Decoupling Time and Risk: Risk-Sensitive Reinforcement Learning with General Discounting
作者: Mehrdad Moghimi, Anthony Coache, Hyejin Ku
分类: cs.LG
发布日期: 2026-02-04
💡 一句话要点
提出支持广义折扣的风险敏感强化学习框架,解耦时间偏好与风险评估
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 风险敏感强化学习 分布强化学习 折扣因子 时间偏好 广义折扣 安全关键应用 马尔可夫决策过程
📋 核心要点
- 现有强化学习方法通常将折扣因子视为固定参数,忽略了其对策略学习的影响,无法充分表达智能体的时间偏好。
- 论文提出一种新框架,支持灵活的未来奖励折扣和风险度量优化,从而解耦时间和风险偏好。
- 通过实验验证了该方法在鲁棒性方面的优势,表明折扣因子在决策问题中具有重要作用。
📝 摘要(中文)
分布强化学习(RL)是一个强大的框架,因其能够优化风险敏感目标,越来越多地被应用于安全关键领域。然而,折扣因子(discount factor)的作用经常被忽视,它通常被视为马尔可夫决策过程的固定参数或可调超参数,很少考虑其对学习策略的影响。文献表明,折扣函数在表征智能体的时间偏好方面起着重要作用,而指数折扣因子无法完全捕捉这一点。基于此,我们提出了一个新颖的框架,支持未来奖励的灵活折扣和分布强化学习中风险度量的优化。我们提供了算法最优性的技术分析,表明我们的多horizon扩展解决了现有方法提出的问题,并通过广泛的实验验证了我们方法的鲁棒性。我们的结果表明,折扣是决策问题中捕捉更具表现力的时间和风险偏好特征的基石,对现实世界的安全关键应用具有潜在的影响。
🔬 方法详解
问题定义:现有风险敏感强化学习方法通常采用固定的指数折扣因子,无法充分表达智能体对不同时间段奖励的偏好。这种简化处理限制了算法在复杂决策场景中的应用,尤其是在需要精细控制风险和时间偏好的安全关键领域。现有方法难以区分时间偏好和风险评估,导致策略优化受限。
核心思路:论文的核心思路是将时间折扣和风险评估解耦,允许使用更通用的折扣函数来表达智能体的时间偏好,而不是局限于指数折扣。通过这种方式,算法可以更灵活地调整对不同时间段奖励的重视程度,从而更好地适应不同的决策场景。这种解耦使得风险敏感的优化目标能够更准确地反映智能体的真实偏好。
技术框架:该框架基于分布强化学习,通过引入广义折扣函数来修改传统的贝尔曼更新。整体流程包括:1) 使用广义折扣函数计算未来奖励的折扣值;2) 利用折扣后的奖励更新价值分布;3) 基于价值分布计算风险度量;4) 根据风险度量优化策略。该框架的关键在于如何设计和选择合适的广义折扣函数,以及如何保证算法的收敛性和稳定性。
关键创新:最重要的技术创新点在于将时间折扣和风险评估解耦,并提出了一种支持广义折扣函数的风险敏感强化学习算法。与现有方法相比,该方法能够更灵活地表达智能体的时间偏好,从而更好地适应不同的决策场景。此外,论文还提出了多horizon扩展,解决了现有方法存在的问题。
关键设计:论文的关键设计包括:1) 广义折扣函数的选择,可以使用各种函数来表达不同的时间偏好,例如双曲折扣等;2) 价值分布的更新方式,需要保证更新后的价值分布能够准确反映折扣后的奖励;3) 风险度量的计算方式,可以使用各种风险度量,例如条件风险价值(CVaR)等;4) 策略优化算法的选择,可以使用各种强化学习算法,例如Q-learning、SARSA等。
🖼️ 关键图片

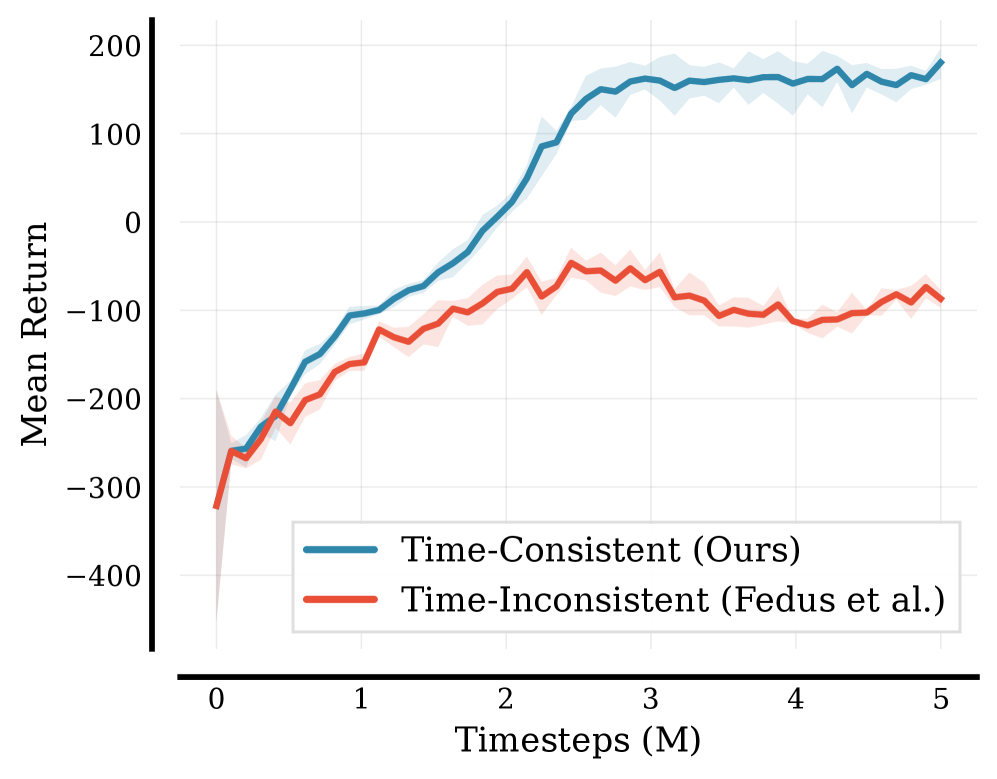
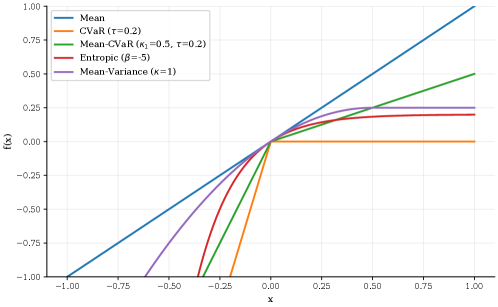
📊 实验亮点
实验结果表明,该方法在多个benchmark任务上优于现有的风险敏感强化学习算法。具体来说,在某些任务上,该方法能够显著降低风险,同时保持较高的奖励。此外,实验还验证了多horizon扩展的有效性,表明其能够解决现有方法存在的问题,并提高算法的鲁棒性。
🎯 应用场景
该研究成果可应用于安全关键领域,如自动驾驶、医疗决策、金融投资等。通过灵活调整折扣函数,可以使智能体更好地适应不同的风险偏好和时间偏好,从而做出更安全、更合理的决策。例如,在自动驾驶中,可以根据路况和驾驶员的偏好调整折扣函数,以实现更安全、更舒适的驾驶体验。
📄 摘要(原文)
Distributional reinforcement learning (RL) is a powerful framework increasingly adopted in safety-critical domains for its ability to optimize risk-sensitive objectives. However, the role of the discount factor is often overlooked, as it is typically treated as a fixed parameter of the Markov decision process or tunable hyperparameter, with little consideration of its effect on the learned policy. In the literature, it is well-known that the discounting function plays a major role in characterizing time preferences of an agent, which an exponential discount factor cannot fully capture. Building on this insight, we propose a novel framework that supports flexible discounting of future rewards and optimization of risk measures in distributional RL. We provide a technical analysis of the optimality of our algorithms, show that our multi-horizon extension fixes issues raised with existing methodologies, and validate the robustness of our methods through extensive experiments. Our results highlight that discounting is a cornerstone in decision-making problems for capturing more expressive temporal and risk preferences profiles, with potential implications for real-world safety-critical applications.