Training A Foundation Model to Represent Graphs as Vectors
作者: Qi Feng, Jicong Fan
分类: cs.LG
发布日期: 2026-02-04
💡 一句话要点
提出一种图向量表征的图基础模型训练方法,用于图分类和图聚类等图级别任务。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图神经网络 图表示学习 对比学习 多图特征对齐 图分类 图聚类 基础模型 泛化能力
📋 核心要点
- 现有图表示学习方法在跨领域泛化能力上存在不足,难以适应多样化的图结构和语义信息。
- 论文提出多图特征对齐方法,通过构建加权图和密度最大化均值对齐算法,增强不同数据集特征的一致性。
- 实验结果表明,该模型在少量样本图分类和图聚类任务上优于现有基线模型,验证了其有效性。
📝 摘要(中文)
本文旨在训练一个图基础模型,该模型能够将任何图表示为向量,同时保留对下游图级别任务(如图分类和图聚类)有用的结构和语义信息。为了从不同领域的图中学习特征,同时保持对新领域的强大泛化能力,我们提出了一种基于多图的特征对齐方法,该方法使用每个数据集中所有节点的属性构建加权图,然后生成一致的节点嵌入。为了增强来自不同数据集的特征的一致性,我们提出了一种具有保证收敛性的密度最大化均值对齐算法。原始图和生成的节点嵌入被输入到图神经网络中,以在对比学习中实现判别性图表示。更重要的是,为了增强从节点级表示到图级表示的信息保留,我们构建了一个不使用任何池化操作的多层参考分布模块。我们还提供了理论泛化界限来支持所提出模型的有效性。少量样本图分类和图聚类的实验结果表明,我们的模型优于强大的基线模型。
🔬 方法详解
问题定义:现有图表示学习方法在处理来自不同领域的图数据时,泛化能力不足。这些方法难以有效地捕捉和保留图的结构和语义信息,导致在图分类和图聚类等下游任务中表现不佳。特别是在少量样本学习场景下,问题尤为突出。
核心思路:论文的核心思路是通过训练一个图基础模型,将任何图表示为一个向量,同时最大程度地保留其结构和语义信息。为了实现这一目标,论文提出了多图特征对齐方法,旨在增强不同数据集特征的一致性,并设计了一个多层参考分布模块,以增强从节点级表示到图级表示的信息保留。
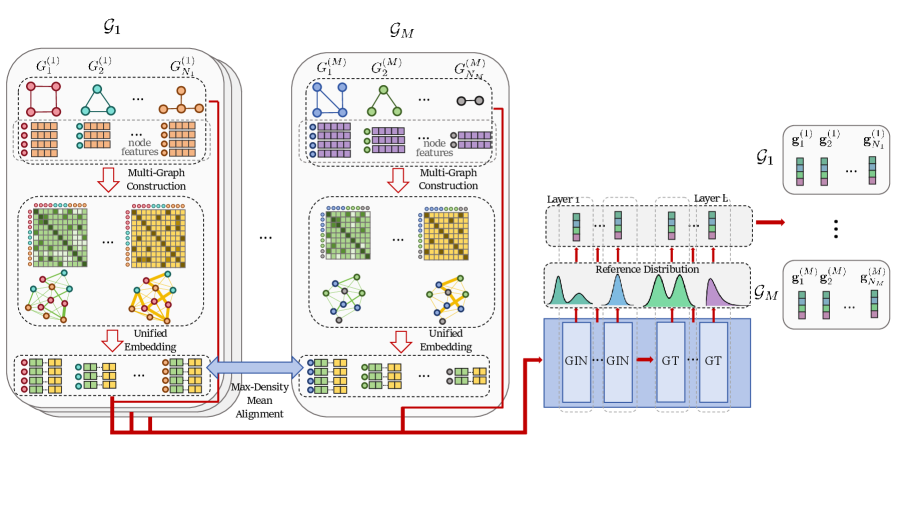
技术框架:该模型主要包含以下几个模块:1) 多图构建模块:利用每个数据集中所有节点的属性构建加权图。2) 节点嵌入生成模块:生成一致的节点嵌入。3) 密度最大化均值对齐模块:增强来自不同数据集的特征的一致性。4) 图神经网络:将原始图和生成的节点嵌入输入到图神经网络中,以在对比学习中实现判别性图表示。5) 多层参考分布模块:增强从节点级表示到图级表示的信息保留,避免使用池化操作。
关键创新:论文的关键创新在于:1) 提出了多图特征对齐方法,有效地解决了跨领域图数据泛化问题。2) 设计了密度最大化均值对齐算法,保证了特征对齐的收敛性。3) 构建了多层参考分布模块,增强了信息从节点级到图级的传递,避免了信息损失。
关键设计:论文的关键设计包括:1) 加权图的构建方式,如何根据节点属性确定边的权重。2) 密度最大化均值对齐算法的具体实现,包括损失函数的设计和优化方法。3) 多层参考分布模块的网络结构和参数设置,如何有效地聚合节点信息并生成图级别的表示。4) 对比学习框架的具体实现,包括正负样本的选择和损失函数的设计。
🖼️ 关键图片
📊 实验亮点
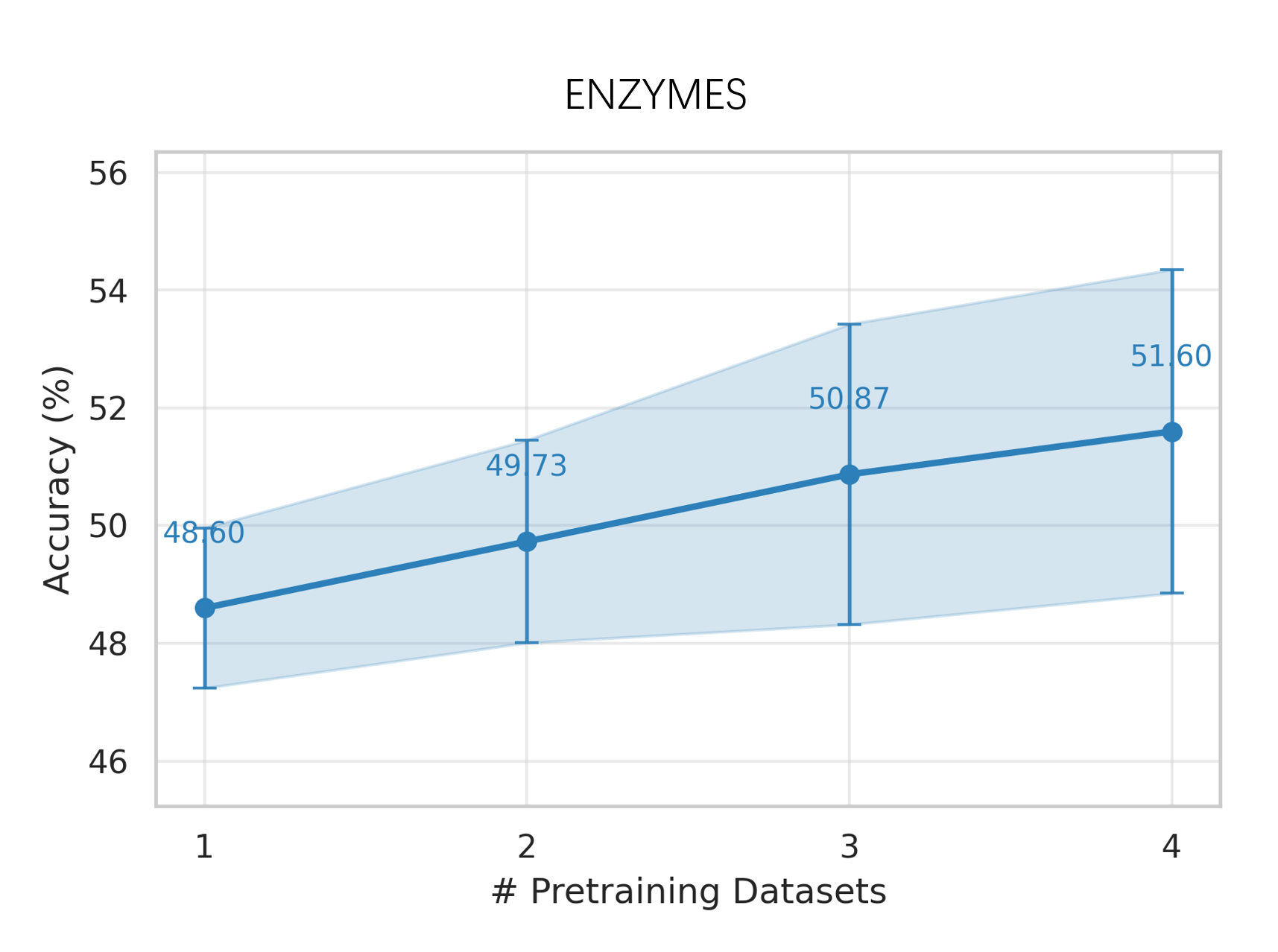
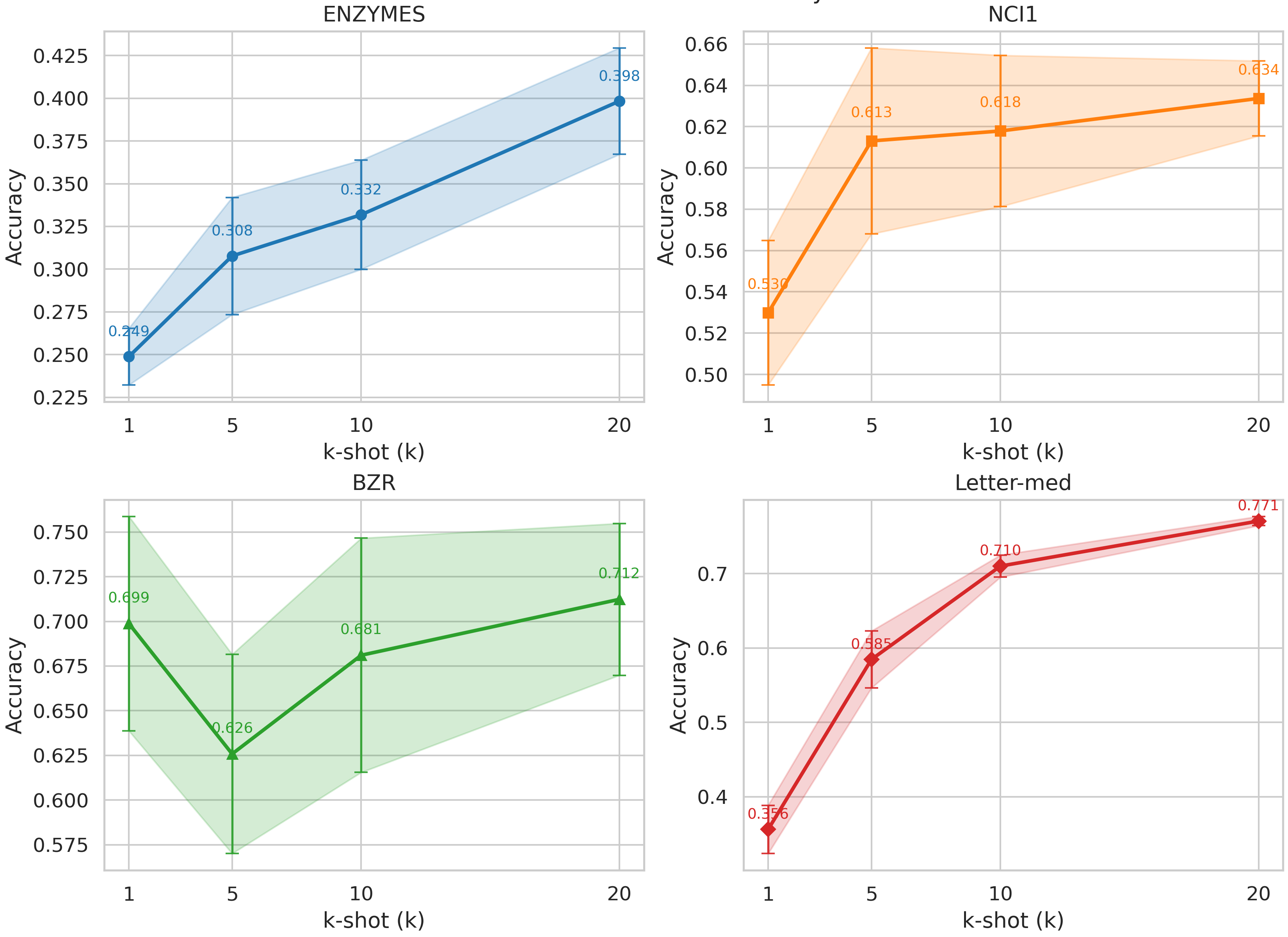
实验结果表明,该模型在少量样本图分类和图聚类任务上显著优于现有基线模型。具体性能提升数据未知,但摘要明确指出优于“strong baselines”,表明该模型具有较强的竞争力。
🎯 应用场景
该研究成果可广泛应用于图数据分析领域,例如社交网络分析、生物信息学、化学信息学等。通过将图数据表示为向量,可以方便地进行图分类、图聚类、图相似度计算等任务。该模型在药物发现、社交媒体分析、推荐系统等领域具有潜在的应用价值。
📄 摘要(原文)
This paper aims to train a graph foundation model that is able to represent any graph as a vector preserving structural and semantic information useful for downstream graph-level tasks such as graph classification and graph clustering. To learn the features of graphs from diverse domains while maintaining strong generalization ability to new domains, we propose a multi-graph-based feature alignment method, which constructs weighted graphs using the attributes of all nodes in each dataset and then generates consistent node embeddings. To enhance the consistency of the features from different datasets, we propose a density maximization mean alignment algorithm with guaranteed convergence. The original graphs and generated node embeddings are fed into a graph neural network to achieve discriminative graph representations in contrastive learning. More importantly, to enhance the information preservation from node-level representations to the graph-level representation, we construct a multi-layer reference distribution module without using any pooling operation. We also provide a theoretical generalization bound to support the effectiveness of the proposed model. The experimental results of few-shot graph classification and graph clustering show that our model outperforms strong baselines.