Understanding and Exploiting Weight Update Sparsity for Communication-Efficient Distributed RL
作者: Erfan Miahi, Eugene Belilovsky
分类: cs.LG
发布日期: 2026-02-03
备注: 32 pages, 14 figures
💡 一句话要点
PULSE:利用权重更新稀疏性,实现通信高效的分布式强化学习
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 分布式强化学习 通信效率 权重更新稀疏性 无损压缩 去中心化训练
📋 核心要点
- 现有分布式强化学习在带宽受限环境下,策略权重同步成为性能瓶颈,尤其是在去中心化场景。
- 论文提出PULSE方法,通过仅传输更新的参数索引和值,利用权重更新的稀疏性来减少通信量。
- 实验表明,PULSE在保持训练性能的同时,显著降低了通信带宽需求,提升了去中心化RL的吞吐量。
📝 摘要(中文)
强化学习(RL)是训练大型语言模型(LLM)的关键组成部分。然而,在带宽受限的分布式RL中,可扩展性通常受到从训练器到推理worker的策略权重同步的瓶颈限制,尤其是在商品网络或去中心化环境中。虽然最近的研究表明,RL更新仅修改模型参数的一小部分,但这些观察通常基于粗略的检查点差异。我们对步进级别和多步粒度的权重更新稀疏性进行了系统的实证研究,考察了其在训练动态、离策略延迟和模型规模上的演变。我们发现,在实际相关的设置中,更新稀疏性始终很高,通常超过99%。利用这种结构,我们提出PULSE(通过无损稀疏编码进行补丁更新),这是一种简单但高效的无损权重同步方法,仅传输修改参数的索引和值。PULSE对传输错误具有鲁棒性,并避免了加性增量方案中固有的浮点漂移。在带宽受限的去中心化环境中,与完全权重同步相比,我们的方法实现了超过100倍(14 GB到约108 MB)的通信减少,同时保持了比特相同的训练动态和性能。通过利用这种结构,PULSE使去中心化RL训练接近中心化吞吐量,将权重同步所需的带宽从20 Gbit/s降低到0.2 Gbit/s,以保持高GPU利用率。
🔬 方法详解
问题定义:在分布式强化学习中,尤其是在带宽受限的去中心化环境中,策略权重的同步是主要的通信瓶颈。现有方法通常需要同步整个模型权重,即使只有一小部分参数被更新,导致大量的带宽浪费,限制了系统的可扩展性。
核心思路:论文的核心思路是观察到强化学习的权重更新具有高度的稀疏性,即每次更新只修改了模型参数的一小部分。因此,只需要传输这些被修改的参数的索引和值,而不是整个模型,从而显著减少通信量。
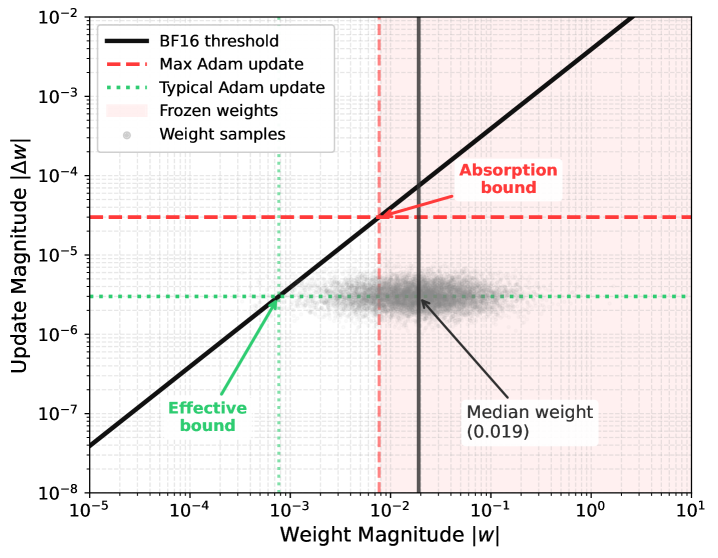
技术框架:PULSE方法的核心在于无损稀疏编码。它首先识别出被更新的参数,然后对这些参数的索引和值进行编码,并通过网络传输。接收方解码这些信息,并更新本地模型。整个过程保持了比特级别的精确性,避免了浮点漂移等问题。
关键创新:PULSE的关键创新在于它充分利用了强化学习权重更新的稀疏性,并设计了一种高效的无损稀疏编码方案。与传统的全量同步或增量同步方法相比,PULSE能够显著减少通信量,同时保持训练的准确性。
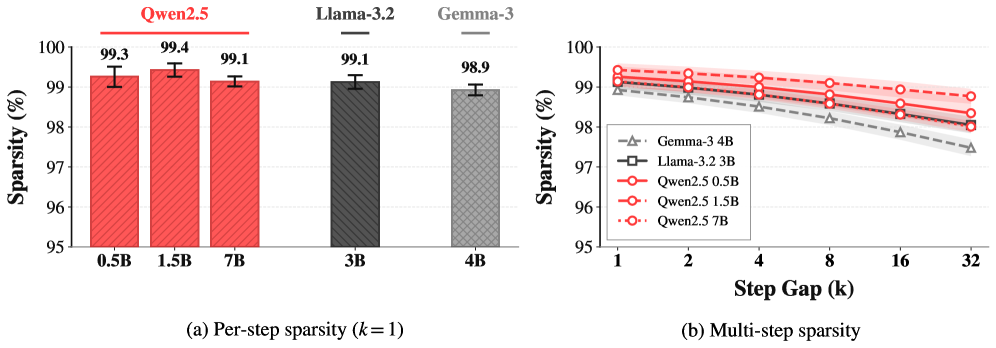
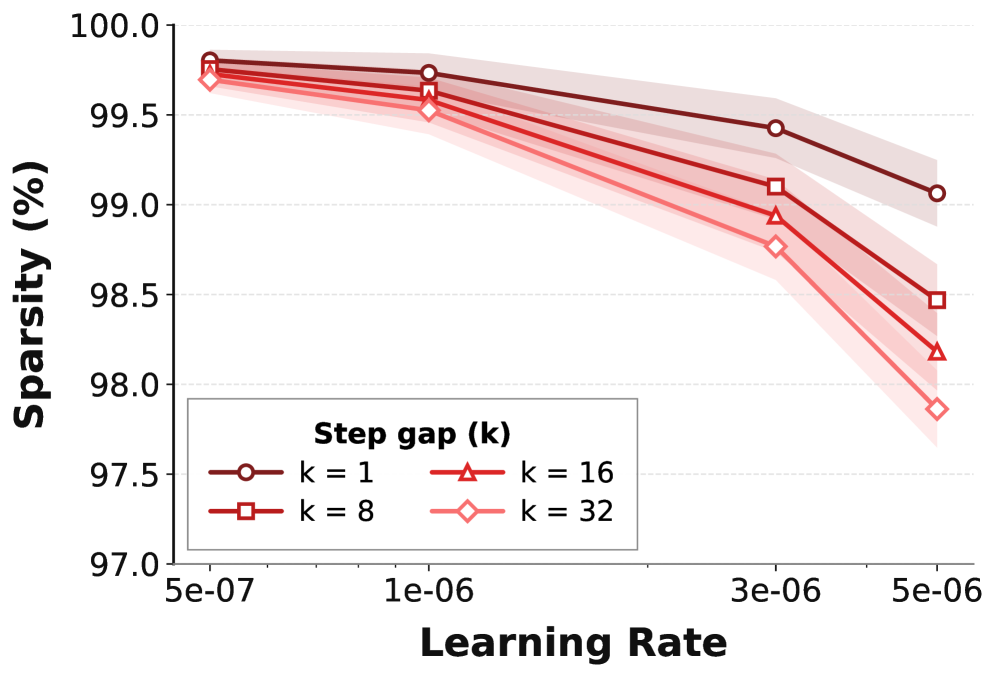
关键设计:PULSE的关键设计包括:1)高效的索引编码方案,用于压缩被更新参数的索引;2)鲁棒的传输协议,以应对网络传输错误;3)无损的数值编码,确保更新的精确性。论文还研究了不同训练动态、离策略延迟和模型规模下权重更新的稀疏性,为PULSE的设计提供了理论依据。
🖼️ 关键图片
📊 实验亮点
实验结果表明,PULSE方法在带宽受限的去中心化环境中实现了超过100倍的通信减少(从14 GB到约108 MB),同时保持了与全量权重同步相同的训练性能。此外,PULSE能够将权重同步所需的带宽从20 Gbit/s降低到0.2 Gbit/s,从而维持高GPU利用率,使去中心化RL训练接近中心化吞吐量。
🎯 应用场景
PULSE方法可广泛应用于带宽受限的分布式强化学习场景,例如边缘计算、联邦学习和去中心化训练。它能够降低通信成本,提高训练效率,并支持更大规模的模型训练。该方法对于资源受限的环境尤为重要,例如在移动设备或物联网设备上进行强化学习训练。
📄 摘要(原文)
Reinforcement learning (RL) is a critical component for post-training large language models (LLMs). However, in bandwidth-constrained distributed RL, scalability is often bottlenecked by the synchronization of policy weights from trainers to inference workers, particularly over commodity networks or in decentralized settings. While recent studies suggest that RL updates modify only a small fraction of model parameters, these observations are typically based on coarse checkpoint differences. We present a systematic empirical study of weight-update sparsity at both step-level and multi-step granularities, examining its evolution across training dynamics, off-policy delay, and model scale. We find that update sparsity is consistently high, frequently exceeding 99% across practically relevant settings. Leveraging this structure, we propose PULSE (Patch Updates via Lossless Sparse Encoding), a simple yet highly efficient lossless weight synchronization method that transmits only the indices and values of modified parameters. PULSE is robust to transmission errors and avoids floating-point drift inherent in additive delta schemes. In bandwidth-constrained decentralized environments, our approach achieves over 100x (14 GB to ~108 MB) communication reduction while maintaining bit-identical training dynamics and performance compared to full weight synchronization. By exploiting this structure, PULSE enables decentralized RL training to approach centralized throughput, reducing the bandwidth required for weight synchronization from 20 Gbit/s to 0.2 Gbit/s to maintain high GPU utilization.