Universal One-third Time Scaling in Learning Peaked Distributions
作者: Yizhou Liu, Ziming Liu, Cengiz Pehlevan, Jeff Gore
分类: cs.LG, cs.AI, stat.ML
发布日期: 2026-02-03
备注: 24 pages, 6 main text figures, 27 figures in total
💡 一句话要点
揭示Softmax交叉熵导致LLM训练损失幂律收敛,提出1/3普适时间缩放规律
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 损失函数 幂律收敛 Softmax 交叉熵 优化瓶颈 时间缩放
📋 核心要点
- 现有LLM训练损失收敛缓慢,计算成本高昂,其根本原因尚不明确,阻碍了模型效率提升。
- 论文发现Softmax和交叉熵损失函数在学习峰值分布时,会导致损失和梯度以幂律形式衰减,形成优化瓶颈。
- 理论分析和实验验证表明,损失随时间以1/3的幂律缩放,为神经缩放提供了解释,并为优化LLM训练提供了新思路。
📝 摘要(中文)
大型语言模型(LLM)的训练计算成本高昂,部分原因是损失呈现缓慢的幂律收敛,其根源尚不明确。通过对玩具模型的系统分析和对LLM的实证评估,我们表明这种行为可能本质上源于softmax和交叉熵的使用。当学习峰值概率分布(例如,下一个token分布)时,这些组件会产生幂律衰减的损失和梯度,从而造成根本性的优化瓶颈。这最终导致损失的幂律时间缩放,其普适指数为1/3。我们的结果为观察到的神经缩放提供了一种机制解释,并为提高LLM训练效率提出了新的方向。
🔬 方法详解
问题定义:论文旨在解决大型语言模型训练过程中损失函数收敛速度慢的问题。现有的训练方法计算成本高昂,且缺乏对损失函数收敛行为的深入理解,导致难以有效提升训练效率。特别是在学习下一个token分布这种峰值分布时,收敛问题尤为突出。
核心思路:论文的核心思路是揭示softmax和交叉熵损失函数在学习峰值概率分布时,会产生幂律衰减的损失和梯度,从而导致训练过程中的优化瓶颈。通过理论分析和实验验证,论文证明了损失函数随时间以1/3的幂律形式衰减,并认为这是导致LLM训练缓慢的根本原因之一。
技术框架:论文的技术框架主要包括以下几个部分:首先,通过构建简单的玩具模型,对softmax和交叉熵损失函数在学习峰值分布时的行为进行理论分析。然后,通过在实际的LLM上进行实验,验证理论分析的结论。具体来说,论文分析了损失函数、梯度以及其他相关指标随训练时间的变化趋势,并与理论预测进行了对比。
关键创新:论文最重要的技术创新点在于发现了softmax和交叉熵损失函数在学习峰值分布时会导致损失和梯度以幂律形式衰减,并提出了1/3的普适时间缩放规律。这一发现为理解LLM的训练行为提供了一种新的视角,并为优化LLM的训练过程提供了新的思路。与现有方法相比,论文的创新之处在于从损失函数的角度解释了LLM训练缓慢的原因,而不是仅仅关注模型结构或优化算法。
关键设计:论文的关键设计包括:使用softmax和交叉熵损失函数来模拟LLM的训练过程;构建简单的玩具模型来验证理论分析的结论;在实际的LLM上进行实验,验证理论分析的结论;分析损失函数、梯度以及其他相关指标随训练时间的变化趋势;将实验结果与理论预测进行对比。论文没有详细说明具体的参数设置或网络结构,而是侧重于理论分析和实验验证。
🖼️ 关键图片

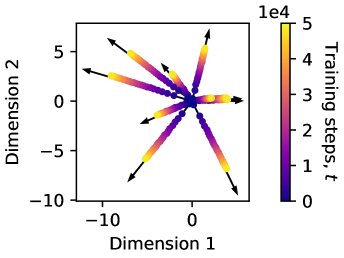
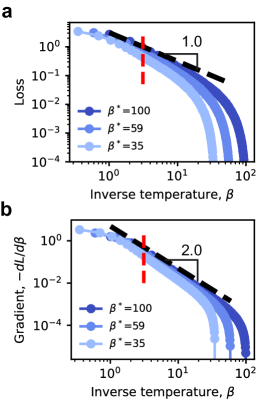
📊 实验亮点
论文通过理论分析和实验验证,证明了在使用softmax和交叉熵损失函数训练LLM时,损失函数会以1/3的幂律形式衰减。这一结论在玩具模型和实际LLM上都得到了验证,为理解LLM的训练行为提供了重要的理论支撑。该研究结果为优化LLM训练提供了新的方向。
🎯 应用场景
该研究成果可应用于提升大型语言模型的训练效率,降低计算成本。通过理解损失函数收敛的根本原因,可以设计更有效的优化算法和损失函数,加速模型训练,并推动更大规模模型的开发和应用。此外,该研究也为其他机器学习模型的训练提供了借鉴。
📄 摘要(原文)
Training large language models (LLMs) is computationally expensive, partly because the loss exhibits slow power-law convergence whose origin remains debatable. Through systematic analysis of toy models and empirical evaluation of LLMs, we show that this behavior can arise intrinsically from the use of softmax and cross-entropy. When learning peaked probability distributions, e.g., next-token distributions, these components yield power-law vanishing losses and gradients, creating a fundamental optimization bottleneck. This ultimately leads to power-law time scaling of the loss with a universal exponent of $1/3$. Our results provide a mechanistic explanation for observed neural scaling and suggest new directions for improving LLM training efficiency.