Reinforcement Fine-Tuning for History-Aware Dense Retriever in RAG
作者: Yicheng Zhang, Zhen Qin, Zhaomin Wu, Wenqi Zhang, Shuiguang Deng
分类: cs.LG
发布日期: 2026-02-03
备注: On going work. Codes are released at https://github.com/zyc140345/HARR
💡 一句话要点
提出基于强化学习的RAG历史感知稠密检索微调方法,提升多跳推理性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 强化学习 稠密检索 多跳推理 历史感知 马尔可夫决策过程 策略梯度
📋 核心要点
- 现有RAG方法中,检索器优化目标与RAG整体目标不一致,限制了性能。
- 论文提出基于强化学习的检索器优化方法,将RAG建模为马尔可夫决策过程,并引入随机抽样。
- 实验表明,该方法在多种RAG场景下均能提升性能,尤其是在多跳推理任务中。
📝 摘要(中文)
检索增强生成(RAG)使大型语言模型(LLM)能够生成基于证据的回复,其性能取决于检索器和LLM之间的匹配程度。检索器优化已成为微调LLM的一种有效替代方案。然而,现有的解决方案存在检索器优化目标与RAG流程目标不匹配的问题。强化学习(RL)为解决这一局限性提供了一种有希望的方案,但将RL应用于检索器优化带来了两个根本性的挑战:1)确定性检索与RL公式不兼容,以及2)在多跳推理中,仅查询检索会产生状态混叠。为了解决这些挑战,我们用随机抽样代替确定性检索,并将RAG公式化为一个马尔可夫决策过程,从而使检索器可以通过RL进行优化。此外,我们在每个检索步骤中将检索历史纳入状态,以减轻状态混叠。在不同的RAG流程、数据集和检索器规模上进行的大量实验表明,我们的方法在RAG性能方面取得了持续的改进。
🔬 方法详解
问题定义:论文旨在解决RAG系统中检索器优化的问题。现有方法通常直接优化检索器,使其检索到的文档与查询更相关,但忽略了RAG的最终目标是生成高质量的答案。这种目标不匹配导致检索器性能提升并不一定能转化为RAG整体性能的提升。此外,在多跳推理场景下,仅使用当前查询进行检索会导致状态混叠,即检索器无法区分不同的推理路径,从而影响检索效果。
核心思路:论文的核心思路是将RAG过程建模为一个马尔可夫决策过程(MDP),并使用强化学习(RL)来优化检索器。通过将RAG的最终目标(例如,生成答案的质量)作为RL的奖励信号,可以使检索器更好地适应RAG流程。同时,引入随机抽样来替代确定性检索,使得RL可以应用于检索器优化。为了解决状态混叠问题,论文将检索历史纳入状态表示中,使检索器能够感知之前的检索结果,从而更好地进行多跳推理。
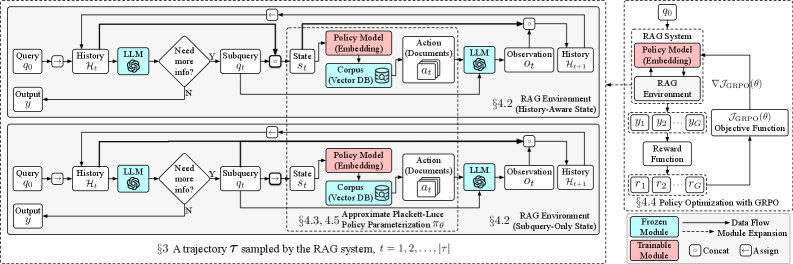
技术框架:整体框架包括以下几个主要模块:1) 环境:RAG系统,包括检索器和LLM。2) 智能体:检索器,负责根据当前状态选择检索动作。3) 状态:包括当前查询和检索历史。4) 动作:从文档库中选择文档进行检索。5) 奖励:基于LLM生成的答案质量进行评估,例如使用ROUGE或BLEU等指标。整个流程如下:智能体(检索器)根据当前状态(查询和检索历史)选择一个文档进行检索,然后LLM基于检索到的文档生成答案,最后根据答案质量计算奖励,并使用RL算法更新检索器的参数。
关键创新:论文的关键创新在于:1) 将RAG建模为MDP,并使用RL来优化检索器,从而解决了检索器优化目标与RAG流程目标不匹配的问题。2) 引入随机抽样来替代确定性检索,使得RL可以应用于检索器优化。3) 将检索历史纳入状态表示中,从而缓解了多跳推理中的状态混叠问题。
关键设计:论文的关键设计包括:1) 使用策略梯度算法(例如,REINFORCE或PPO)来训练检索器。2) 设计合适的奖励函数,以反映LLM生成的答案质量。3) 选择合适的检索历史表示方法,例如使用文档的嵌入向量或关键词。4) 调整随机抽样的概率分布,以平衡探索和利用。
🖼️ 关键图片
📊 实验亮点
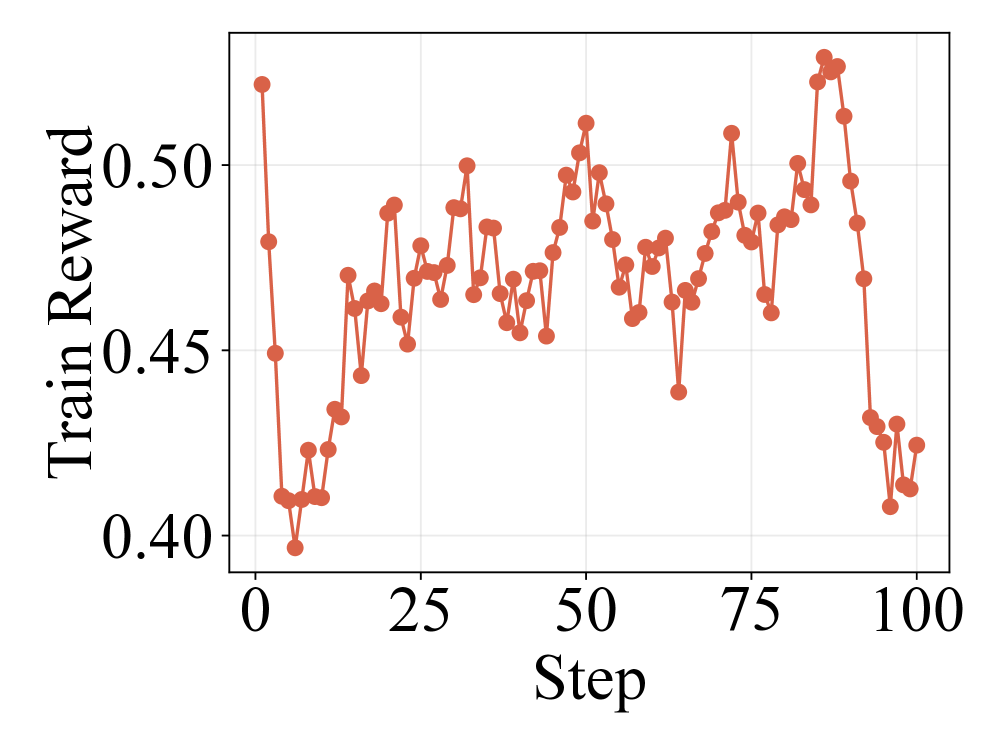
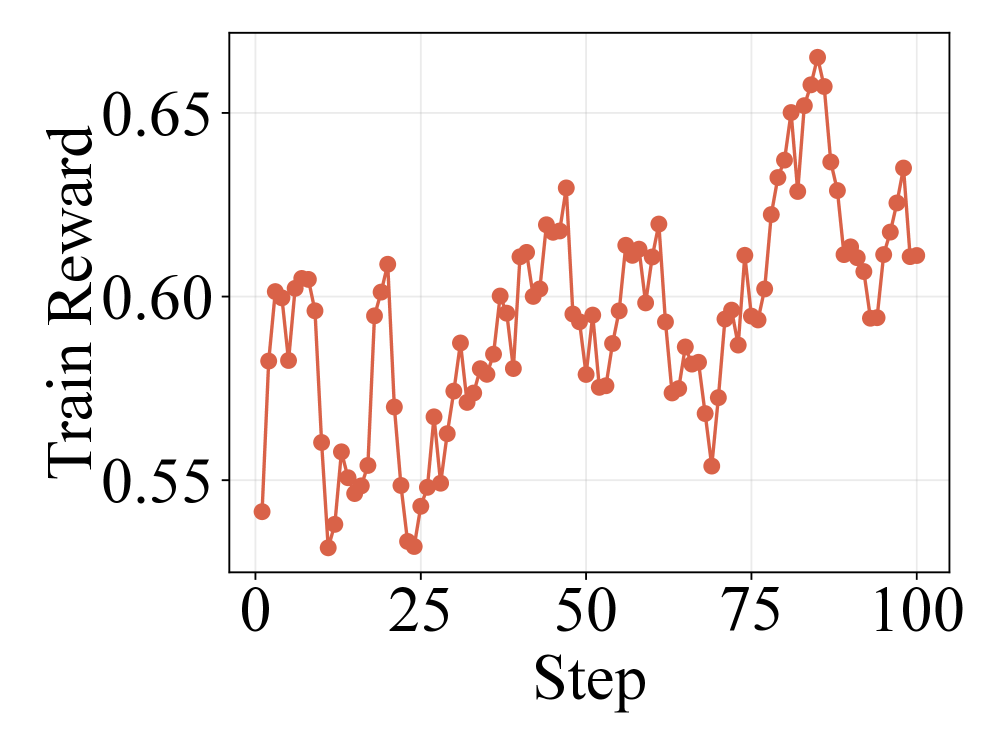
实验结果表明,该方法在多个数据集和RAG流程中均取得了显著的性能提升。例如,在多跳问答任务中,该方法相比于基线方法提升了约5-10%。此外,实验还验证了检索历史对于缓解状态混叠的重要性,以及随机抽样对于RL训练的有效性。
🎯 应用场景
该研究成果可应用于各种需要检索增强生成技术的场景,例如问答系统、对话系统、知识图谱推理等。通过优化检索器,可以提高RAG系统的准确性和可靠性,从而改善用户体验。未来,该方法可以进一步扩展到更复杂的RAG流程和更广泛的应用领域。
📄 摘要(原文)
Retrieval-augmented generation (RAG) enables large language models (LLMs) to produce evidence-based responses, and its performance hinges on the matching between the retriever and LLMs. Retriever optimization has emerged as an efficient alternative to fine-tuning LLMs. However, existing solutions suffer from objective mismatch between retriever optimization and the goal of RAG pipeline. Reinforcement learning (RL) provides a promising solution to address this limitation, yet applying RL to retriever optimization introduces two fundamental challenges: 1) the deterministic retrieval is incompatible with RL formulations, and 2) state aliasing arises from query-only retrieval in multi-hop reasoning. To address these challenges, we replace deterministic retrieval with stochastic sampling and formulate RAG as a Markov decision process, making retriever optimizable by RL. Further, we incorporate retrieval history into the state at each retrieval step to mitigate state aliasing. Extensive experiments across diverse RAG pipelines, datasets, and retriever scales demonstrate consistent improvements of our approach in RAG performance.