Multi-scale hypergraph meets LLMs: Aligning large language models for time series analysis
作者: Zongjiang Shang, Dongliang Cui, Binqing Wu, Ling Chen
分类: cs.LG
发布日期: 2026-02-04
备注: Accepted by ICLR2026
💡 一句话要点
MSH-LLM:多尺度超图对齐大语言模型用于时间序列分析
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 时间序列分析 大语言模型 多尺度超图 跨模态对齐 混合提示 时间序列预测 LLM对齐
📋 核心要点
- 现有方法在利用预训练大语言模型进行时间序列分析时,未能充分考虑自然语言和时间序列的多尺度结构。
- MSH-LLM通过超边机制增强时间序列语义信息,并使用跨模态对齐模块和混合提示机制来对齐模态和增强LLM理解能力。
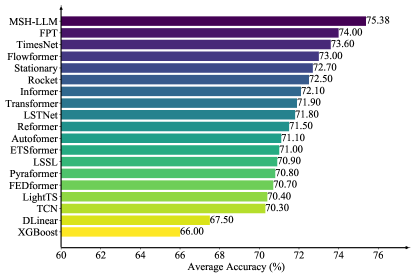
- 在27个真实数据集上的实验表明,MSH-LLM在时间序列分析任务上取得了state-of-the-art的结果。
📝 摘要(中文)
本文提出了一种名为MSH-LLM的多尺度超图方法,用于对齐大语言模型(LLMs)以进行时间序列分析。该方法旨在解决现有方法未充分考虑自然语言和时间序列的多尺度结构,导致LLMs能力利用不足的问题。具体而言,设计了一种超边机制来增强时间序列语义空间的多尺度语义信息。引入了跨模态对齐(CMA)模块,以在不同尺度上对齐自然语言和时间序列之间的模态。此外,还引入了一种混合提示(MoP)机制,以提供上下文信息并增强LLMs理解时间序列多尺度时间模式的能力。在涵盖5种不同应用的27个真实世界数据集上的实验结果表明,MSH-LLM取得了最先进的结果。
🔬 方法详解
问题定义:论文旨在解决如何更有效地利用预训练大语言模型(LLMs)进行时间序列分析的问题。现有方法未能充分考虑时间序列和自然语言的多尺度结构,导致LLMs的潜力没有被完全挖掘,影响了时间序列分析的性能。
核心思路:论文的核心思路是利用多尺度超图来建模时间序列数据,从而捕捉不同尺度下的时间模式。通过超边连接不同尺度的节点,增强时间序列语义空间的信息表达能力。同时,设计跨模态对齐模块和混合提示机制,将时间序列的多尺度信息有效地传递给LLMs,使其更好地理解和分析时间序列数据。
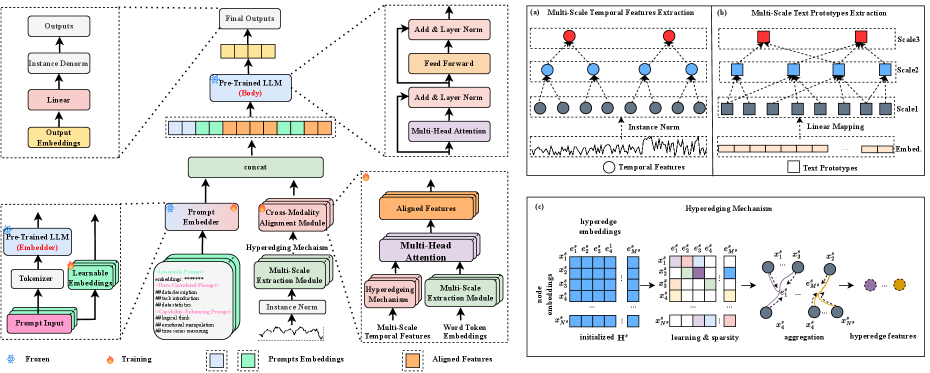
技术框架:MSH-LLM的整体框架包含以下几个主要模块:1) 多尺度超图构建模块,用于构建时间序列数据的多尺度表示;2) 跨模态对齐(CMA)模块,用于对齐自然语言和时间序列在不同尺度上的模态信息;3) 混合提示(MoP)机制,用于为LLMs提供上下文信息,增强其对时间序列多尺度时间模式的理解能力。整个流程是将时间序列数据输入多尺度超图构建模块,然后通过CMA模块和MoP机制将信息传递给LLMs,最终由LLMs完成时间序列分析任务。
关键创新:论文的关键创新在于以下几点:1) 提出了多尺度超图来建模时间序列数据,能够捕捉不同尺度下的时间模式;2) 设计了跨模态对齐模块,能够有效地对齐自然语言和时间序列的模态信息;3) 引入了混合提示机制,能够为LLMs提供更丰富的上下文信息,增强其对时间序列的理解能力。与现有方法相比,MSH-LLM能够更充分地利用LLMs的潜力,从而提高时间序列分析的性能。
关键设计:超图构建中,超边的选择策略和权重分配是关键。CMA模块中,如何设计有效的对齐损失函数,以及如何选择合适的对齐方式(例如,对比学习)是重要的技术细节。MoP机制中,提示的选择和组合方式,以及如何控制提示的长度和内容,都会影响LLMs的性能。此外,LLMs的选择(例如,LLaMA, GPT系列)以及微调策略也是需要考虑的关键设计。
🖼️ 关键图片

📊 实验亮点
MSH-LLM在27个真实世界数据集上进行了实验,涵盖了5种不同的应用。实验结果表明,MSH-LLM在所有数据集上都取得了state-of-the-art的结果,显著优于现有的时间序列分析方法。具体的性能提升幅度取决于数据集和应用,但总体而言,MSH-LLM能够有效地提高时间序列分析的准确性和效率。
🎯 应用场景
MSH-LLM具有广泛的应用前景,包括但不限于:金融时间序列预测、股票价格预测、销售预测、医疗健康监测、工业生产过程监控、气候变化分析等。该方法能够提升LLMs在时间序列分析任务中的性能,为相关领域的决策提供更准确的依据,具有重要的实际价值和未来影响。
📄 摘要(原文)
Recently, there has been great success in leveraging pre-trained large language models (LLMs) for time series analysis. The core idea lies in effectively aligning the modality between natural language and time series. However, the multi-scale structures of natural language and time series have not been fully considered, resulting in insufficient utilization of LLMs capabilities. To this end, we propose MSH-LLM, a Multi-Scale Hypergraph method that aligns Large Language Models for time series analysis. Specifically, a hyperedging mechanism is designed to enhance the multi-scale semantic information of time series semantic space. Then, a cross-modality alignment (CMA) module is introduced to align the modality between natural language and time series at different scales. In addition, a mixture of prompts (MoP) mechanism is introduced to provide contextual information and enhance the ability of LLMs to understand the multi-scale temporal patterns of time series. Experimental results on 27 real-world datasets across 5 different applications demonstrate that MSH-LLM achieves the state-of-the-art results.