Bridging Online and Offline RL: Contextual Bandit Learning for Multi-Turn Code Generation
作者: Ziru Chen, Dongdong Chen, Ruinan Jin, Yingbin Liang, Yujia Xie, Huan Sun
分类: cs.LG, cs.AI, cs.CL, cs.SE
发布日期: 2026-02-03
🔗 代码/项目: GITHUB
💡 一句话要点
提出Cobalt方法,结合在线与离线强化学习,提升多轮代码生成性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多轮代码生成 强化学习 上下文Bandit 在线学习 离线学习 大型语言模型 奖励利用
📋 核心要点
- 在线强化学习训练成本高且不稳定,离线强化学习效果欠佳,现有方法难以兼顾效率与性能。
- Cobalt方法将多轮代码生成视为单步可恢复MDP,利用上下文bandit学习结合在线与离线RL的优势。
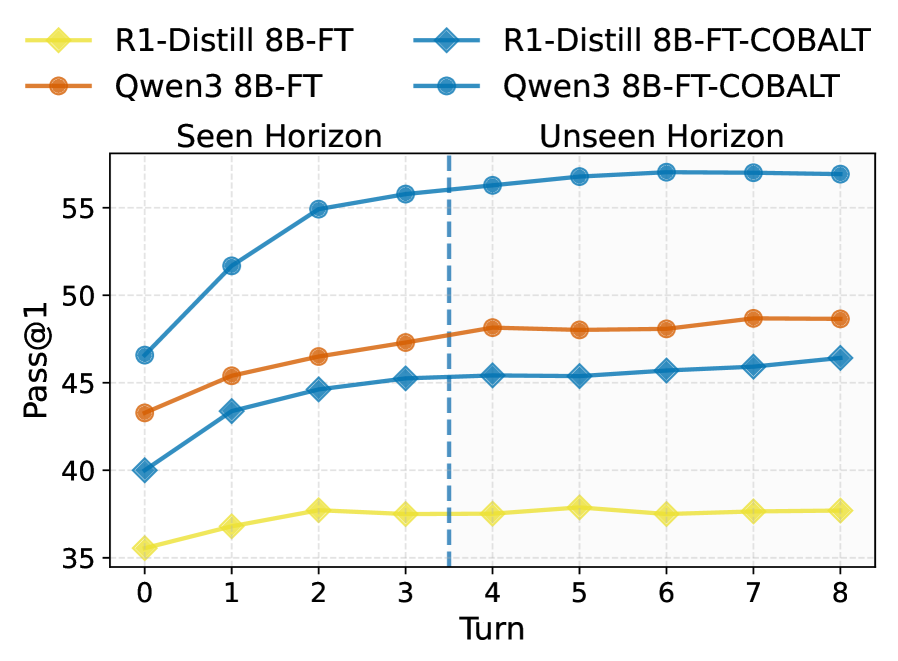
- 实验表明,Cobalt显著提升了LLM在LiveCodeBench上的Pass@1分数,优于现有在线RL基线。
📝 摘要(中文)
近年来,使用强化学习(RL)训练大型语言模型(LLM)以解决现实世界任务(如多轮代码生成)引起了广泛的研究兴趣。虽然在线RL通常比离线RL表现更好,但其更高的训练成本和不稳定性阻碍了广泛应用。本文基于多轮代码生成可以被形式化为单步可恢复马尔可夫决策过程的观察,提出了一种结合在线和离线RL优势的上下文bandit学习方法(Cobalt)。Cobalt首先使用参考LLM收集代码生成轨迹,并将它们分成部分轨迹作为上下文提示。然后,在在线bandit学习期间,LLM被训练通过单步代码生成来完成每个部分轨迹提示。Cobalt优于基于GRPO和VeRPO的两种多轮在线RL基线,并在LiveCodeBench上将R1-Distill 8B和Qwen3 8B的Pass@1分数分别提高了高达9.0和6.2个绝对百分点。此外,我们分析了LLM的上下文奖励利用行为,并通过增强扰动轨迹的Cobalt训练来缓解此问题。总的来说,我们的结果表明Cobalt是迭代决策任务(如多轮代码生成)的一种有前途的解决方案。我们的代码和数据可在https://github.com/OSU-NLP-Group/cobalt获得。
🔬 方法详解
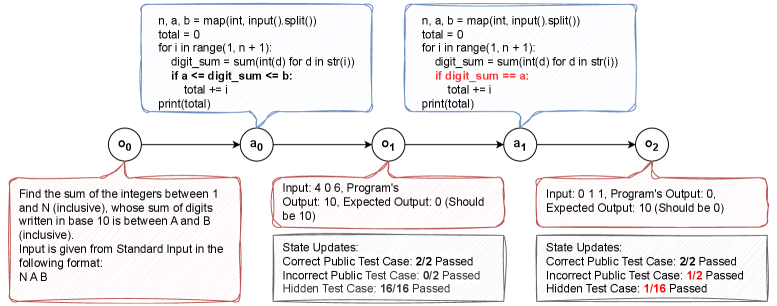
问题定义:论文旨在解决多轮代码生成任务中,在线强化学习训练成本高昂且不稳定,而离线强化学习性能不足的问题。现有方法难以在训练效率和模型性能之间取得平衡。
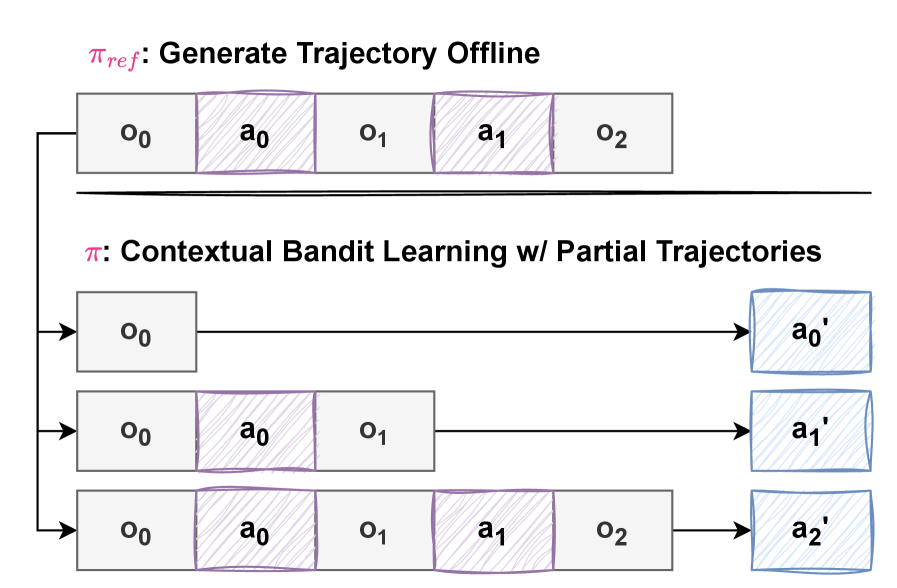
核心思路:论文的核心思路是将多轮代码生成过程建模为单步可恢复的马尔可夫决策过程(MDP),并利用上下文bandit学习框架,结合离线数据和在线探索的优势。通过将完整的代码生成轨迹分解为多个单步决策,降低了训练的复杂性。
技术框架:Cobalt方法包含以下主要阶段:1) 离线数据收集:使用一个参考LLM生成代码生成轨迹。2) 轨迹分割:将完整的轨迹分割成多个部分轨迹,作为上下文提示。3) 在线bandit学习:训练LLM以完成每个部分轨迹提示,通过单步代码生成。在每个步骤中,模型根据上下文选择动作(生成代码),并根据环境反馈获得奖励。
关键创新:Cobalt的关键创新在于将多轮决策问题转化为单步bandit学习问题,从而能够有效地利用离线数据进行预训练,并结合在线探索进行微调。这种方法避免了传统在线RL的高方差和样本效率低下的问题,同时也克服了离线RL泛化能力不足的缺点。
关键设计:Cobalt使用Pass@1作为奖励信号,鼓励模型生成正确的代码。为了缓解LLM的奖励利用行为,论文还引入了扰动轨迹,通过在训练数据中加入噪声来提高模型的鲁棒性。具体的损失函数和网络结构细节未在摘要中详细说明,需要参考原文。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Cobalt方法在LiveCodeBench数据集上显著优于现有的在线RL基线(GRPO和VeRPO)。具体而言,Cobalt将R1-Distill 8B和Qwen3 8B的Pass@1分数分别提高了高达9.0和6.2个绝对百分点,证明了其在多轮代码生成任务中的有效性。
🎯 应用场景
Cobalt方法具有广泛的应用前景,可应用于各种需要迭代决策的任务,例如对话系统、机器人控制和自动驾驶等。通过结合离线数据和在线学习,可以显著降低训练成本,提高模型性能,并加速LLM在实际场景中的部署。
📄 摘要(原文)
Recently, there have been significant research interests in training large language models (LLMs) with reinforcement learning (RL) on real-world tasks, such as multi-turn code generation. While online RL tends to perform better than offline RL, its higher training cost and instability hinders wide adoption. In this paper, we build on the observation that multi-turn code generation can be formulated as a one-step recoverable Markov decision process and propose contextual bandit learning with offline trajectories (Cobalt), a new method that combines the benefits of online and offline RL. Cobalt first collects code generation trajectories using a reference LLM and divides them into partial trajectories as contextual prompts. Then, during online bandit learning, the LLM is trained to complete each partial trajectory prompt through single-step code generation. Cobalt outperforms two multi-turn online RL baselines based on GRPO and VeRPO, and substantially improves R1-Distill 8B and Qwen3 8B by up to 9.0 and 6.2 absolute Pass@1 scores on LiveCodeBench. Also, we analyze LLMs' in-context reward hacking behaviors and augment Cobalt training with perturbed trajectories to mitigate this issue. Overall, our results demonstrate Cobalt as a promising solution for iterative decision-making tasks like multi-turn code generation. Our code and data are available at https://github.com/OSU-NLP-Group/cobalt.