Topology-Aware Revival for Efficient Sparse Training
作者: Meiling Jin, Fei Wang, Xiaoyun Yuan, Chen Qian, Yuan Cheng
分类: cs.LG, cs.AI
发布日期: 2026-02-04
💡 一句话要点
提出拓扑感知复苏(TAR)方法,提升静态稀疏训练在强化学习中的性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 稀疏训练 深度强化学习 拓扑感知 剪枝 复苏
📋 核心要点
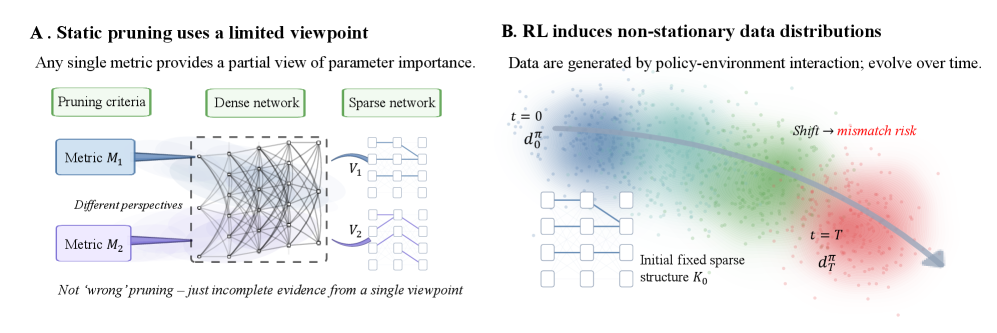
- 静态稀疏训练虽然高效,但早期剪枝易导致网络陷入脆弱结构,尤其在训练分布不断变化的强化学习中。
- 论文提出拓扑感知复苏(TAR)方法,通过一次性的后剪枝复苏步骤,在不动态重连的情况下提升静态稀疏性。
- 实验表明,TAR在多个连续控制任务中显著优于静态和动态稀疏训练基线,提升了最终回报。
📝 摘要(中文)
静态稀疏训练通过固定掩码模式来实现高效学习,但受限的结构降低了鲁棒性。早期的剪枝决策可能将网络锁定在一个难以逃脱的脆弱结构中,尤其是在深度强化学习(RL)中,不断演变的策略持续改变训练分布。我们提出了拓扑感知复苏(TAR),这是一种轻量级的一次性后剪枝程序,可以在没有动态重连的情况下提高静态稀疏性。在静态剪枝之后,TAR执行一个单一的复苏步骤,根据拓扑需求在各层分配一个小的储备预算,在每一层内随机均匀地重新激活一些先前剪枝的连接,然后保持由此产生的连接性固定用于剩余的训练。在使用SAC和TD3的多个连续控制任务中,TAR相对于静态稀疏基线提高了高达+37.9%的最终回报,并且优于动态稀疏训练基线,中位数增益为+13.5%。
🔬 方法详解
问题定义:静态稀疏训练虽然能提升效率,但其固定的连接模式缺乏鲁棒性。尤其是在深度强化学习中,策略的不断演进导致训练分布发生变化,早期的剪枝决策可能导致网络陷入局部最优,难以适应新的训练分布。现有方法要么依赖动态重连,计算开销大,要么性能提升有限。
核心思路:TAR的核心思想是在静态剪枝后,通过一次性的“复苏”步骤,重新激活少量被剪枝的连接,从而在不引入过多计算开销的前提下,增强网络的探索能力和鲁棒性。这种复苏是拓扑感知的,即根据不同层的拓扑结构,自适应地分配复苏预算。
技术框架:TAR方法包含以下几个主要步骤:1) 使用标准的静态剪枝方法对网络进行剪枝,得到一个稀疏的网络结构。2) 根据每一层的拓扑结构(例如,神经元的数量、连接的密度等),为每一层分配一个复苏预算,即允许重新激活的连接数量。3) 在每一层内,随机均匀地选择先前被剪枝的连接,并将其重新激活。4) 在剩余的训练过程中,保持网络的连接结构固定不变。
关键创新:TAR的关键创新在于其拓扑感知的复苏策略。与随机复苏或均匀复苏不同,TAR根据每一层的拓扑结构自适应地分配复苏预算,使得复苏过程更加高效和有针对性。此外,TAR采用一次性的复苏步骤,避免了动态重连带来的计算开销。
关键设计:TAR的关键设计包括:1) 复苏预算的分配策略:论文中可能采用某种启发式方法或学习算法来确定每一层的复苏预算。2) 复苏连接的选择策略:论文采用随机均匀的选择策略,保证了复苏过程的随机性和探索性。3) 整体的稀疏度控制:需要在效率和性能之间进行权衡,选择合适的稀疏度。
🖼️ 关键图片


📊 实验亮点
实验结果表明,在多个连续控制任务中,TAR方法显著优于静态稀疏训练基线,最终回报提升高达+37.9%。同时,TAR方法也优于动态稀疏训练基线,中位数增益为+13.5%。这些结果表明,TAR方法能够在不引入过多计算开销的前提下,有效提升静态稀疏训练的性能。
🎯 应用场景
TAR方法可应用于各种需要高效深度学习的场景,尤其是在资源受限的边缘设备上部署深度强化学习模型。例如,智能机器人、自动驾驶、游戏AI等领域,可以利用TAR方法在保证性能的同时,降低计算和存储成本,实现更高效的在线学习和决策。
📄 摘要(原文)
Static sparse training is a promising route to efficient learning by committing to a fixed mask pattern, yet the constrained structure reduces robustness. Early pruning decisions can lock the network into a brittle structure that is difficult to escape, especially in deep reinforcement learning (RL) where the evolving policy continually shifts the training distribution. We propose Topology-Aware Revival (TAR), a lightweight one-shot post-pruning procedure that improves static sparsity without dynamic rewiring. After static pruning, TAR performs a single revival step by allocating a small reserve budget across layers according to topology needs, randomly uniformly reactivating a few previously pruned connections within each layer, and then keeping the resulting connectivity fixed for the remainder of training. Across multiple continuous-control tasks with SAC and TD3, TAR improves final return over static sparse baselines by up to +37.9% and also outperforms dynamic sparse training baselines with a median gain of +13.5%.