Preference-based Conditional Treatment Effects and Policy Learning
作者: Dovid Parnas, Mathieu Even, Julie Josse, Uri Shalit
分类: stat.ML, cs.LG
发布日期: 2026-02-03
备注: Accepted to AISTATS 2026; 10 pages + appendix
💡 一句话要点
提出基于偏好的条件处理效应框架,用于异质性效应建模和策略学习
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 条件处理效应 策略学习 偏好学习 异质性效应 因果推断
📋 核心要点
- 现有方法在处理多元、有序或偏好驱动结果的异质性效应时存在建模上的局限性,难以有效估计条件处理效应。
- 论文提出CPTE框架,仅需结果在偏好规则下排序,即可灵活建模异质性效应,并统一多种应用场景。
- 通过合成和半合成实验,验证了所提方法在性能上的显著提升和实际应用价值,证明了其有效性。
📝 摘要(中文)
本文提出了一种新的基于偏好的条件处理效应估计和策略学习框架,该框架建立在条件偏好处理效应(CPTE)之上。CPTE仅要求结果在偏好规则下进行排序,从而能够灵活地对具有多元、有序或偏好驱动结果的异质性效应进行建模。这统一了诸如必要性和充分性的条件概率、条件胜率和广义成对比较等应用。尽管基于比较的估计量具有内在的不可识别性,但CPTE提供了可解释的目标,并为先前无法识别的估计量提供了新的可识别性条件。我们提出了通过匹配、分位数和分布回归的估计策略,并进一步设计了有效的影响函数估计器,以纠正插入偏差并最大化策略价值。合成和半合成实验证明了明显的性能提升和实际影响。
🔬 方法详解
问题定义:论文旨在解决异质性处理效应估计问题,尤其是在结果是多元、有序或基于偏好的情况下。现有方法在处理这些复杂类型的结果时,往往难以捕捉个体层面的偏好信息,导致估计偏差或无法有效进行策略学习。此外,一些重要的估计量(如必要性和充分性的条件概率)在传统框架下是不可识别的。
核心思路:论文的核心思路是引入基于偏好的条件处理效应(CPTE)框架。该框架不再直接依赖于具体的数值结果,而是利用个体对不同处理结果的偏好排序信息。通过这种方式,CPTE能够更灵活地处理各种类型的结果,并为不可识别的估计量提供新的可识别性条件。
技术框架:CPTE框架主要包含以下几个阶段:1) 定义偏好规则,将结果转化为偏好排序;2) 基于偏好排序,构建条件偏好处理效应(CPTE)估计量;3) 利用匹配、分位数回归或分布回归等方法估计CPTE;4) 设计基于影响函数的估计器,以纠正插入偏差并最大化策略价值。整体流程旨在利用偏好信息,更准确地估计个体层面的处理效应,并优化策略选择。
关键创新:论文最重要的技术创新在于提出了CPTE框架,它将偏好信息融入到处理效应估计中,从而能够处理更广泛类型的结果,并为先前不可识别的估计量提供了可识别性条件。此外,论文还设计了基于影响函数的估计器,以提高估计的准确性和效率。
关键设计:论文的关键设计包括:1) 灵活的偏好规则定义,可以根据具体应用场景选择合适的偏好关系;2) 基于匹配、分位数回归和分布回归的多种估计策略,以适应不同的数据分布;3) 基于影响函数的估计器,通过纠正插入偏差来提高估计精度;4) 策略价值最大化目标,指导策略学习过程。
🖼️ 关键图片

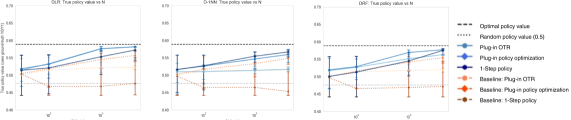
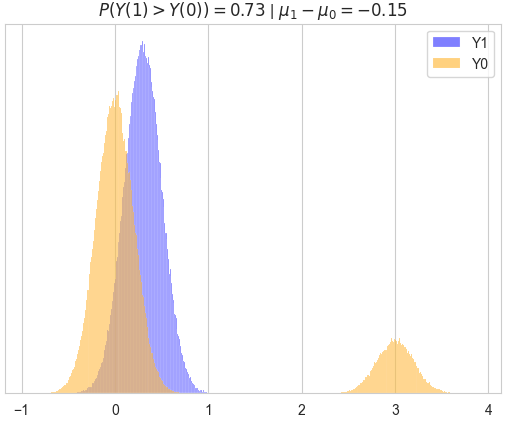
📊 实验亮点
实验结果表明,所提出的CPTE框架在合成和半合成数据集上均取得了显著的性能提升。与传统方法相比,CPTE能够更准确地估计条件处理效应,并实现更高的策略价值。具体而言,在某些实验中,CPTE的策略价值提升幅度超过10%,证明了其有效性和优越性。
🎯 应用场景
该研究成果可广泛应用于医疗决策、个性化推荐、教育干预等领域。例如,在医疗领域,可以根据患者对不同治疗方案的偏好,更准确地估计治疗效果,从而制定更个性化的治疗方案。在推荐系统中,可以根据用户的偏好排序,推荐更符合用户需求的产品或服务。该研究为异质性处理效应估计和策略学习提供了新的思路和方法,具有重要的实际应用价值和未来发展潜力。
📄 摘要(原文)
We introduce a new preference-based framework for conditional treatment effect estimation and policy learning, built on the Conditional Preference-based Treatment Effect (CPTE). CPTE requires only that outcomes be ranked under a preference rule, unlocking flexible modeling of heterogeneous effects with multivariate, ordinal, or preference-driven outcomes. This unifies applications such as conditional probability of necessity and sufficiency, conditional Win Ratio, and Generalized Pairwise Comparisons. Despite the intrinsic non-identifiability of comparison-based estimands, CPTE provides interpretable targets and delivers new identifiability conditions for previous unidentifiable estimands. We present estimation strategies via matching, quantile, and distributional regression, and further design efficient influence-function estimators to correct plug-in bias and maximize policy value. Synthetic and semi-synthetic experiments demonstrate clear performance gains and practical impact.