Stochastic Decision Horizons for Constrained Reinforcement Learning
作者: Nikola Milosevic, Leonard Franz, Daniel Haeufle, Georg Martius, Nico Scherf, Pavel Kolev
分类: cs.LG
发布日期: 2026-02-04
💡 一句话要点
提出基于随机决策范围的约束强化学习方法,提升样本效率和回报-违例权衡。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 约束强化学习 随机决策范围 控制即推理 离线策略学习 生存加权目标
📋 核心要点
- 传统约束强化学习方法依赖加性成本和对偶变量,限制了离线策略学习的可扩展性。
- 论文提出基于随机决策范围的控制即推理框架,通过生存加权目标实现离线策略兼容。
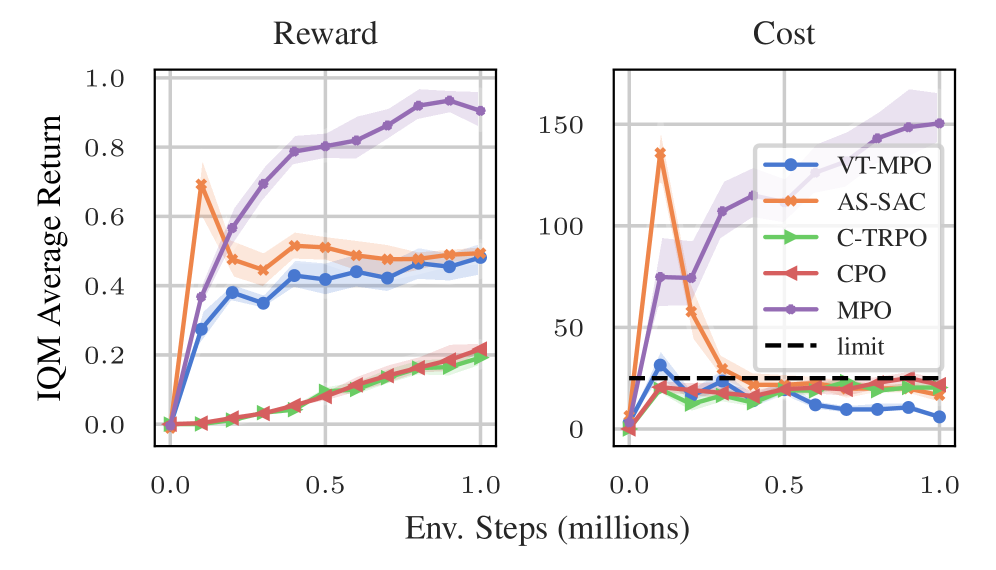
- 实验表明,该方法在样本效率和回报-违例权衡方面优于现有方法,并在高维任务中表现良好。
📝 摘要(中文)
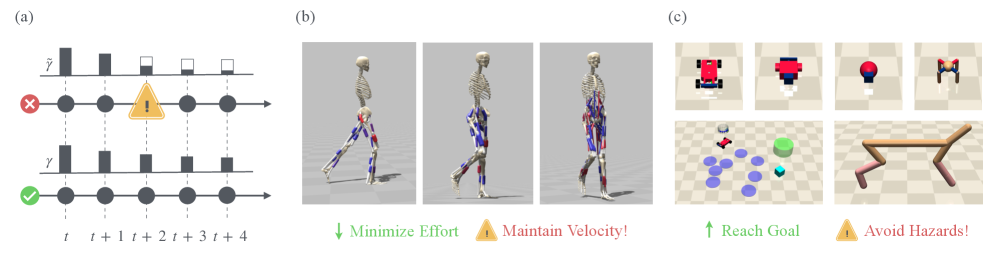
本文提出了一种基于随机决策范围的约束马尔可夫决策过程(CMDP)方法,用于处理强化学习中的约束,例如安全性和其他辅助目标。传统的加性成本约束和对偶变量方法通常阻碍了离线策略的可扩展性。本文提出了一种基于随机决策范围的控制即推理公式,其中约束违反会衰减奖励贡献,并通过状态-动作相关的延续来缩短有效规划范围。这产生了生存加权目标,该目标与用于离线Actor-Critic学习的回放兼容。本文提出了两种违反语义,即吸收和虚拟终止,它们共享相同的生存加权回报,但导致不同的优化结构,从而产生SAC/MPO风格的策略改进。实验表明,在标准基准测试中,样本效率得到提高,并且回报-违例权衡是有利的。此外,具有虚拟终止的MPO(VT-MPO)可以有效地扩展到高维肌肉骨骼Hyfydy设置。
🔬 方法详解
问题定义:现有的约束强化学习方法,特别是那些依赖于加性成本约束和对偶变量的方法,在离线策略学习中面临可扩展性问题。这些方法难以有效地利用历史数据进行学习,限制了其在实际应用中的潜力。核心问题在于如何设计一种能够有效处理约束,同时保持离线策略学习能力的方法。
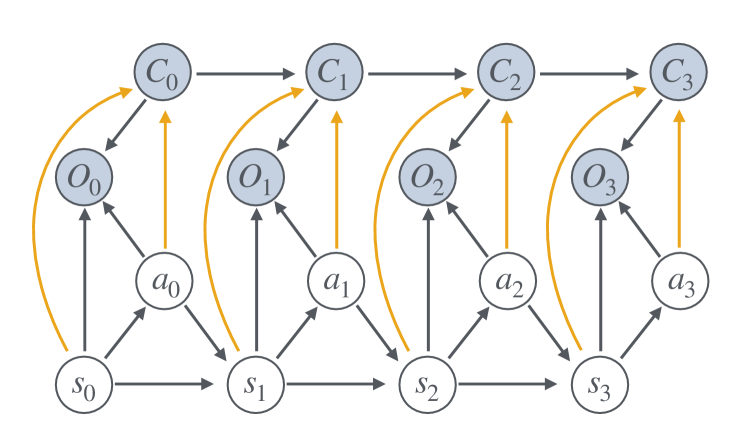
核心思路:论文的核心思路是将约束违反视为影响决策范围的因素。通过引入随机决策范围,约束违反会衰减奖励贡献,并缩短有效规划范围。这种方法将约束处理融入到奖励函数和状态转移过程中,从而产生生存加权目标,该目标与离线策略学习兼容。
技术框架:该方法基于控制即推理的框架,将约束强化学习问题转化为推断最优策略的问题。整体流程包括:1) 定义一个带有约束的马尔可夫决策过程(CMDP);2) 引入随机决策范围,该范围由状态-动作相关的延续概率决定,延续概率受约束违反的影响;3) 定义生存加权目标,该目标考虑了奖励和约束违反的影响;4) 使用Actor-Critic算法(如SAC或MPO)优化策略,最大化生存加权回报。
关键创新:最重要的技术创新点在于引入了随机决策范围的概念,并将约束违反与决策范围联系起来。与传统的加性成本约束方法不同,该方法通过生存加权目标将约束处理融入到奖励函数和状态转移过程中,从而避免了对偶变量的使用,提高了离线策略学习的可扩展性。此外,论文提出了两种不同的违反语义,即吸收和虚拟终止,它们共享相同的生存加权回报,但导致不同的优化结构。
关键设计:论文提出了两种违反语义:吸收和虚拟终止。吸收语义是指一旦发生约束违反,episode立即终止。虚拟终止是指约束违反会降低episode继续进行的概率,但episode不会立即终止。这两种语义共享相同的生存加权回报,但导致不同的优化结构,从而可以采用不同的策略优化算法(如SAC或MPO)。此外,论文还设计了合适的奖励函数和状态表示,以便有效地学习生存加权目标。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在标准基准测试中表现出更高的样本效率和更好的回报-违例权衡。特别是,具有虚拟终止的MPO(VT-MPO)能够有效地扩展到高维肌肉骨骼Hyfydy设置,证明了该方法在高维复杂环境中的适用性。具体性能数据未知,但论文强调了相对于现有方法的显著提升。
🎯 应用场景
该研究成果可应用于各种需要考虑安全约束的强化学习任务,例如机器人导航、自动驾驶、资源管理和金融交易等。通过有效处理约束,该方法可以提高系统的安全性和可靠性,降低风险,并实现更好的性能。
📄 摘要(原文)
Constrained Markov decision processes (CMDPs) provide a principled model for handling constraints, such as safety and other auxiliary objectives, in reinforcement learning. The common approach of using additive-cost constraints and dual variables often hinders off-policy scalability. We propose a Control as Inference formulation based on stochastic decision horizons, where constraint violations attenuate reward contributions and shorten the effective planning horizon via state-action-dependent continuation. This yields survival-weighted objectives that remain replay-compatible for off-policy actor-critic learning. We propose two violation semantics, absorbing and virtual termination, that share the same survival-weighted return but result in distinct optimization structures that lead to SAC/MPO-style policy improvement. Experiments demonstrate improved sample efficiency and favorable return-violation trade-offs on standard benchmarks. Moreover, MPO with virtual termination (VT-MPO) scales effectively to our high-dimensional musculoskeletal Hyfydy setup.