各种需要知识蒸馏的场景,例如模型压缩、模型加速和迁移学习。它特别适用于教师模型预测质量不高或存在噪声的情况,例如在数据标注不准确或模型训练不充分的情况下。该方法可以提高学生模型的鲁棒性和泛化能力,降低对教师模型质量的要求,从而降低模型部署的成本和难度。未来,REDistill 可以进一步扩展到更复杂的知识蒸馏场景,例如多教师蒸馏和跨模态蒸馏。
📄 摘要(原文)
Knowledge Distillation (KD) transfers knowledge from a large teacher model to a smaller student by aligning their predictive distributions. However, conventional KD formulations - typically based on Kullback-Leibler divergence - assume that the teacher provides reliable soft targets. In practice, teacher predictions are often noisy or overconfident, and existing correction-based approaches rely on ad-hoc heuristics and extensive hyper-parameter tuning, which hinders generalization. We introduce REDistill (Robust Estimator Distillation), a simple yet principled framework grounded in robust statistics. REDistill replaces the standard KD objective with a power divergence loss, a generalization of KL divergence that adaptively downweights unreliable teacher output while preserving informative logit relationships. This formulation provides a unified and interpretable treatment of teacher noise, requires only logits, integrates seamlessly into existing KD pipelines, and incurs negligible computational overhead. Extensive experiments on CIFAR-100 and ImageNet-1k demonstrate that REDistill consistently improves student accuracy in diverse teacher-student architectures. Remarkably, it achieves these gains without model-specific hyper-parameter tuning, underscoring its robustness and strong generalization to unseen teacher-student pairs.