EXaMCaP: Subset Selection with Entropy Gain Maximization for Probing Capability Gains of Large Chart Understanding Training Sets
作者: Jiapeng Liu, Liang Li, Bing Li, Peng Fu, Xiyan Gao, Chengyang Fang, Xiaoshuai Hao, Can Ma
分类: cs.LG
发布日期: 2026-02-04
💡 一句话要点
提出EXaMCaP,通过熵增益最大化进行子集选择,高效评估图表理解训练集的能力增益。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图表理解 多模态学习 子集选择 熵增益最大化 数据集评估
📋 核心要点
- 现有方法通过全量微调评估图表理解数据集的有效性,计算成本高昂,限制了迭代优化。
- EXaMCaP通过最大化熵增益选择最具代表性的子集,以高效评估数据集的能力增益。
- 实验证明EXaMCaP在探测能力增益方面优于现有方法,且适用于不同模型和子集大小。
📝 摘要(中文)
近期的研究集中于合成图表理解(ChartU)训练集,以将高级图表知识注入到多模态大型语言模型(MLLMs)中。通常通过微调-评估范式量化能力增益来验证知识的充分性。然而,全集微调MLLMs来评估这些增益会产生巨大的时间成本,阻碍了ChartU数据集的迭代优化周期。回顾ChartU数据集合成和数据选择领域,我们发现子集有可能探测MLLMs从全集微调中获得的能力增益。考虑到数据多样性对于提升MLLMs的性能至关重要,并且熵反映了这一特征,我们提出了EXaMCaP,它使用熵增益最大化来选择子集。为了获得高多样性的子集,EXaMCaP从大型ChartU数据集中选择最大熵子集。由于枚举所有可能的子集是不切实际的,EXaMCaP迭代地选择样本以最大化相对于当前集合的集合熵增益,从而近似于完整数据集的最大熵子集。实验表明,EXaMCaP在探测ChartU训练集的能力增益方面优于基线方法,并且在不同的子集大小和各种MLLM架构中都具有很强的有效性和兼容性。
🔬 方法详解
问题定义:论文旨在解决在图表理解(ChartU)训练集中,如何高效评估数据集对多模态大型语言模型(MLLMs)的能力增益问题。现有方法通常采用全量数据集微调MLLMs,然后评估性能,这种方式计算成本高昂,严重阻碍了数据集的迭代优化和快速验证。因此,需要一种方法能够仅使用数据集的子集,就能准确地预测全量数据集微调后的性能提升。
核心思路:论文的核心思路是利用数据集子集的熵来近似评估全量数据集的能力增益。作者认为,数据集的多样性是影响MLLMs性能的关键因素,而熵能够有效反映数据集的多样性。因此,通过选择具有最大熵增益的子集,可以近似模拟全量数据集的训练效果,从而降低评估成本。
技术框架:EXaMCaP 的整体框架包含以下步骤:1. 初始化:从空集开始,作为初始子集。2. 迭代选择:每次迭代时,计算将数据集中剩余的每个样本添加到当前子集后所带来的熵增益。3. 选择最优样本:选择能够带来最大熵增益的样本,将其添加到当前子集中。4. 重复迭代:重复步骤2和3,直到子集达到预设的大小。通过这种迭代的方式,逐步构建一个具有最大熵的子集,用于评估数据集的能力增益。
关键创新:EXaMCaP 的关键创新在于利用熵增益最大化来选择最具代表性的数据集子集。与随机选择或基于其他指标(如数据密度)选择子集的方法相比,EXaMCaP 能够更好地捕捉数据集的多样性,从而更准确地预测全量数据集的训练效果。此外,EXaMCaP 采用迭代选择的方式,避免了枚举所有可能的子集,大大降低了计算复杂度。
关键设计:EXaMCaP 的关键设计在于熵增益的计算方式。论文中使用的熵增益定义为将样本添加到当前子集后,子集熵的增加量。熵的计算方式需要根据具体的数据类型进行选择,例如,对于分类数据,可以使用香农熵;对于连续数据,可以使用微分熵。此外,子集大小的选择也是一个重要的参数,需要根据数据集的大小和计算资源进行调整。
🖼️ 关键图片


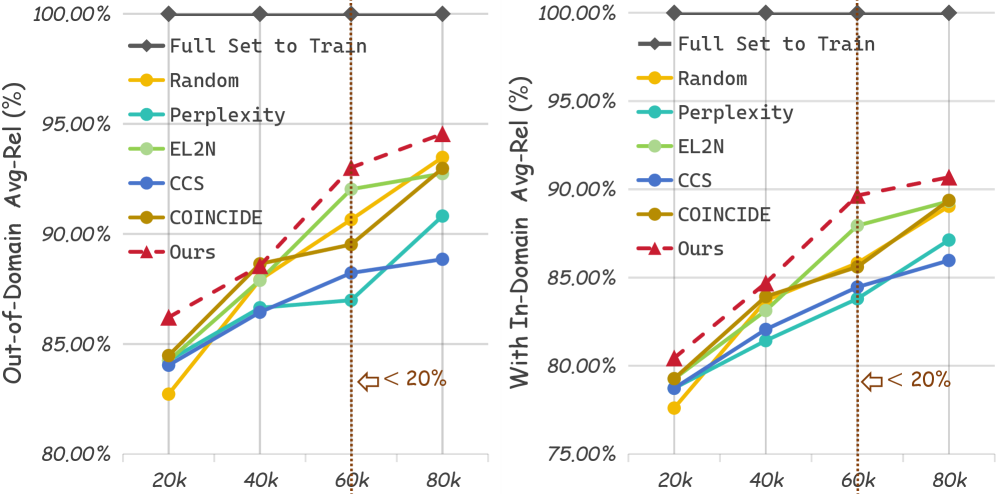
📊 实验亮点
实验结果表明,EXaMCaP在探测ChartU训练集的能力增益方面显著优于基线方法。在不同子集大小和各种MLLM架构下,EXaMCaP均表现出强大的有效性和兼容性,能够以较低的计算成本准确预测全量数据集的训练效果。
🎯 应用场景
EXaMCaP可应用于各种图表理解数据集的快速评估和筛选,加速多模态大语言模型的训练和优化。该方法还可推广到其他数据选择场景,例如主动学习、数据蒸馏等,降低模型训练成本,提高模型性能。
📄 摘要(原文)
Recent works focus on synthesizing Chart Understanding (ChartU) training sets to inject advanced chart knowledge into Multimodal Large Language Models (MLLMs), where the sufficiency of the knowledge is typically verified by quantifying capability gains via the fine-tune-then-evaluate paradigm. However, full-set fine-tuning MLLMs to assess such gains incurs significant time costs, hindering the iterative refinement cycles of the ChartU dataset. Reviewing the ChartU dataset synthesis and data selection domains, we find that subsets can potentially probe the MLLMs' capability gains from full-set fine-tuning. Given that data diversity is vital for boosting MLLMs' performance and entropy reflects this feature, we propose EXaMCaP, which uses entropy gain maximization to select a subset. To obtain a high-diversity subset, EXaMCaP chooses the maximum-entropy subset from the large ChartU dataset. As enumerating all possible subsets is impractical, EXaMCaP iteratively selects samples to maximize the gain in set entropy relative to the current set, approximating the maximum-entropy subset of the full dataset. Experiments show that EXaMCaP outperforms baselines in probing the capability gains of the ChartU training set, along with its strong effectiveness across diverse subset sizes and compatibility with various MLLM architectures.