UniGeM: Unifying Data Mixing and Selection via Geometric Exploration and Mining
作者: Changhao Wang, Yunfei Yu, Xinhao Yao, Jiaolong Yang, Riccardo Cantoro, Chaobo Li, Qing Cui, Jun Zhou
分类: cs.LG, cs.AI
发布日期: 2026-02-03
💡 一句话要点
UniGeM:通过几何探索与挖掘统一数据混合与选择,提升LLM数据效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数据混合 样本选择 流形近似 几何探索 大规模语言模型
📋 核心要点
- 现有数据管理方法通常独立处理数据混合和样本选择,忽略了代码语料库的内在结构。
- UniGeM将数据管理视为流形近似问题,通过几何探索与挖掘统一数据混合与选择,无需额外模型。
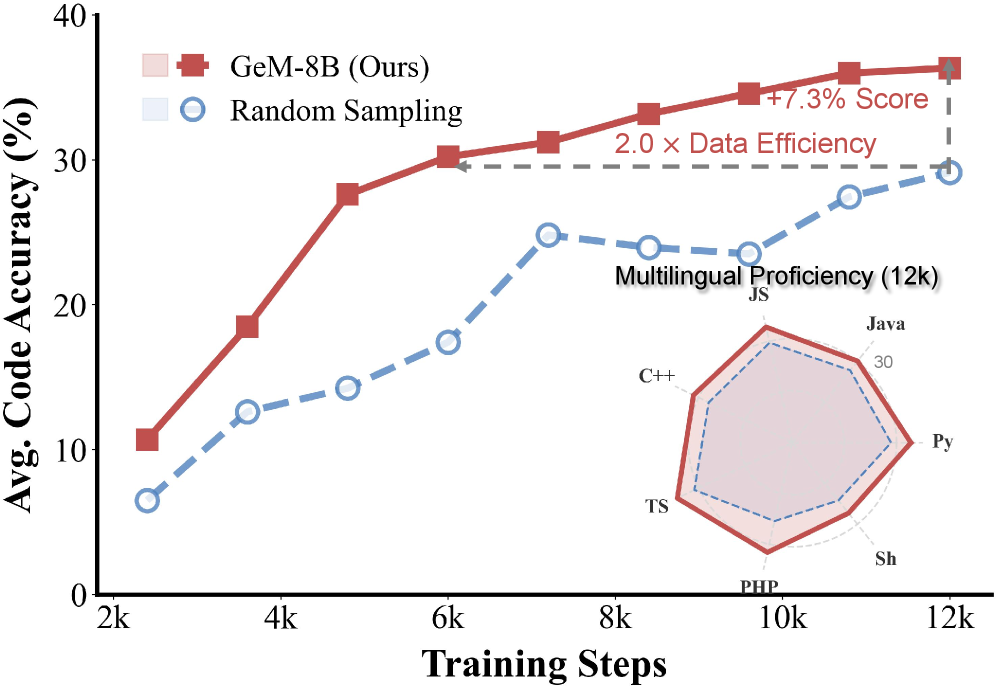
- 实验表明,UniGeM在数据效率上优于随机基线2倍,并在推理和多语言泛化上超越SOTA方法。
📝 摘要(中文)
大规模语言模型(LLMs)的扩展日益受到数据质量的限制。现有方法通常独立处理数据混合和样本选择,这可能会破坏代码语料库中的结构。本文提出UniGeM,一个通过将数据管理视为 extit{流形近似}问题来统一混合和选择的框架,无需训练代理模型或依赖外部参考数据集。UniGeM分层运行: extbf{宏观探索}通过基于稳定性的聚类学习混合权重; extbf{微观挖掘}通过实例的几何分布过滤高质量实例,以确保逻辑一致性。通过在100B tokens上训练8B和16B MoE模型进行验证,UniGeM实现了超过随机基线 extbf{2.0倍的数据效率},并且在推理密集型评估和多语言泛化方面,相比SOTA方法进一步提高了整体性能。
🔬 方法详解
问题定义:现有的大规模语言模型训练受限于数据质量,而传统的数据混合和样本选择方法通常是独立进行的,忽略了数据之间的内在联系,尤其是在代码语料库中,这种独立处理方式容易破坏代码的结构和逻辑一致性。因此,如何有效地混合和选择高质量的数据,同时保持数据的内在结构,是本文要解决的关键问题。
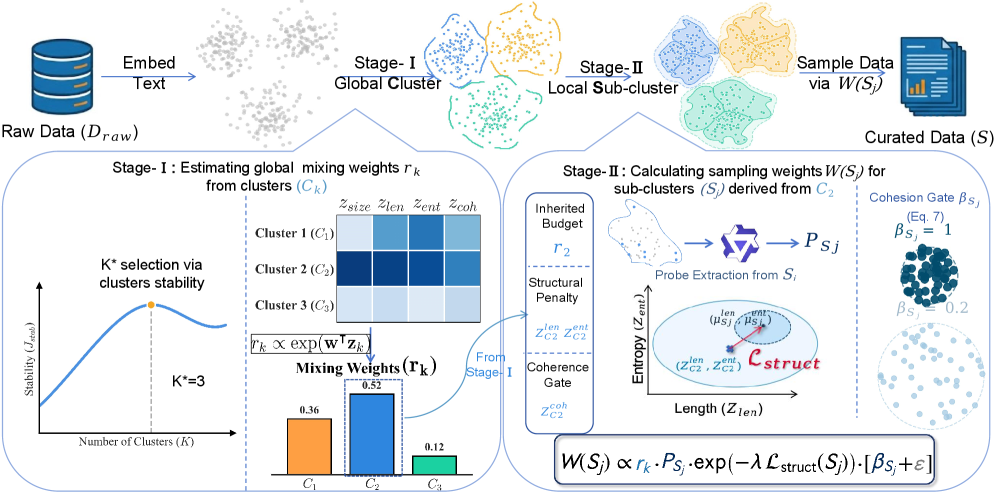
核心思路:UniGeM的核心思路是将数据管理问题转化为一个流形近似问题。它假设高质量的数据点在特征空间中形成一个低维流形,通过探索数据的几何结构,可以更好地进行数据混合和样本选择。这种方法避免了训练代理模型或依赖外部参考数据集,从而降低了计算成本和对外部资源的依赖。
技术框架:UniGeM框架包含两个主要阶段:宏观探索(Macro-Exploration)和微观挖掘(Micro-Mining)。在宏观探索阶段,使用基于稳定性的聚类方法学习不同数据集的混合权重,以确定不同数据源的相对重要性。在微观挖掘阶段,根据数据点在其局部几何环境中的分布情况,过滤掉低质量的实例,从而保证数据的逻辑一致性。
关键创新:UniGeM的关键创新在于它将数据混合和样本选择统一到一个框架中,并通过几何探索和挖掘的方式来解决数据质量问题。与传统的独立处理方法相比,UniGeM能够更好地保持数据的内在结构和逻辑一致性。此外,UniGeM不需要训练代理模型或依赖外部参考数据集,降低了计算成本和对外部资源的依赖。
关键设计:在宏观探索阶段,UniGeM使用基于稳定性的聚类算法来确定不同数据集的混合权重。具体来说,它通过多次随机采样和聚类,评估每个数据集中样本聚类结果的稳定性,稳定性高的数据集被赋予更高的权重。在微观挖掘阶段,UniGeM根据数据点在其局部几何环境中的分布情况,计算每个数据点的质量得分,并根据得分过滤掉低质量的实例。具体的质量得分计算方法和过滤阈值需要根据具体的数据集和任务进行调整。
🖼️ 关键图片
📊 实验亮点
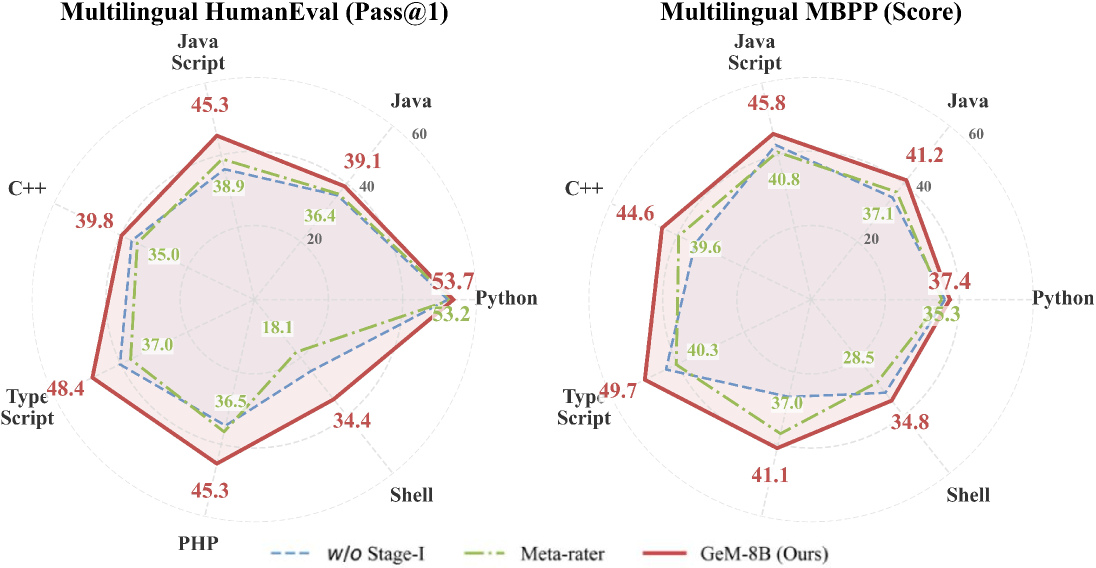
UniGeM在训练8B和16B MoE模型时,实现了2.0倍于随机基线的数据效率。在推理密集型评估和多语言泛化方面,UniGeM也显著优于现有的SOTA方法,表明其在提升模型性能和数据利用率方面的有效性。这些实验结果验证了UniGeM在实际应用中的价值。
🎯 应用场景
UniGeM可应用于大规模语言模型的预训练数据管理,提高数据质量和训练效率。该方法能够有效提升模型在代码生成、推理和多语言处理等任务上的性能,降低训练成本,并促进更高效、更可靠的AI系统开发。此外,该方法也可以推广到其他领域,例如图像识别、自然语言处理等,用于提升数据质量和模型性能。
📄 摘要(原文)
The scaling of Large Language Models (LLMs) is increasingly limited by data quality. Most methods handle data mixing and sample selection separately, which can break the structure in code corpora. We introduce \textbf{UniGeM}, a framework that unifies mixing and selection by treating data curation as a \textit{manifold approximation} problem without training proxy models or relying on external reference datasets. UniGeM operates hierarchically: \textbf{Macro-Exploration} learns mixing weights with stability-based clustering; \textbf{Micro-Mining} filters high-quality instances by their geometric distribution to ensure logical consistency. Validated by training 8B and 16B MoE models on 100B tokens, UniGeM achieves \textbf{2.0$\times$ data efficiency} over a random baseline and further improves overall performance compared to SOTA methods in reasoning-heavy evaluations and multilingual generalization.