Conditional Flow Matching for Visually-Guided Acoustic Highlighting
作者: Hugo Malard, Gael Le Lan, Daniel Wong, David Lou Alon, Yi-Chiao Wu, Sanjeel Parekh
分类: eess.AS, cs.LG
发布日期: 2026-02-03
💡 一句话要点
提出基于条件流匹配的视觉引导声学增强方法,解决音频重混中的歧义性问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 视觉引导 声学增强 条件流匹配 生成模型 音频重混
📋 核心要点
- 现有视觉引导声学增强方法依赖判别模型,难以处理音频重混的歧义性,导致视听焦点不一致。
- 论文提出基于条件流匹配(CFM)的生成模型,通过引入rollout损失来稳定长程流积分,实现跨模态源选择。
- 实验结果表明,该方法在视觉引导音频重混任务中,显著优于现有判别模型,验证了生成建模的有效性。
📝 摘要(中文)
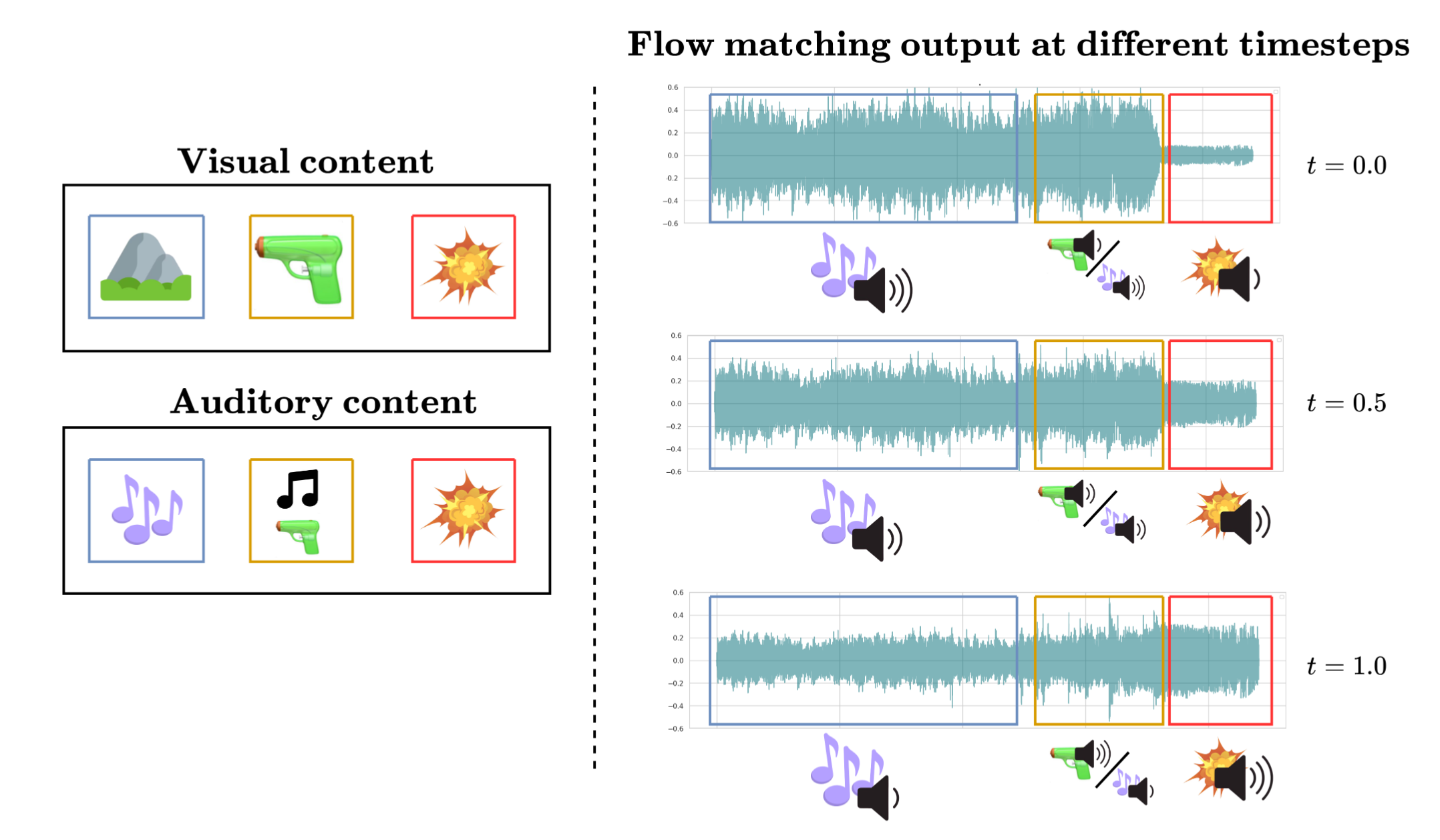
本文提出了一种基于条件流匹配(CFM)框架的视觉引导声学增强方法,旨在根据视频内容重新平衡音频,创造连贯的视听体验。现有方法通常使用判别模型,难以处理音频重混中固有的歧义性,因为不良混音和良好混音之间不存在自然的一对一映射。为了解决这个问题,我们将该任务重新定义为一个生成问题。迭代流生成的一个关键挑战是,早期预测误差会在后续步骤中累积,导致轨迹偏离流形。为此,我们引入了一个rollout损失,以惩罚最后一步的漂移,从而鼓励自我校正轨迹并稳定长程流积分。此外,我们还提出了一个条件模块,该模块在向量场回归之前融合音频和视觉线索,从而实现显式的跨模态源选择。大量的定量和定性评估表明,我们的方法始终优于先前的最先进的判别方法,证明了视觉引导的音频重混最好通过生成建模来解决。
🔬 方法详解
问题定义:视觉引导声学增强旨在根据视频内容调整音频,使视听体验更加协调。现有方法,特别是基于判别模型的方法,在处理音频重混任务时面临挑战。这是因为从不良混音到良好混音的映射并非一一对应,存在固有的歧义性,导致判别模型难以学习到准确的映射关系。现有方法容易产生视听焦点不一致的问题。
核心思路:本文将视觉引导声学增强任务重新定义为一个生成问题,并采用条件流匹配(CFM)框架。核心思想是学习一个连续的向量场,将不良混音逐步转换为良好混音。通过生成模型,可以更好地处理音频重混中的歧义性,并生成更符合视觉内容的音频。
技术框架:该方法包含以下主要模块:1) 音频和视频特征提取模块,用于提取音频和视频的特征表示。2) 条件模块,用于融合音频和视频特征,生成条件向量。3) 基于条件流匹配的生成模块,该模块学习一个连续的向量场,将输入音频逐步转换为目标音频。4) Rollout损失,用于稳定长程流积分,防止早期预测误差累积。整体流程是:输入音频和视频,提取特征,融合特征,通过生成模块逐步调整音频,最后输出增强后的音频。
关键创新:最重要的技术创新点在于将视觉引导声学增强任务建模为生成问题,并引入条件流匹配框架。与现有判别模型相比,该方法能够更好地处理音频重混中的歧义性。此外,Rollout损失的引入有效解决了迭代流生成中常见的误差累积问题,提高了生成质量。
关键设计:条件模块的设计至关重要,它负责融合音频和视频信息,为生成过程提供指导。Rollout损失的具体形式是惩罚生成轨迹在最后一步的漂移,鼓励模型学习自我校正的轨迹。网络结构方面,使用了标准的神经网络结构进行向量场回归。具体的参数设置和网络结构细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在视觉引导声学增强任务中, consistently 优于先前的最先进的判别方法。具体的性能数据和提升幅度未在摘要中明确给出,属于未知信息。定性评估也表明,该方法能够生成更符合视觉内容的音频,提升视听体验。
🎯 应用场景
该研究成果可应用于视频编辑、直播、游戏等领域,提升视听体验。例如,在视频编辑中,可以自动根据视频内容调整音频,突出关键声音,使视听效果更具吸引力。在直播场景中,可以根据主播的动作和表情,实时调整音频,增强互动性。未来,该技术有望应用于更广泛的视听内容创作和增强领域。
📄 摘要(原文)
Visually-guided acoustic highlighting seeks to rebalance audio in alignment with the accompanying video, creating a coherent audio-visual experience. While visual saliency and enhancement have been widely studied, acoustic highlighting remains underexplored, often leading to misalignment between visual and auditory focus. Existing approaches use discriminative models, which struggle with the inherent ambiguity in audio remixing, where no natural one-to-one mapping exists between poorly-balanced and well-balanced audio mixes. To address this limitation, we reframe this task as a generative problem and introduce a Conditional Flow Matching (CFM) framework. A key challenge in iterative flow-based generation is that early prediction errors -- in selecting the correct source to enhance -- compound over steps and push trajectories off-manifold. To address this, we introduce a rollout loss that penalizes drift at the final step, encouraging self-correcting trajectories and stabilizing long-range flow integration. We further propose a conditioning module that fuses audio and visual cues before vector field regression, enabling explicit cross-modal source selection. Extensive quantitative and qualitative evaluations show that our method consistently surpasses the previous state-of-the-art discriminative approach, establishing that visually-guided audio remixing is best addressed through generative modeling.