Efficient Estimation of Kernel Surrogate Models for Task Attribution
作者: Zhenshuo Zhang, Minxuan Duan, Hongyang R. Zhang
分类: cs.LG, cs.AI, cs.CL
发布日期: 2026-02-03
备注: 27 pages. To appear in ICLR 2026
💡 一句话要点
提出基于核函数的代理模型,高效评估训练任务对目标任务的影响。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 任务归因 核代理模型 非线性建模 梯度估计 模型优化
📋 核心要点
- 现有线性代理模型无法捕捉训练任务间复杂的非线性交互关系,限制了任务归因的准确性。
- 提出核代理模型,利用核函数有效建模二阶任务交互,提升任务归因的准确性。
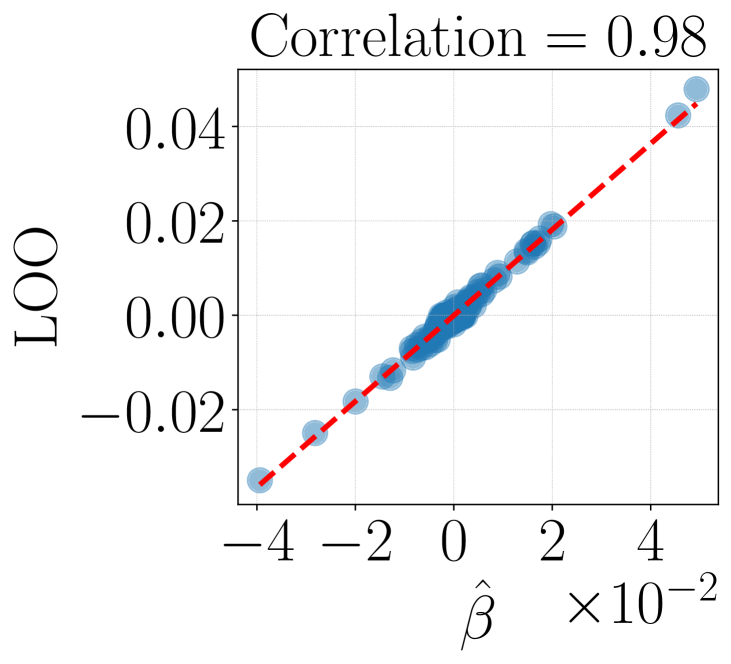
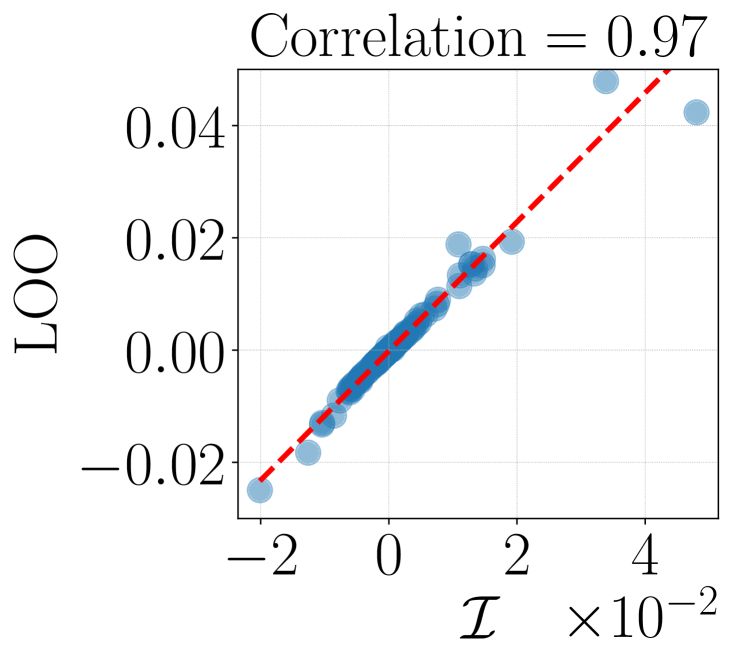
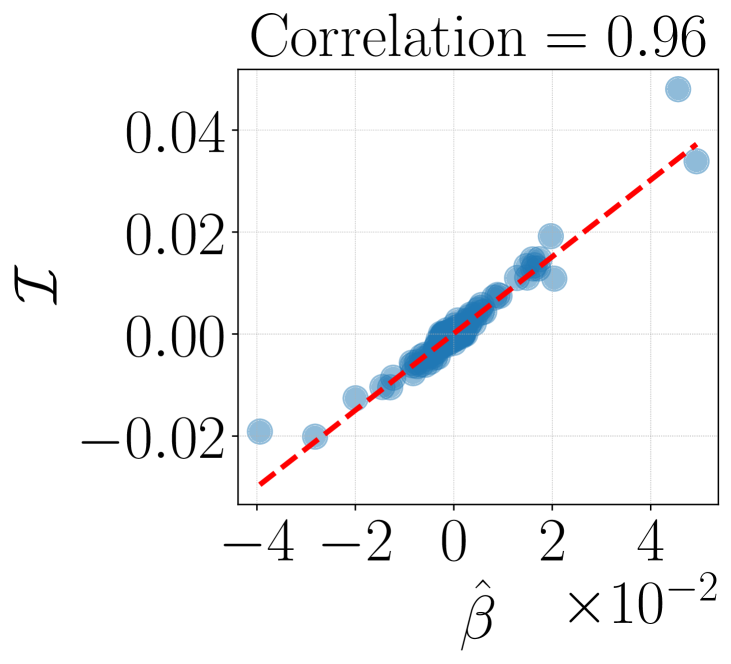
- 实验表明,核代理模型在多个领域优于线性模型,与留一法真实值的相关性提升25%。
📝 摘要(中文)
现代人工智能体,如大型语言模型,同时在翻译、代码生成、数学推理和文本预测等多样化任务上进行训练。一个关键问题是量化每个单独的训练任务如何影响目标任务的性能,我们将此问题称为任务归因。直接方法,即留一法重训练,测量移除每个任务的效果,但在大规模情况下计算上不可行。另一种方法是构建代理模型来预测任何训练任务子集的目标任务性能,这种方法已出现在最近的文献中。先前的工作侧重于线性代理模型,它捕获一阶关系,但忽略了非线性交互,如协同、对抗或异或类型效应。在本文中,我们首先考虑一个统一的任务加权框架来分析任务归因方法,并通过二阶分析展示了线性代理模型和影响函数之间的新联系。然后,我们引入了核代理模型,它可以更有效地表示二阶任务交互。为了有效地学习核代理,我们开发了一种基于梯度的估计程序,该程序利用预训练模型的一阶近似;经验表明,这产生了准确的估计,相对误差小于 2%,而无需重复重训练。跨多个领域的实验——包括 transformers 中的数学推理、上下文学习和多目标强化学习——证明了核代理模型的有效性。它们实现了比线性代理和影响函数基线高 25% 的与留一法真实值的相关性。当用于下游任务选择时,核代理模型在上下文学习和多目标强化学习基准测试中,在演示选择方面产生了 40% 的改进。
🔬 方法详解
问题定义:论文旨在解决任务归因问题,即量化不同训练任务对目标任务性能的影响。现有方法,如留一法重训练,计算成本过高。线性代理模型虽然计算效率较高,但无法捕捉训练任务之间复杂的非线性交互关系,导致任务归因不准确。
核心思路:论文的核心思路是使用核函数来建模训练任务之间的非线性交互关系。通过构建核代理模型,可以更准确地预测不同训练任务组合对目标任务性能的影响,从而实现更有效的任务归因。这种方法旨在在计算效率和模型精度之间取得平衡。
技术框架:整体框架包含以下几个主要步骤:1) 建立统一的任务加权框架,用于分析不同的任务归因方法。2) 推导线性代理模型和影响函数之间的联系,为后续的核代理模型设计提供理论基础。3) 构建核代理模型,利用核函数捕捉二阶任务交互。4) 开发基于梯度的估计程序,高效学习核代理模型,避免重复重训练。
关键创新:最关键的创新点在于引入了核代理模型来建模任务间的非线性交互。与传统的线性代理模型相比,核代理模型能够更准确地捕捉任务之间的协同、对抗等复杂关系,从而提升任务归因的准确性。此外,基于梯度的估计程序也提高了核代理模型的学习效率。
关键设计:论文的关键设计包括:1) 选择合适的核函数,例如高斯核或多项式核,以捕捉任务间的非线性关系。2) 设计基于梯度的估计程序,利用预训练模型的一阶近似来加速核代理模型的学习过程。3) 针对不同的应用场景,调整核函数的参数,例如带宽或多项式次数,以优化模型的性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,核代理模型在多个领域(包括 transformers 中的数学推理、上下文学习和多目标强化学习)均优于线性代理模型和影响函数基线。与留一法真实值的相关性提高了 25%。在下游任务选择中,核代理模型在上下文学习和多目标强化学习基准测试中,在演示选择方面产生了 40% 的改进。
🎯 应用场景
该研究成果可应用于大型语言模型的训练优化,例如通过任务归因选择更有助于目标任务提升的训练数据,从而提高模型性能和训练效率。此外,该方法还可用于多目标强化学习中,选择合适的任务组合以优化整体性能。
📄 摘要(原文)
Modern AI agents such as large language models are trained on diverse tasks -- translation, code generation, mathematical reasoning, and text prediction -- simultaneously. A key question is to quantify how each individual training task influences performance on a target task, a problem we refer to as task attribution. The direct approach, leave-one-out retraining, measures the effect of removing each task, but is computationally infeasible at scale. An alternative approach that builds surrogate models to predict a target task's performance for any subset of training tasks has emerged in recent literature. Prior work focuses on linear surrogate models, which capture first-order relationships, but miss nonlinear interactions such as synergy, antagonism, or XOR-type effects. In this paper, we first consider a unified task weighting framework for analyzing task attribution methods, and show a new connection between linear surrogate models and influence functions through a second-order analysis. Then, we introduce kernel surrogate models, which more effectively represent second-order task interactions. To efficiently learn the kernel surrogate, we develop a gradient-based estimation procedure that leverages a first-order approximation of pretrained models; empirically, this yields accurate estimates with less than $2\%$ relative error without repeated retraining. Experiments across multiple domains -- including math reasoning in transformers, in-context learning, and multi-objective reinforcement learning -- demonstrate the effectiveness of kernel surrogate models. They achieve a $25\%$ higher correlation with the leave-one-out ground truth than linear surrogates and influence-function baselines. When used for downstream task selection, kernel surrogate models yield a $40\%$ improvement in demonstration selection for in-context learning and multi-objective reinforcement learning benchmarks.