Anytime Pretraining: Horizon-Free Learning-Rate Schedules with Weight Averaging
作者: Alexandru Meterez, Pranav Ajit Nair, Depen Morwani, Cengiz Pehlevan, Sham Kakade
分类: cs.LG, cs.AI, math.OC, stat.ML
发布日期: 2026-02-03
💡 一句话要点
提出无时间限制的学习率调度与权重平均以优化语言模型预训练
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 学习率调度 权重平均 语言模型 开放式训练 随机梯度下降
📋 核心要点
- 现有的预训练方法往往依赖于固定的学习率调度,缺乏灵活性,难以适应开放式训练环境。
- 本文提出了一种无时间限制的学习率调度方案,结合权重平均以提高模型的收敛速度和效果。
- 实验结果显示,无时间限制的调度在最终损失上与传统余弦调度相当,展示了其有效性。
📝 摘要(中文)
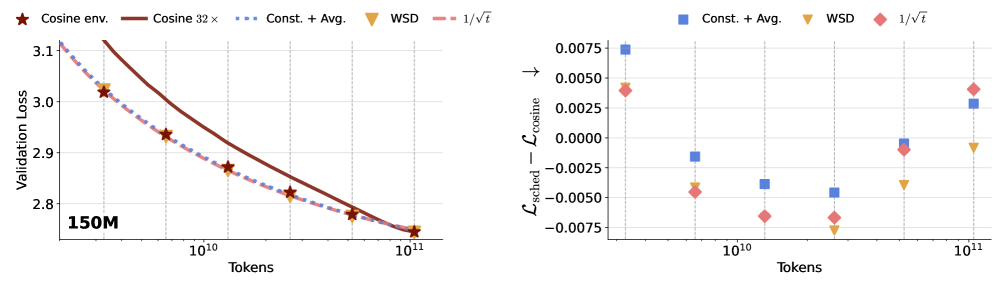
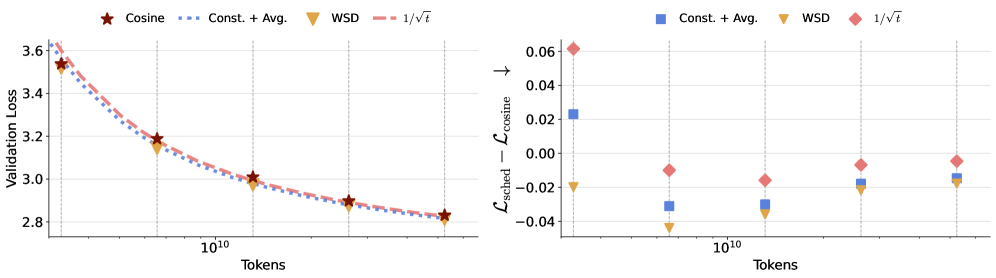
随着大型语言模型在持续或开放式环境中的训练日益增多,现有的预训练方法往往依赖于固定的学习率调度和计算预算,缺乏灵活性。本文提供了理论分析,证明了过参数线性回归中存在无时间限制的学习调度,并强调了权重平均在随机梯度下降中的重要性。我们展示了这些调度随时间多项式衰减,衰减速率由问题的源和容量条件决定。通过对150M和300M参数的语言模型进行实验,比较了常数学习率与权重平均、$1/ ext{sqrt{t}}$调度与权重平均相较于经过良好调优的余弦调度的效果,结果表明无时间限制的调度在整个训练范围内达到了与余弦衰减相当的最终损失。
🔬 方法详解
问题定义:本文旨在解决现有预训练方法在开放式训练环境中缺乏灵活性的问题,尤其是依赖于固定学习率调度的局限性。
核心思路:提出了一种无时间限制的学习率调度方案,结合权重平均技术,以实现更好的收敛性能和适应性。
技术框架:整体架构包括理论分析和实验验证两个部分,理论部分探讨了权重平均在收敛中的作用,实验部分则比较了不同学习率调度的效果。
关键创新:最重要的创新在于提出了无时间限制的学习率调度,结合权重平均技术,显著提高了模型的收敛速度,与传统方法相比具有更好的适应性。
关键设计:在实验中,采用了150M和300M参数的语言模型,比较了常数学习率与权重平均、$1/ ext{sqrt{t}}$调度与权重平均的效果,确保了实验的全面性和可靠性。
🖼️ 关键图片
📊 实验亮点
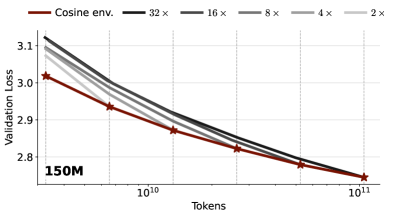
实验结果表明,采用无时间限制的学习率调度结合权重平均的模型在最终损失上与经过良好调优的余弦调度相当,展示了其在150M和300M参数模型上的有效性,提供了一种新的预训练策略。
🎯 应用场景
该研究的潜在应用领域包括自然语言处理、对话系统和其他需要大规模语言模型的任务。通过提供灵活的学习率调度方案,能够在动态环境中更有效地训练模型,提升实际应用的性能和效率。
📄 摘要(原文)
Large language models are increasingly trained in continual or open-ended settings, where the total training horizon is not known in advance. Despite this, most existing pretraining recipes are not anytime: they rely on horizon-dependent learning rate schedules and extensive tuning under a fixed compute budget. In this work, we provide a theoretical analysis demonstrating the existence of anytime learning schedules for overparameterized linear regression, and we highlight the central role of weight averaging - also known as model merging - in achieving the minimax convergence rates of stochastic gradient descent. We show that these anytime schedules polynomially decay with time, with the decay rate determined by the source and capacity conditions of the problem. Empirically, we evaluate 150M and 300M parameter language models trained at 1-32x Chinchilla scale, comparing constant learning rates with weight averaging and $1/\sqrt{t}$ schedules with weight averaging against a well-tuned cosine schedule. Across the full training range, the anytime schedules achieve comparable final loss to cosine decay. Taken together, our results suggest that weight averaging combined with simple, horizon-free step sizes offers a practical and effective anytime alternative to cosine learning rate schedules for large language model pretraining.