BPDQ: Bit-Plane Decomposition Quantization on a Variable Grid for Large Language Models
作者: Junyu Chen, Jungang Li, Jing Xiong, Wenjie Wang, Qingyao Yang, He Xiao, Zhen Li, Taiqiang Wu, Mengzhao Chen, Zhen Peng, Chaofan Tao, Long Shi, Hongxia Yang, Ngai Wong
分类: cs.LG
发布日期: 2026-02-04
💡 一句话要点
BPDQ:基于可变网格的比特平面分解量化,用于大语言模型压缩
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 量化 低比特量化 比特平面分解 可变量化网格
📋 核心要点
- 现有量化方法采用固定形状的量化网格,限制了误差最小化的可行性,导致低比特量化精度下降。
- BPDQ通过比特平面和标量系数构建可变量化网格,并迭代优化,逐步补偿量化误差,从而最小化输出差异。
- 实验表明,BPDQ在2比特量化下,能够显著提升大语言模型的推理精度,例如在Qwen2.5-72B模型上取得了优秀的GSM8K准确率。
📝 摘要(中文)
大语言模型(LLM)的推理通常受限于资源受限部署中的内存占用和内存带宽,这使得量化成为高效服务的关键技术。虽然训练后量化(PTQ)在4比特时保持高保真度,但在2-3比特时会恶化。从根本上说,现有方法对每个组强制执行形状不变的量化网格(例如,UINT2的固定均匀间隔),严重限制了误差最小化的可行集。为了解决这个问题,我们提出了比特平面分解量化(BPDQ),它通过比特平面和标量系数构建可变的量化网格,并使用近似二阶信息迭代地细化它们,同时逐步补偿量化误差,以最小化输出差异。在2比特方案中,BPDQ能够在单个RTX 3090上服务Qwen2.5-72B,GSM8K准确率为83.85%(而16比特时为90.83%)。此外,我们提供了理论分析,表明可变网格扩展了可行集,并且量化过程始终与Hessian诱导几何中的优化目标对齐。
🔬 方法详解
问题定义:论文旨在解决大语言模型低比特量化(尤其是2-3比特)时精度显著下降的问题。现有方法,如PTQ,在低比特下性能不佳,主要原因是它们采用固定形状的量化网格,无法充分适应模型参数的分布,限制了误差最小化的能力。
核心思路:BPDQ的核心思路是构建一个可变的量化网格,使其能够更好地适应模型参数的分布,从而在低比特量化下实现更高的精度。通过比特平面分解和标量系数的组合,BPDQ能够灵活地调整量化网格的形状,从而更有效地最小化量化误差。
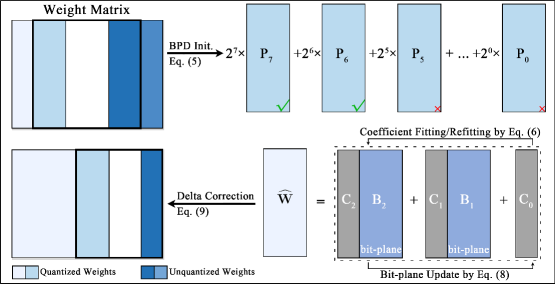
技术框架:BPDQ的整体流程包括以下几个主要阶段:1) 比特平面分解:将原始权重分解为多个比特平面。2) 可变量化网格构建:利用比特平面和标量系数构建可变的量化网格。3) 迭代优化:使用近似二阶信息迭代地优化标量系数,并逐步补偿量化误差。4) 量化:将权重映射到可变量化网格中的离散值。
关键创新:BPDQ最关键的创新在于其可变量化网格的设计。与现有方法采用的固定形状量化网格不同,BPDQ的量化网格可以根据模型参数的分布进行调整,从而更有效地最小化量化误差。此外,BPDQ还采用了迭代优化和误差补偿机制,进一步提升了量化精度。
关键设计:BPDQ的关键设计包括:1) 比特平面分解的具体方式,例如如何选择比特平面的数量和顺序。2) 标量系数的初始化和优化方法,例如使用近似二阶信息进行优化。3) 误差补偿的具体策略,例如如何估计和补偿量化误差。4) 损失函数的设计,目标是最小化量化后的模型输出与原始模型输出之间的差异。
🖼️ 关键图片

📊 实验亮点
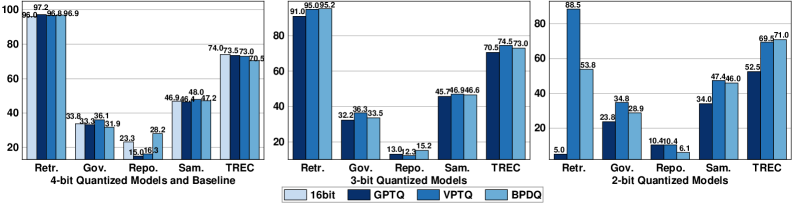
BPDQ在2比特量化下,能够在单个RTX 3090上运行Qwen2.5-72B模型,并取得了83.85%的GSM8K准确率,相比之下,16比特浮点模型的准确率为90.83%。这表明BPDQ在极低比特量化下,仍然能够保持较高的模型性能,显著优于传统的量化方法。
🎯 应用场景
BPDQ技术可广泛应用于资源受限场景下的大语言模型部署,例如移动设备、边缘计算设备等。通过降低模型内存占用和内存带宽需求,BPDQ能够使这些设备也能运行大型语言模型,从而实现更智能化的应用,例如本地化的自然语言处理、智能助手等。该技术还有助于降低大模型推理的成本,加速大模型的普及。
📄 摘要(原文)
Large language model (LLM) inference is often bounded by memory footprint and memory bandwidth in resource-constrained deployments, making quantization a fundamental technique for efficient serving. While post-training quantization (PTQ) maintains high fidelity at 4-bit, it deteriorates at 2-3 bits. Fundamentally, existing methods enforce a shape-invariant quantization grid (e.g., the fixed uniform intervals of UINT2) for each group, severely restricting the feasible set for error minimization. To address this, we propose Bit-Plane Decomposition Quantization (BPDQ), which constructs a variable quantization grid via bit-planes and scalar coefficients, and iteratively refines them using approximate second-order information while progressively compensating quantization errors to minimize output discrepancy. In the 2-bit regime, BPDQ enables serving Qwen2.5-72B on a single RTX 3090 with 83.85% GSM8K accuracy (vs. 90.83% at 16-bit). Moreover, we provide theoretical analysis showing that the variable grid expands the feasible set, and that the quantization process consistently aligns with the optimization objective in Hessian-induced geometry. Code: github.com/KingdalfGoodman/BPDQ.