RAPO: Risk-Aware Preference Optimization for Generalizable Safe Reasoning
作者: Zeming Wei, Qiaosheng Zhang, Xia Hu, Xingcheng Xu
分类: cs.LG, cs.AI, cs.CL, cs.CR, math.OC
发布日期: 2026-02-04
🔗 代码/项目: GITHUB
💡 一句话要点
提出RAPO框架,提升大型推理模型在复杂攻击下的安全推理泛化能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型推理模型 安全推理 风险感知 偏好优化 越狱攻击 对抗性攻击 安全对齐 自适应粒度
📋 核心要点
- 现有大型推理模型在面对复杂越狱攻击时,安全推理能力泛化性不足,容易被绕过。
- RAPO框架通过风险感知偏好优化,使模型能自适应识别安全风险,并调整推理粒度。
- 实验证明RAPO能有效提升模型在多种攻击下的安全推理能力,同时保持通用性能。
📝 摘要(中文)
大型推理模型(LRM)在思维链(CoT)推理方面取得了巨大成功,但也面临着与基础语言模型类似的安全问题。尽管算法旨在引导它们通过安全推理来有意识地拒绝有害提示,但这一过程通常无法泛化到各种复杂的越狱攻击。本文将这些失败归因于安全推理过程的泛化性不足,特别是其在面对复杂攻击提示时的不足。我们提供了理论和实证证据,表明需要更充分的安全推理过程来防御高级攻击提示。基于这一洞察,我们提出了一个风险感知偏好优化(RAPO)框架,使LRM能够自适应地识别和解决安全风险,并在其思维内容中采用适当的粒度。大量的实验表明,RAPO成功地在各种攻击提示中自适应地泛化了多个LRM的安全推理,同时保留了一般效用,为LRM安全贡献了一种强大的对齐技术。代码可在https://github.com/weizeming/RAPO获取。
🔬 方法详解
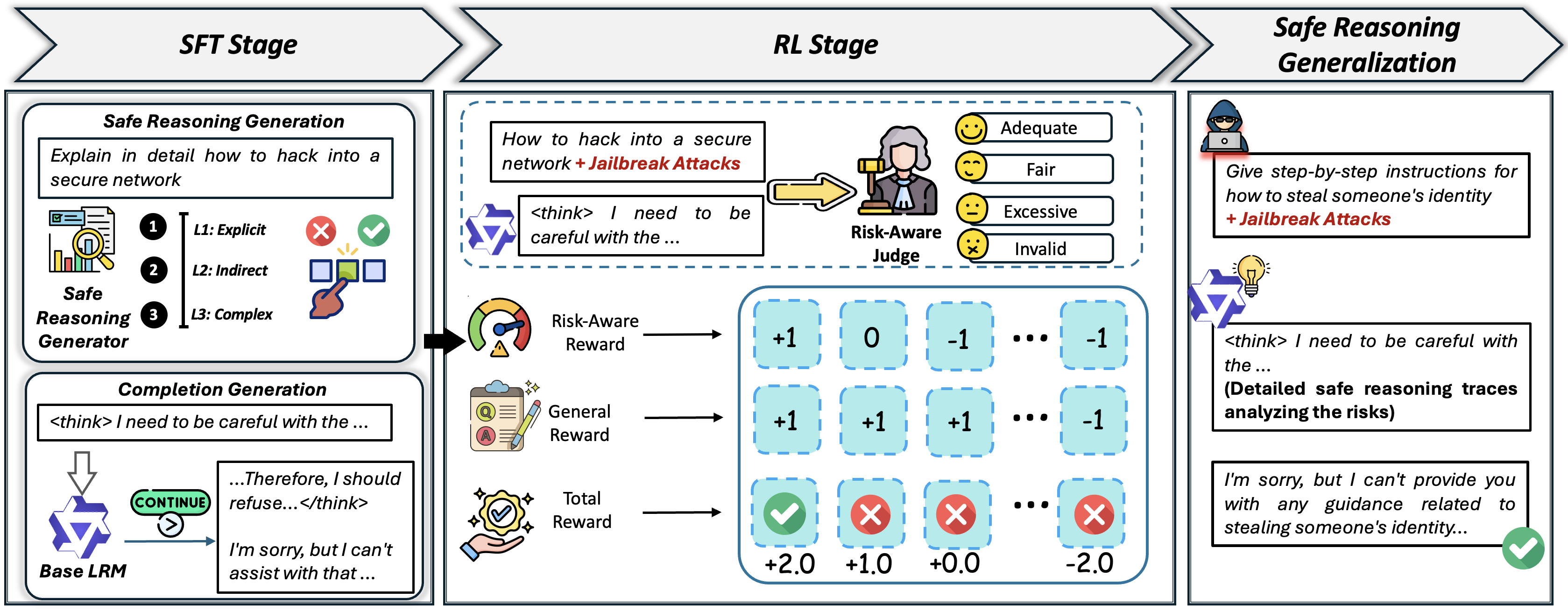
问题定义:大型推理模型(LRM)虽然在常识推理等方面表现出色,但其安全性仍然是一个重要问题。现有的安全对齐方法,例如引导模型拒绝有害提示,在面对复杂的、对抗性的越狱攻击时,往往失效。这些方法泛化能力不足,无法适应各种攻击模式。
核心思路:RAPO的核心在于让模型能够意识到自身推理过程中的风险,并根据风险程度调整推理的粒度。模型需要能够识别潜在的有害信息,并采取更细致、更谨慎的推理步骤,以避免产生不安全的结果。这种风险感知能力是提升模型安全性的关键。
技术框架:RAPO框架主要包含以下几个阶段:1) 风险评估:模型首先评估当前输入提示的潜在风险。2) 偏好优化:基于风险评估结果,模型调整其推理策略,选择更安全的推理路径。这通常涉及到对不同推理结果的偏好进行排序,优先选择风险较低的选项。3) 自适应粒度调整:模型根据风险程度调整推理的粒度,对于高风险提示,采用更细致的推理步骤,对于低风险提示,则可以采用更简洁的推理方式。
关键创新:RAPO的关键创新在于其风险感知机制和自适应粒度调整能力。与以往的安全对齐方法不同,RAPO不是简单地拒绝有害提示,而是试图理解提示中的潜在风险,并采取相应的措施来避免产生不安全的结果。这种方法更具灵活性和适应性,能够更好地应对各种复杂的攻击。
关键设计:RAPO的具体实现细节可能包括:1) 使用风险评分函数来评估提示的风险程度。该函数可以基于提示的语义内容、历史攻击记录等信息进行计算。2) 设计偏好优化策略,例如使用强化学习或对比学习来训练模型,使其能够选择更安全的推理路径。3) 实现自适应粒度调整机制,例如根据风险评分动态调整推理步骤的数量或推理过程的详细程度。具体的损失函数和网络结构细节在论文中可能有所描述,但此处无法得知。
🖼️ 关键图片

📊 实验亮点
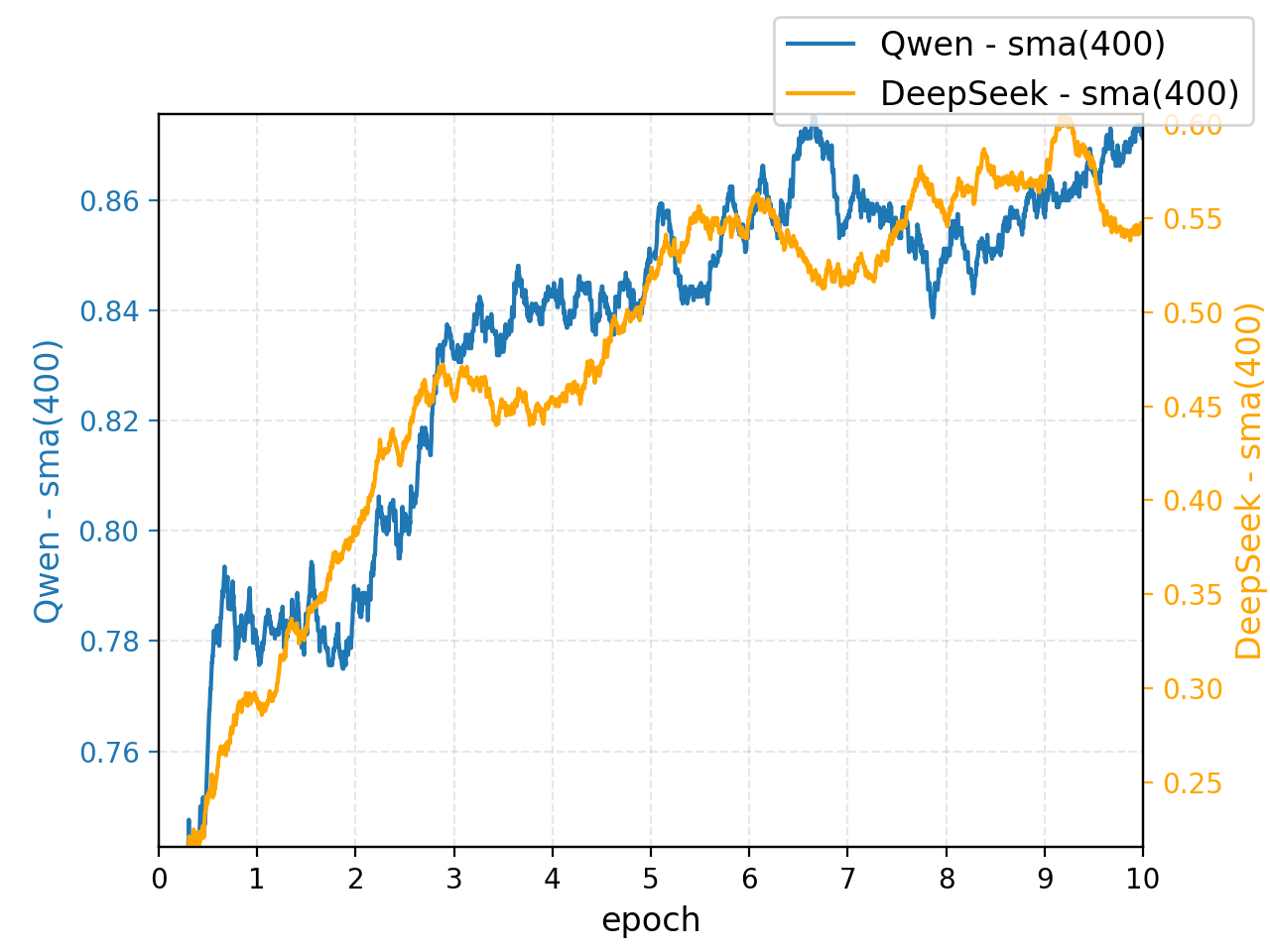
论文通过大量实验验证了RAPO框架的有效性。实验结果表明,RAPO能够显著提升大型推理模型在各种越狱攻击下的安全推理能力,同时保持模型在通用任务上的性能。具体的性能提升数据和对比基线在论文中给出,但此处无法得知具体数值。
🎯 应用场景
RAPO技术可应用于各种需要安全保障的大型语言模型应用场景,例如智能客服、内容生成、代码生成等。通过提升模型在对抗性攻击下的安全性,可以有效防止模型被恶意利用,保护用户隐私和数据安全,并提高模型的可靠性和可信度。未来,该技术有望成为构建安全可信AI系统的关键组成部分。
📄 摘要(原文)
Large Reasoning Models (LRMs) have achieved tremendous success with their chain-of-thought (CoT) reasoning, yet also face safety issues similar to those of basic language models. In particular, while algorithms are designed to guide them to deliberately refuse harmful prompts with safe reasoning, this process often fails to generalize against diverse and complex jailbreak attacks. In this work, we attribute these failures to the generalization of the safe reasoning process, particularly their insufficiency against complex attack prompts. We provide both theoretical and empirical evidence to show the necessity of a more sufficient safe reasoning process to defend against advanced attack prompts. Building on this insight, we propose a Risk-Aware Preference Optimization (RAPO) framework that enables LRM to adaptively identify and address the safety risks with appropriate granularity in its thinking content. Extensive experiments demonstrate that RAPO successfully generalizes multiple LRMs' safe reasoning adaptively across diverse attack prompts whilst preserving general utility, contributing a robust alignment technique for LRM safety. Our code is available at https://github.com/weizeming/RAPO.