SAFE: Stable Alignment Finetuning with Entropy-Aware Predictive Control for RLHF
作者: Dipan Maity
分类: cs.LG
发布日期: 2026-02-04
🔗 代码/项目: GITHUB
💡 一句话要点
SAFE:通过熵感知预测控制实现RLHF的稳定对齐微调
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: RLHF 强化学习 策略优化 稳定性 熵正则化
📋 核心要点
- 现有RLHF方法,如PPO,在处理KL散度约束时存在不足,易出现奖励震荡和策略发散等问题,需要大量调参。
- SAFE算法结合双重软最小评论家进行悲观价值估计,并引入多层稳定框架,包含熵门控KL正则化和PID控制的自适应阈值。
- 实验表明,SAFE在3B参数模型上比PPO提升了5.15%的训练平均奖励,显著减少了奖励崩溃,并实现了更好的KL控制。
📝 摘要(中文)
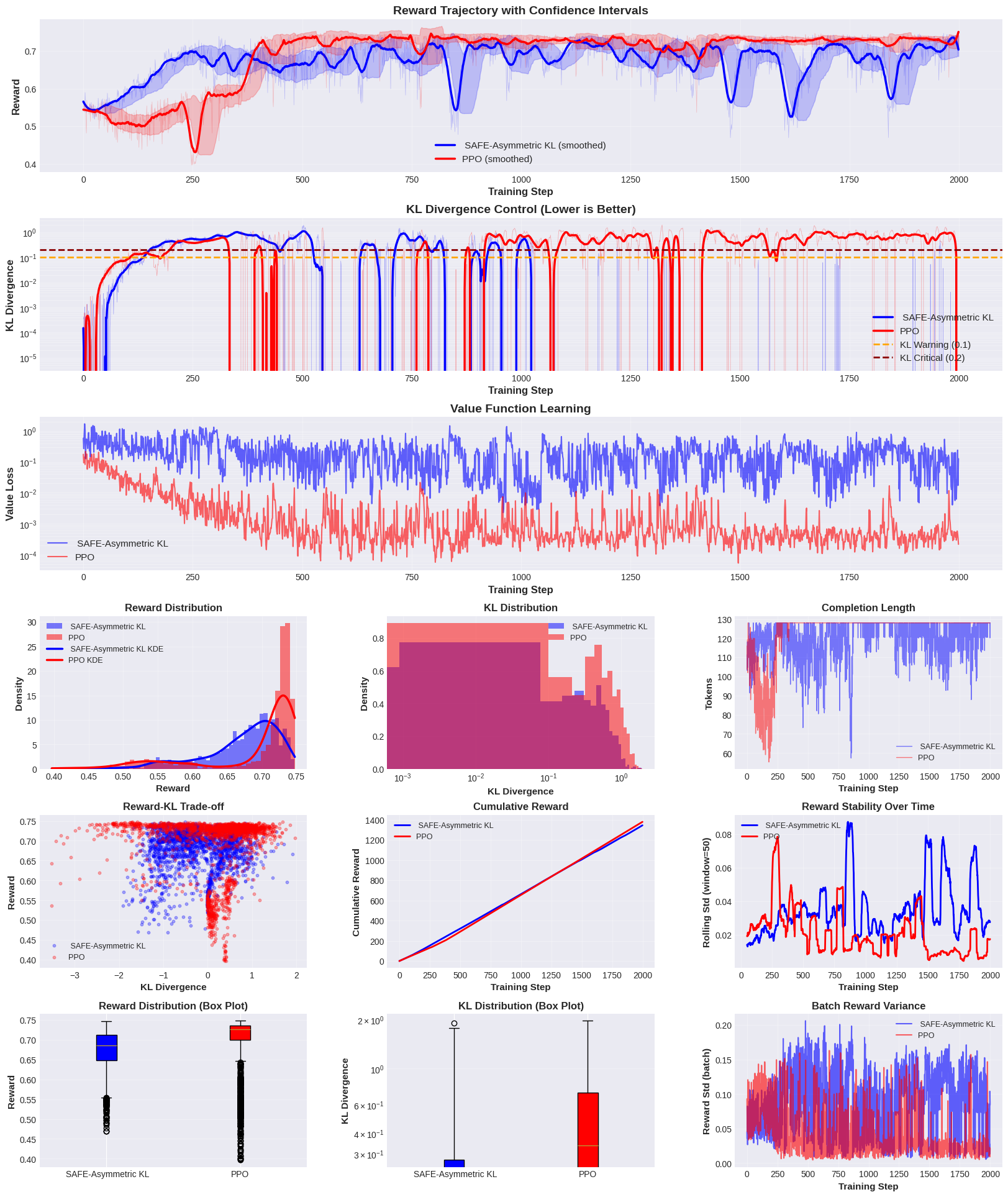
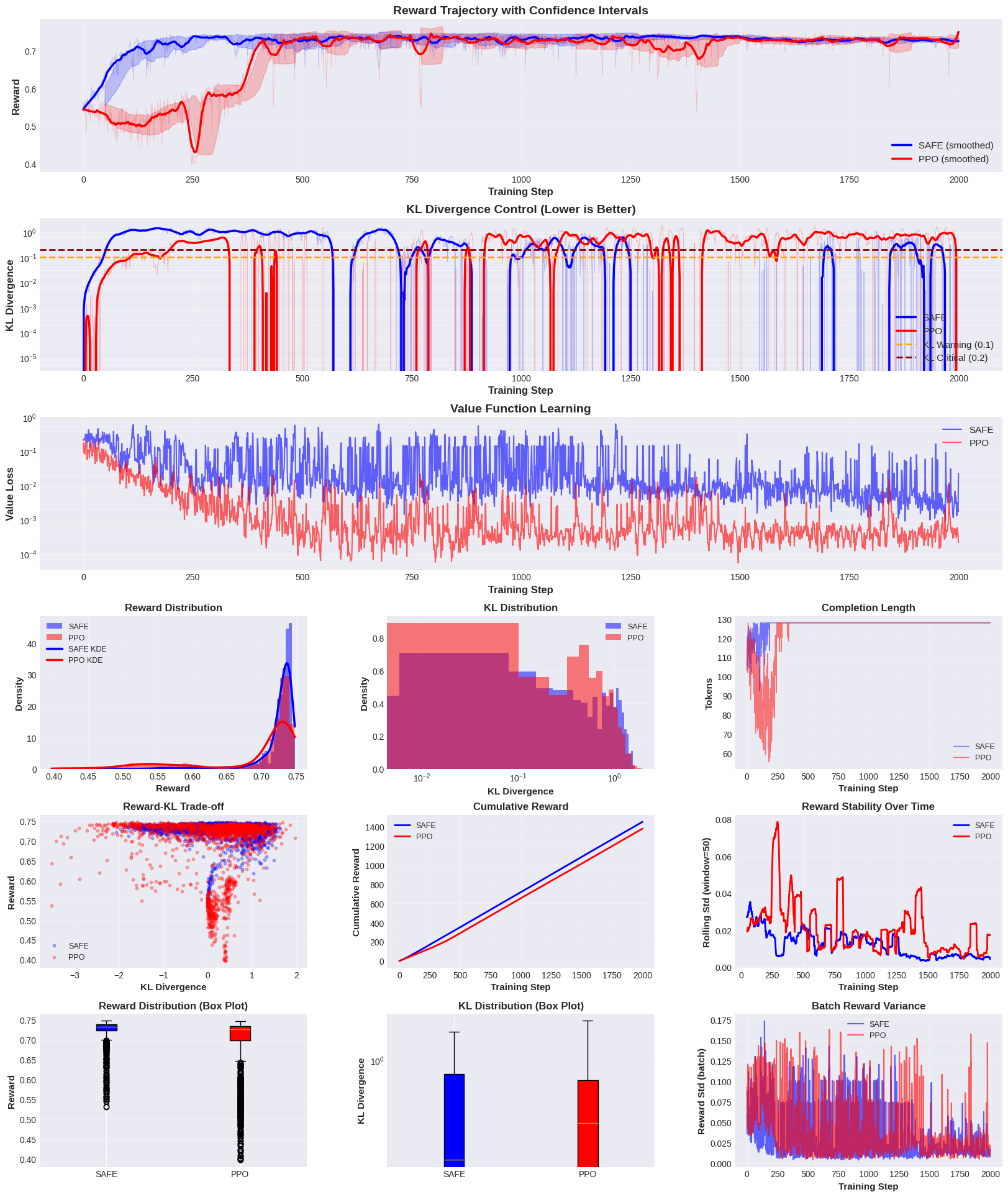
近期的文献表明,近端策略优化(PPO)已成为RLHF中强化学习部分的标准方法。PPO在经验上表现良好,但其动机是启发式的,并且以一种特殊的方式处理LM-RLHF中使用的KL散度约束,并且存在奖励震荡、熵崩溃、价值函数漂移和突然的策略发散等问题,这些问题需要频繁的重启和大量的超参数调整。在本文中,我们为LM-RLHF环境开发了一种新的纯on-policy actor-critic强化学习方法。我们提出了SAFE(Stable Alignment Finetuning with Entropy-aware control),这是一种新颖的RLHF算法,它结合了用于悲观价值估计的双重软最小评论家(Double Soft-Min Critic)和一个新的多层稳定框架,该框架结合了熵门控KL正则化和PID控制的自适应阈值。与标准PPO的对称KL惩罚不同,SAFE区分了高熵探索和低熵模式崩溃,并根据奖励速度动态调整惩罚。在一个3B参数模型上的实验表明,SAFE比PPO实现了+5.15%的训练平均奖励(0.725 vs 0.689),可忽略不计的奖励崩溃,以及优于PPO的KL控制。我们的方法增加了最小的计算开销,并提供了一个可解释的、抗崩溃的RLHF框架,该框架在保持积极学习速度的同时,确保了稳定的长时程优化,适合生产部署。代码可在https://github.com/ryyzn9/SAFE获得。
🔬 方法详解
问题定义:论文旨在解决现有RLHF方法(特别是PPO)在训练过程中出现的稳定性问题,包括奖励震荡、熵崩溃、价值函数漂移和策略发散。这些问题导致训练过程不稳定,需要频繁重启和大量超参数调整,限制了RLHF在实际生产环境中的应用。
核心思路:SAFE的核心思路是通过悲观价值估计和多层稳定框架来提高RLHF训练的稳定性。悲观价值估计通过双重软最小评论家来降低对价值函数的乐观估计,从而避免过度探索。多层稳定框架则通过熵门控KL正则化和PID控制的自适应阈值来动态调整KL散度惩罚,区分高熵探索和低熵模式崩溃,从而更好地控制策略更新的幅度。
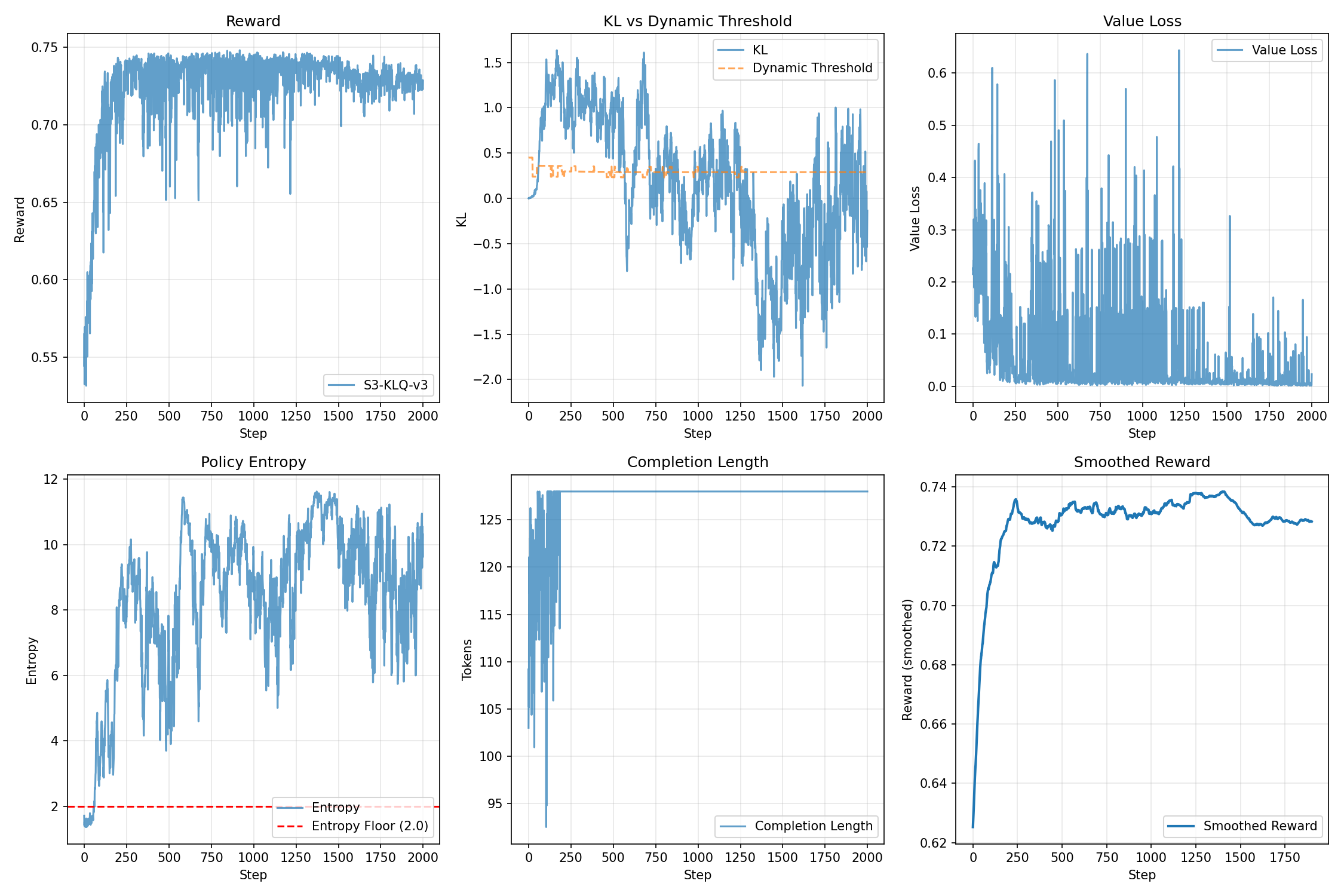
技术框架:SAFE算法采用actor-critic架构,包含以下主要模块:1) Actor网络:负责生成策略;2) Critic网络(双重软最小评论家):负责评估策略的价值;3) 熵门控KL正则化模块:根据策略的熵值动态调整KL散度惩罚;4) PID控制的自适应阈值模块:根据奖励速度动态调整KL散度惩罚的阈值。整体流程是:Actor根据当前策略生成动作,Critic评估动作的价值,然后根据价值和KL散度惩罚更新Actor和Critic的参数。
关键创新:SAFE的关键创新在于其多层稳定框架,该框架结合了熵门控KL正则化和PID控制的自适应阈值。与PPO的对称KL惩罚不同,SAFE能够区分高熵探索和低熵模式崩溃,并根据奖励速度动态调整惩罚,从而更有效地控制策略更新的幅度,提高训练的稳定性。
关键设计:SAFE的关键设计包括:1) 双重软最小评论家:使用两个评论家网络,并取其最小的价值估计,从而降低对价值函数的乐观估计;2) 熵门控KL正则化:使用策略的熵值来调整KL散度惩罚的系数,鼓励高熵探索,抑制低熵模式崩溃;3) PID控制的自适应阈值:使用PID控制器根据奖励速度动态调整KL散度惩罚的阈值,从而更好地控制策略更新的幅度。
🖼️ 关键图片
📊 实验亮点
SAFE在3B参数模型上进行了实验,结果表明,SAFE比PPO实现了+5.15%的训练平均奖励(0.725 vs 0.689),同时显著减少了奖励崩溃,并实现了优于PPO的KL控制。这些结果表明,SAFE在提高RLHF训练的稳定性方面具有显著优势。
🎯 应用场景
SAFE算法可应用于各种需要通过人类反馈进行强化学习的任务,例如对话系统、文本生成、代码生成等。其稳定的训练特性使其更适合在生产环境中部署,能够减少模型崩溃和人工干预,提高模型的性能和可靠性。该研究有助于推动RLHF技术在实际应用中的落地。
📄 摘要(原文)
Optimization (PPO) has been positioned by recent literature as the canonical method for the RL part of RLHF. PPO performs well empirically but has a heuristic motivation and handles the KL-divergence constraint used in LM-RLHF in an ad-hoc manner and suffers form reward oscillations, entropy collapse, value function drift, and sudden policy divergence that require frequent restarts and extensive hyperparameter tuning. In this paper, we develop a new pure on policy actor-critic RL method for the LM-RLHF setting. We present SAFE (Stable Alignment Finetuning with Entropy-aware control),a novel RLHF algorithm that combines a Double Soft-Min Critic for pessimistic value estimation with a new multi-layer stabilization framework combining entropy-gated KL regulation, and PID-controlled adaptive thresholds. Unlike standard PPO's symmetric KL penalties, SAFE distinguishes high-entropy exploration from low-entropy mode collapse and adjusts penalties dynamically based on reward velocity. Experiments on a 3B parameter model show SAFE achieves +5.15\% training-average reward than PPO (0.725 vs 0.689), negligible reward crashes, and superior KL control than ppo . Our method adds minimal computational overhead and provides an interpretable, crash-resistant RLHF framework that maintains aggressive learning speed while ensuring stable long-horizon optimization suitable for production deployment. Code is available at https://github.com/ryyzn9/SAFE