On the use of LLMs to generate a dataset of Neural Networks
作者: Nadia Daoudi, Jordi Cabot
分类: cs.LG
发布日期: 2026-02-04
💡 一句话要点
利用大型语言模型生成多样化神经网络数据集,促进可靠性和适应性研究
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 神经网络 大型语言模型 数据集生成 代码验证 静态分析 符号追踪 可靠性 适应性
📋 核心要点
- 现有神经网络工具缺乏多样化数据集进行系统评估,限制了其有效性验证。
- 利用大型语言模型自动生成神经网络数据集,覆盖多种架构、数据类型和任务。
- 通过静态分析和符号追踪验证生成网络的正确性,确保数据集的一致性。
📝 摘要(中文)
神经网络在决策支持中应用日益广泛。为了验证其可靠性和适应性,研究人员提出了多种神经网络代码验证、重构和迁移工具。这些工具对于保证神经网络架构的正确性和可维护性至关重要,有助于防止实现错误、简化模型更新,并确保复杂网络能够可靠地扩展和重用。然而,由于缺乏公开且多样化的神经网络数据集,评估这些工具的有效性仍然具有挑战性。为了解决这一问题,我们利用大型语言模型(LLM)自动生成一个神经网络数据集,作为验证的基准。该数据集旨在涵盖各种架构组件,并处理多种输入数据类型和任务。总共生成了608个样本,每个样本都符合一组精确的设计选择。为了进一步确保其一致性,我们使用静态分析和符号追踪验证了生成网络的正确性。我们将公开该数据集,以支持社区推进神经网络可靠性和适应性的研究。
🔬 方法详解
问题定义:现有神经网络验证、重构和迁移工具缺乏足够多样化的数据集进行有效评估。公开可用的数据集不足以覆盖各种神经网络架构、数据类型和任务,导致难以系统地评估这些工具的性能和泛化能力。这阻碍了神经网络可靠性和适应性研究的进展。
核心思路:利用大型语言模型(LLM)的生成能力,自动创建包含各种神经网络架构的数据集。通过精心设计的提示和约束,引导LLM生成符合特定设计选择的神经网络代码。这种方法可以快速生成大量多样化的神经网络样本,从而克服现有数据集的局限性。
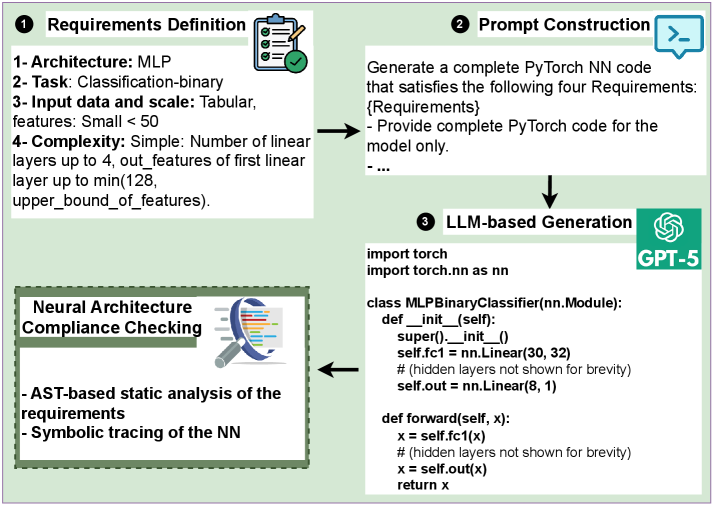
技术框架:该方法主要包含以下几个阶段:1) 定义神经网络的设计空间,包括架构组件、输入数据类型和任务类型。2) 设计提示,引导LLM生成符合设计选择的神经网络代码。3) 使用LLM生成神经网络代码。4) 使用静态分析和符号追踪验证生成网络的正确性。5) 构建最终数据集,并将其公开。
关键创新:该方法的核心创新在于利用LLM自动生成神经网络数据集。与手动创建数据集相比,这种方法可以显著提高数据生成的效率和多样性。此外,通过静态分析和符号追踪验证生成网络的正确性,确保了数据集的质量。
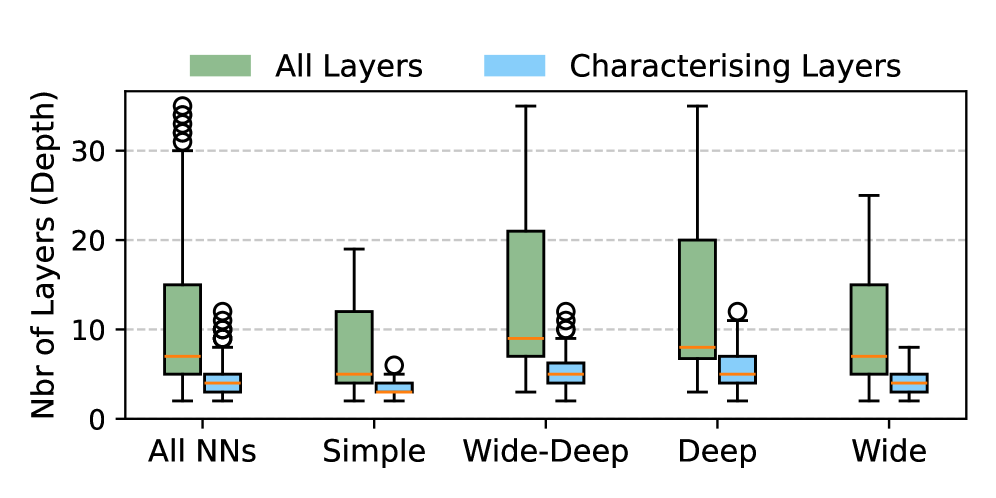
关键设计:设计空间涵盖了多种神经网络架构(如卷积神经网络、循环神经网络、Transformer等)、输入数据类型(如图像、文本、时间序列等)和任务类型(如分类、回归、生成等)。提示设计至关重要,需要清晰地描述所需的神经网络架构、输入输出格式和任务目标。静态分析和符号追踪用于检测生成代码中的错误,例如维度不匹配、类型错误等。数据集包含608个样本,每个样本都包含神经网络代码、输入数据和预期输出。
🖼️ 关键图片
📊 实验亮点
该研究生成了一个包含608个神经网络样本的数据集,涵盖了多种架构、数据类型和任务。通过静态分析和符号追踪验证,确保了数据集的正确性。该数据集的公开将为神经网络可靠性和适应性研究提供重要的资源。
🎯 应用场景
该研究成果可广泛应用于神经网络工具的评估和验证,例如代码验证、重构和迁移工具。该数据集可以作为基准,用于比较不同工具的性能和泛化能力。此外,该数据集还可以用于训练和评估新的神经网络架构和算法,促进神经网络领域的创新。
📄 摘要(原文)
Neural networks are increasingly used to support decision-making. To verify their reliability and adaptability, researchers and practitioners have proposed a variety of tools and methods for tasks such as NN code verification, refactoring, and migration. These tools play a crucial role in guaranteeing both the correctness and maintainability of neural network architectures, helping to prevent implementation errors, simplify model updates, and ensure that complex networks can be reliably extended and reused. Yet, assessing their effectiveness remains challenging due to the lack of publicly diverse datasets of neural networks that would allow systematic evaluation. To address this gap, we leverage large language models (LLMs) to automatically generate a dataset of neural networks that can serve as a benchmark for validation. The dataset is designed to cover diverse architectural components and to handle multiple input data types and tasks. In total, 608 samples are generated, each conforming to a set of precise design choices. To further ensure their consistency, we validate the correctness of the generated networks using static analysis and symbolic tracing. We make the dataset publicly available to support the community in advancing research on neural network reliability and adaptability.