LLM-Inspired Pretrain-Then-Finetune for Small-Data, Large-Scale Optimization
作者: Zishi Zhang, Jinhui Han, Ming Hu, Yijie Peng
分类: cs.LG, cs.AI
发布日期: 2026-02-03
💡 一句话要点
提出基于LLM的预训练-微调框架,解决小数据大规模优化决策问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 预训练 微调 Transformer 小数据学习 大规模优化
📋 核心要点
- 现有方法在小数据、大规模决策问题中面临挑战,难以有效利用领域知识和跨任务结构。
- 借鉴LLM的预训练-微调思想,设计Transformer模型,先在合成数据上预训练,再在真实数据上微调。
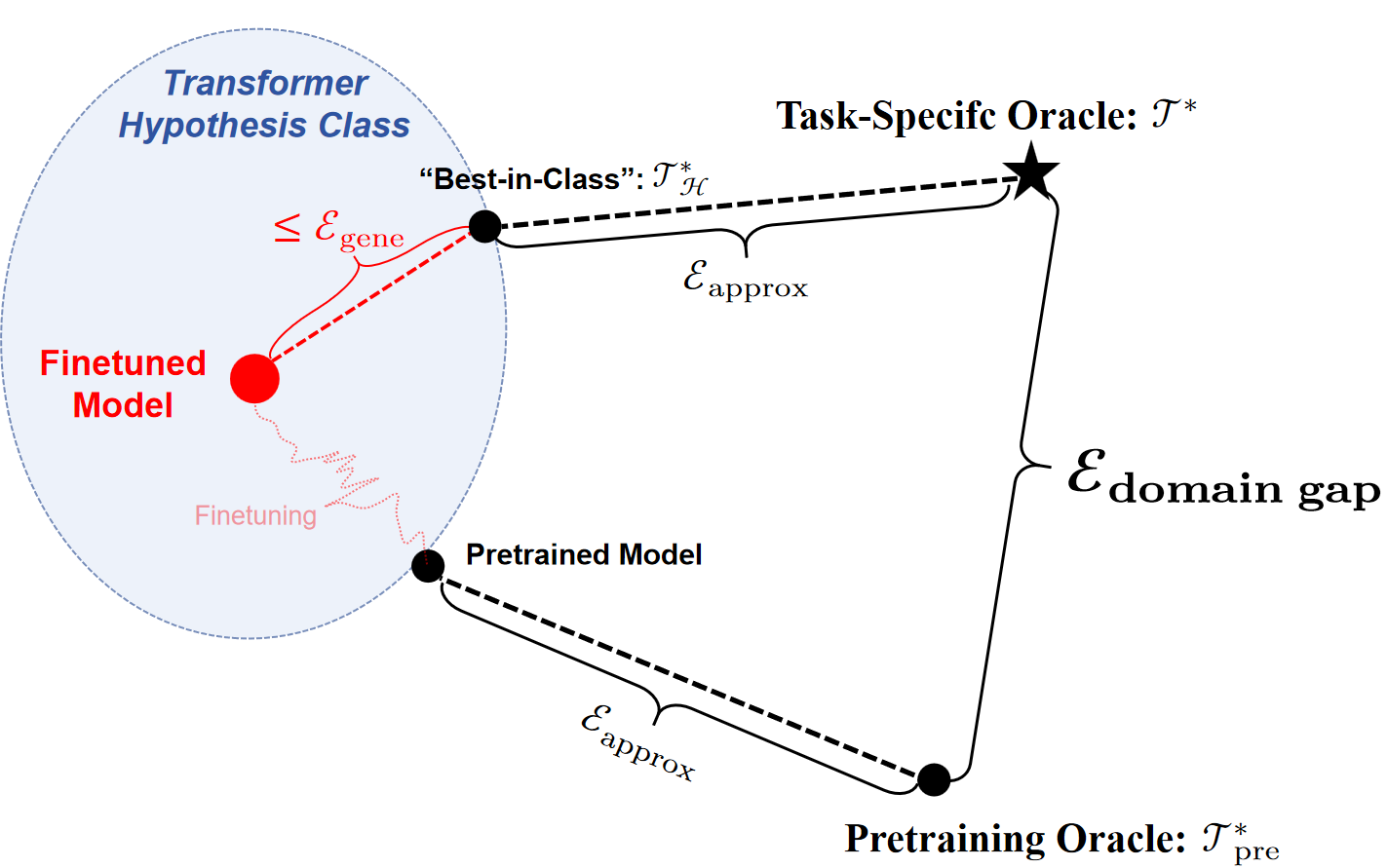
- 理论分析表明预训练和微调共同决定性能,微调具有规模经济效应,实例越多迁移学习越有效。
📝 摘要(中文)
本文针对小数据、大规模决策问题,即企业必须同时做出大量运营决策(例如,跨越大型产品组合),而每个实例仅观察到少量、可能存在噪声的数据点。受大型语言模型(LLM)成功的启发,我们提出了一种基于Transformer模型的预训练-微调方法来应对这一挑战。该模型首先在大型、领域相关的合成数据上进行预训练,这些数据编码了管理知识和决策环境的结构特征,然后根据真实观测数据进行微调。这种新流程提供了两个互补的优势:预训练将领域知识注入到学习过程中,并能够使用丰富的合成数据训练高容量模型,而微调使预训练模型适应运营环境,并改善与真实数据生成机制的对齐。虽然我们利用了Transformer最先进的表征能力,特别是其注意力机制,以有效地提取跨任务结构,但我们的方法并非现成的应用。相反,它依赖于针对特定问题的架构设计和量身定制的训练程序来匹配决策环境。理论上,我们对Transformer在相关上下文中的学习进行了首次全面的误差分析,建立了验证该方法有效性的非渐近保证。至关重要的是,我们的分析揭示了预训练和微调如何共同决定性能,其中主要贡献取决于哪个更有利。特别是,微调表现出规模经济效应,随着实例数量的增长,迁移学习变得越来越有效。
🔬 方法详解
问题定义:论文旨在解决小数据、大规模决策问题,例如企业需要在少量数据下对大量产品组合进行运营决策。现有方法难以有效利用领域知识和跨任务结构,导致决策效果不佳。
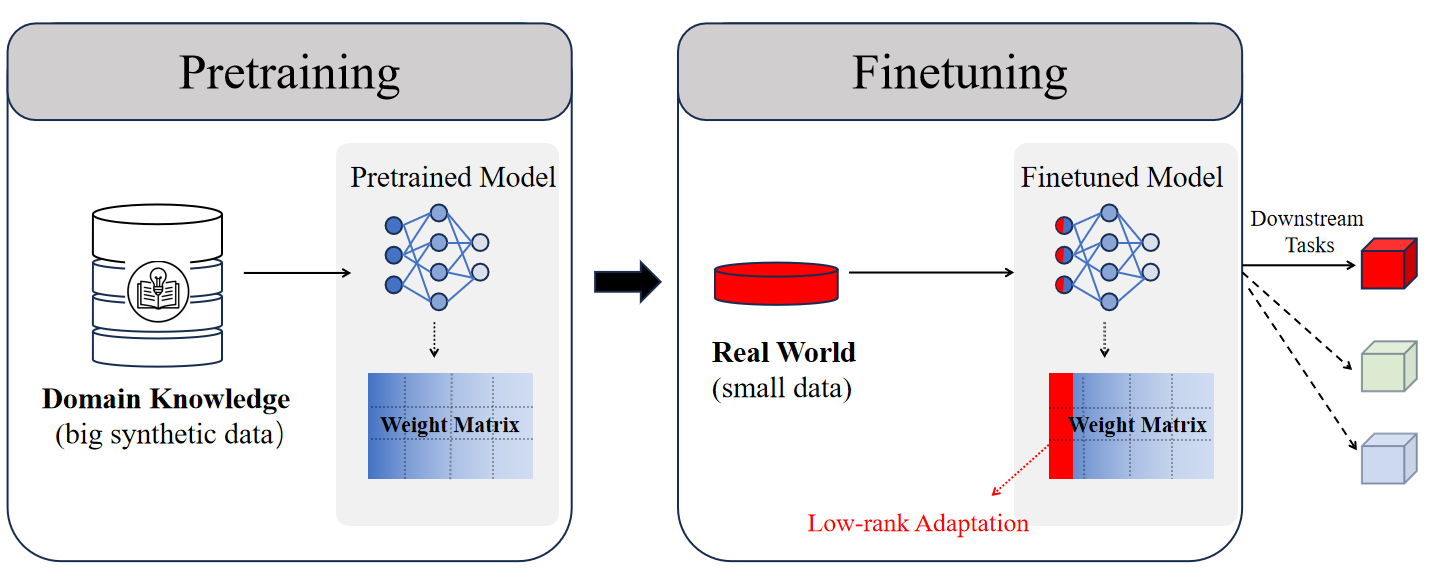
核心思路:借鉴大型语言模型的预训练-微调范式,利用大规模合成数据进行预训练,将领域知识注入模型,然后在真实数据上进行微调,使模型适应实际运营环境。这种方法能够有效利用领域知识和跨任务结构,提高决策效果。
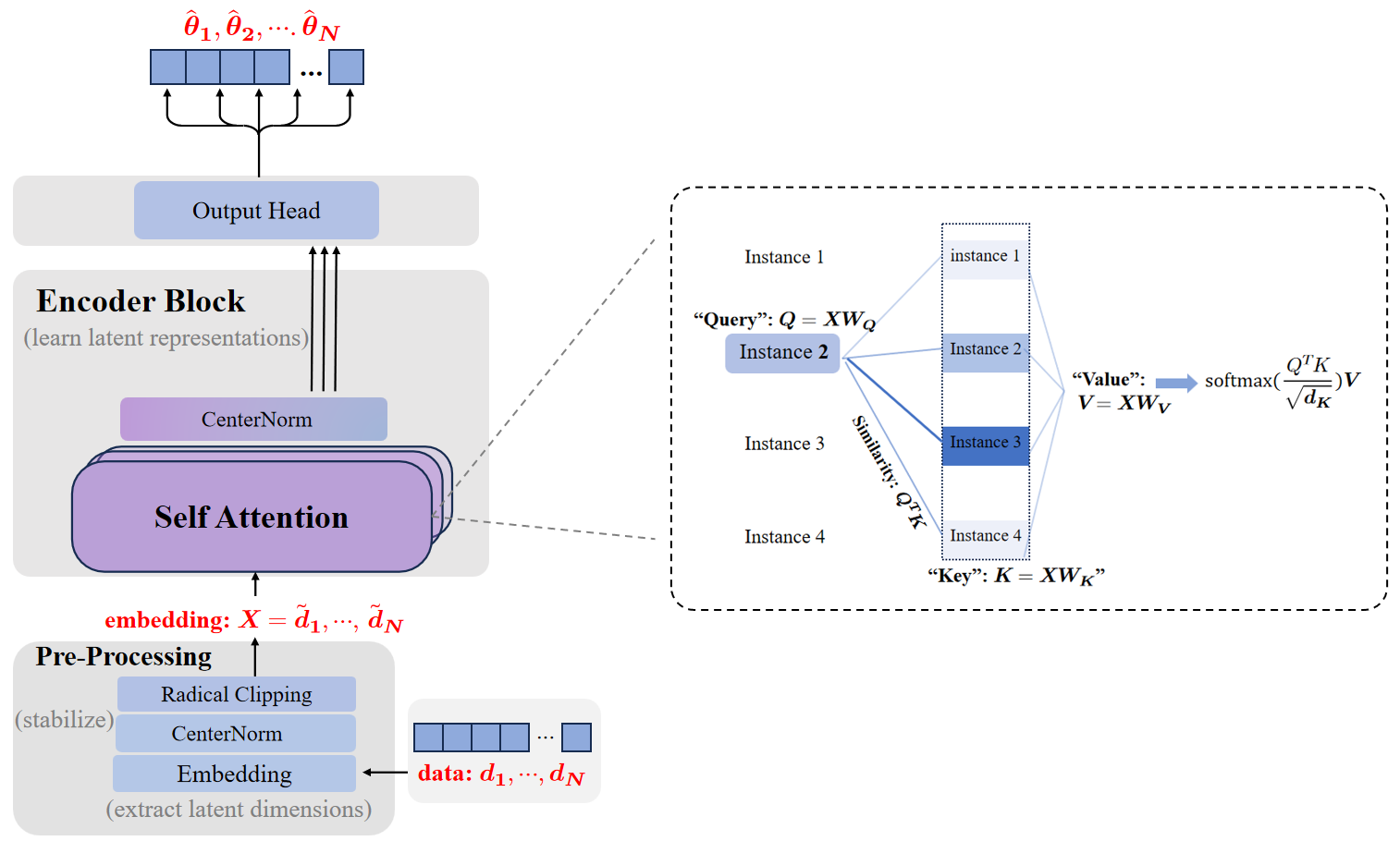
技术框架:整体框架包含两个阶段:预训练阶段和微调阶段。在预训练阶段,使用大规模合成数据训练Transformer模型,合成数据包含管理知识和决策环境的结构特征。在微调阶段,使用真实观测数据对预训练模型进行微调,使其适应实际运营环境。
关键创新:该方法的核心创新在于将LLM的预训练-微调范式应用于小数据、大规模决策问题,并针对该问题设计了特定的Transformer模型架构和训练流程。此外,论文还对Transformer在该问题上的学习进行了全面的误差分析,提供了理论保证。
关键设计:论文针对决策问题设计了特定的Transformer模型架构,并采用了定制的训练程序。具体的参数设置、损失函数和网络结构等技术细节在论文中进行了详细描述。此外,合成数据的生成方式也至关重要,需要包含丰富的领域知识和决策环境的结构特征。
🖼️ 关键图片
📊 实验亮点
论文提供了Transformer学习的非渐近误差分析,揭示了预训练和微调对性能的共同影响,并证明了微调的规模经济效应。实验结果(具体数值未知)表明,该方法在小数据、大规模决策问题上优于现有方法,验证了其有效性。
🎯 应用场景
该研究成果可应用于各种小数据、大规模决策场景,例如供应链管理、库存优化、定价策略等。通过预训练-微调方法,企业可以利用少量数据做出更优的运营决策,提高效率和盈利能力。该方法具有广泛的应用前景,有望推动企业智能化决策的发展。
📄 摘要(原文)
We consider small-data, large-scale decision problems in which a firm must make many operational decisions simultaneously (e.g., across a large product portfolio) while observing only a few, potentially noisy, data points per instance. Inspired by the success of large language models (LLMs), we propose a pretrain-then-finetune approach built on a designed Transformer model to address this challenge. The model is first pretrained on large-scale, domain-informed synthetic data that encode managerial knowledge and structural features of the decision environment, and is then fine-tuned on real observations. This new pipeline offers two complementary advantages: pretraining injects domain knowledge into the learning process and enables the training of high-capacity models using abundant synthetic data, while finetuning adapts the pretrained model to the operational environment and improves alignment with the true data-generating regime. While we have leveraged the Transformer's state-of-the-art representational capacity, particularly its attention mechanism, to efficiently extract cross-task structure, our approach is not an off-the-shelf application. Instead, it relies on problem-specific architectural design and a tailored training procedure to match the decision setting. Theoretically, we develop the first comprehensive error analysis regarding Transformer learning in relevant contexts, establishing nonasymptotic guarantees that validate the method's effectiveness. Critically, our analysis reveals how pretraining and fine-tuning jointly determine performance, with the dominant contribution governed by whichever is more favorable. In particular, finetuning exhibits an economies-of-scale effect, whereby transfer learning becomes increasingly effective as the number of instances grows.