Robust Representation Learning in Masked Autoencoders
作者: Anika Shrivastava, Renu Rameshan, Samar Agnihotri
分类: cs.LG, cs.CV
发布日期: 2026-02-03
备注: 11 pages, 8 figures, and 3 tables
💡 一句话要点
研究表明掩码自编码器(MAE)学习的表征具有很强的鲁棒性,尤其是在图像分类任务中。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 掩码自编码器 表征学习 鲁棒性 图像分类 自监督学习
📋 核心要点
- 现有方法对MAE内部表征的理解不足,无法解释其强大的下游分类性能。
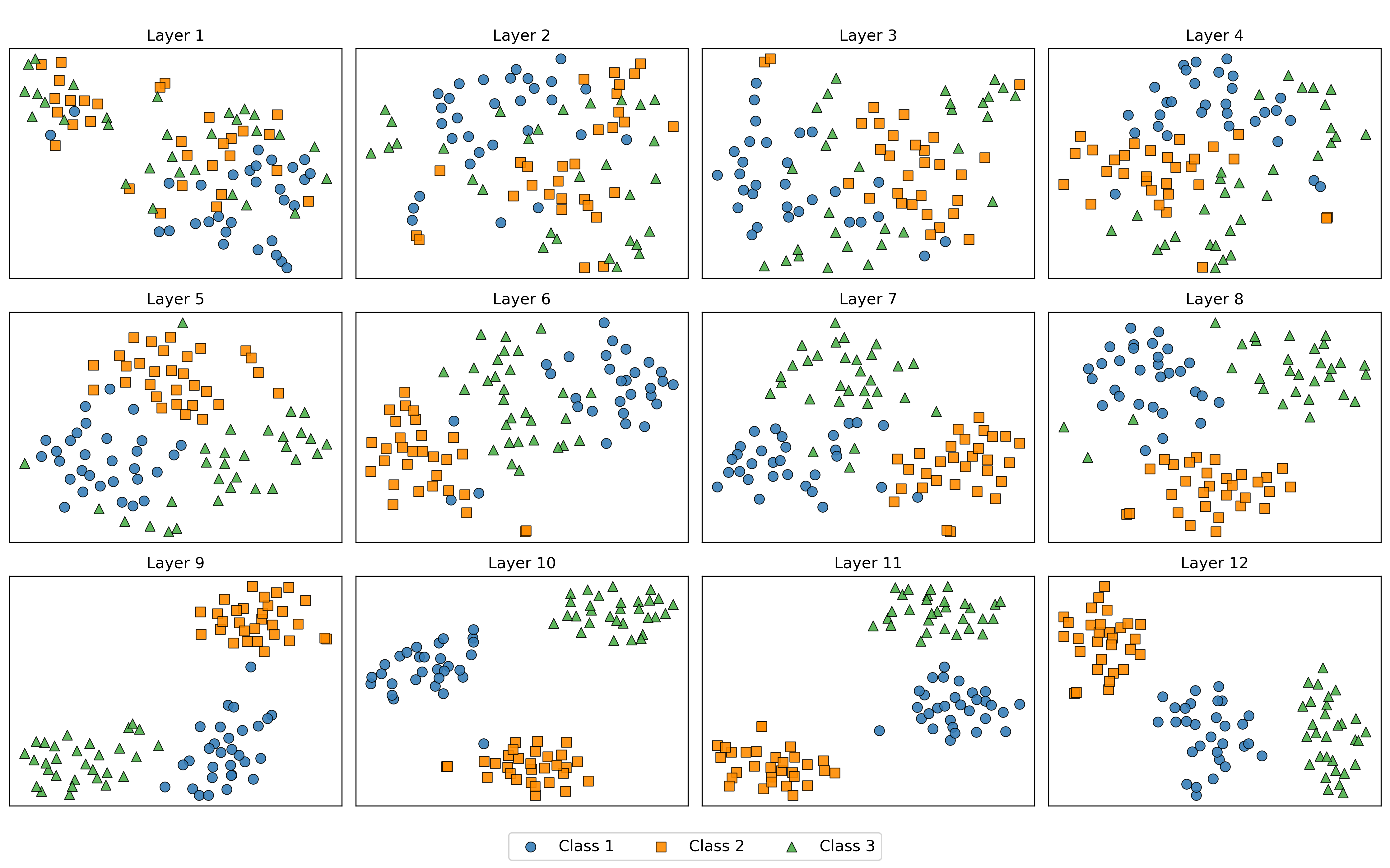
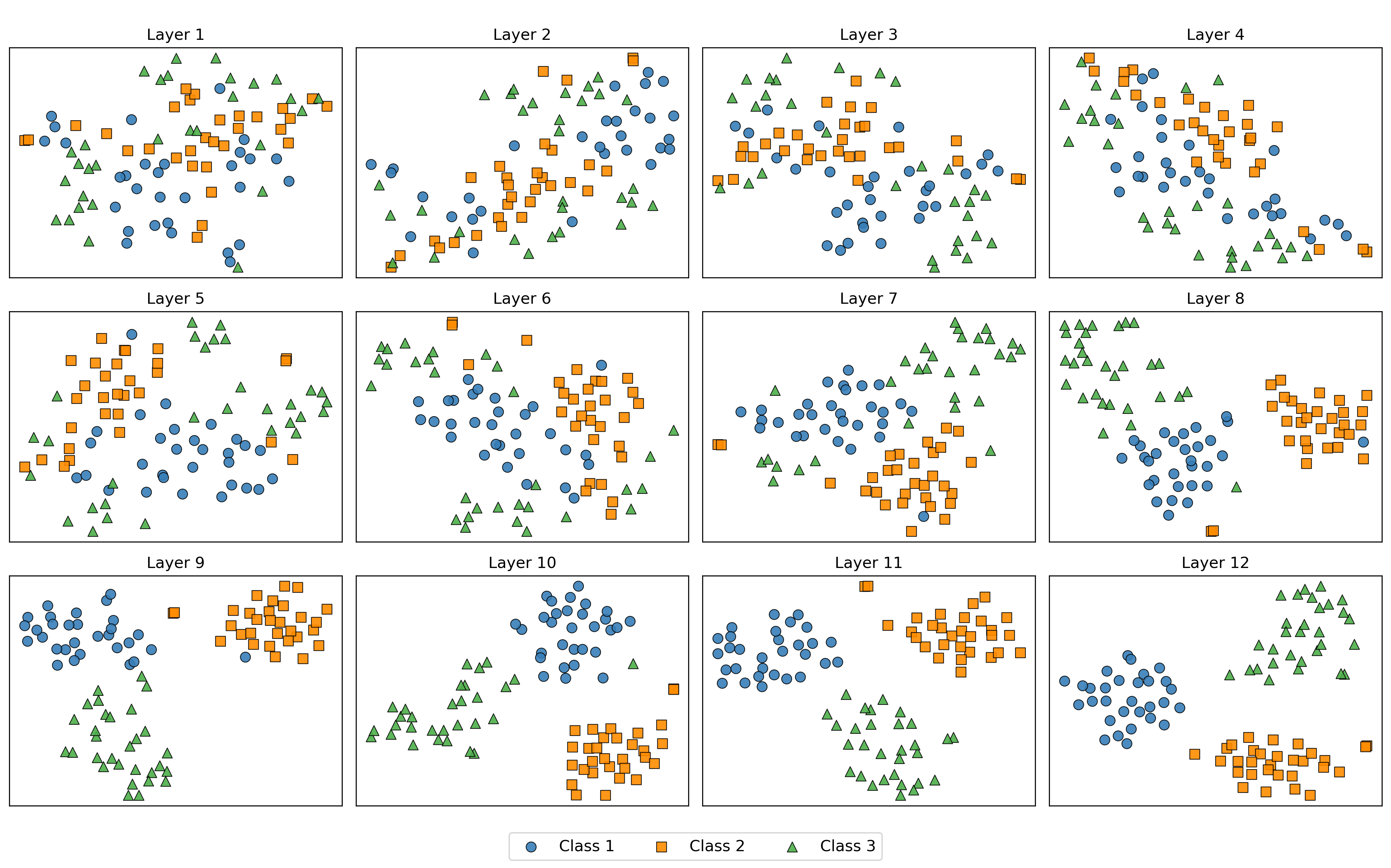
- 通过分析token嵌入和注意力机制,揭示MAE如何构建鲁棒的、类感知的潜在空间。
- 引入方向对齐和特征保留两个指标,量化MAE在图像退化情况下的特征鲁棒性。
📝 摘要(中文)
掩码自编码器(MAE)在图像分类任务中表现出色,但其学习到的内部表征仍不甚明了。本研究旨在理解MAE强大的下游分类性能。研究发现,经过预训练和微调后,MAE学习到的表征非常鲁棒,在存在模糊和遮挡等退化的情况下仍表现出良好的分类性能。通过对token嵌入的逐层分析,我们发现预训练的MAE在网络深度上以类感知的方式逐步构建其潜在空间:来自不同类别的嵌入位于逐渐可分离的子空间中。此外,我们观察到MAE在编码器层中表现出早期且持续的全局注意力,这与标准视觉Transformer(ViT)形成对比。为了量化特征鲁棒性,我们引入了两个敏感性指标:干净嵌入和扰动嵌入之间的方向对齐,以及在退化情况下头部对活跃特征的保留。这些研究有助于确立MAE的鲁棒分类性能。
🔬 方法详解
问题定义:论文旨在理解并解释掩码自编码器(MAE)在图像分类任务中表现出的强大性能,尤其关注其学习到的表征的鲁棒性。现有方法缺乏对MAE内部表征的深入理解,无法解释其在图像质量退化(如模糊、遮挡)情况下依然保持良好分类性能的原因。
核心思路:论文的核心思路是通过分析MAE的token嵌入和注意力机制,揭示其如何构建一个鲁棒且类感知的潜在空间。具体来说,研究关注不同类别的嵌入在网络深度上的可分离性,以及MAE在编码器层中表现出的全局注意力模式。通过量化特征在图像退化情况下的敏感性,进一步验证MAE表征的鲁棒性。
技术框架:论文的技术框架主要包括以下几个部分:1) 对预训练的MAE模型进行逐层分析,提取token嵌入和注意力权重;2) 使用方向对齐指标衡量干净嵌入和扰动嵌入之间的相似性;3) 使用特征保留指标衡量在图像退化情况下,哪些特征仍然保持活跃;4) 将MAE与标准视觉Transformer(ViT)进行对比,分析其注意力机制的差异。
关键创新:论文的关键创新在于:1) 揭示了MAE在网络深度上以类感知的方式逐步构建潜在空间,不同类别的嵌入逐渐可分离;2) 观察到MAE具有早期且持续的全局注意力,这与ViT不同;3) 提出了方向对齐和特征保留两个指标,用于量化特征的鲁棒性。
关键设计:论文的关键设计包括:1) 使用预训练的MAE模型,避免从头训练带来的不确定性;2) 采用逐层分析的方法,深入了解MAE内部表征的构建过程;3) 通过对比MAE和ViT,突出MAE的独特性;4) 使用多种图像退化方式(如模糊、遮挡)来评估特征的鲁棒性。
🖼️ 关键图片

📊 实验亮点
研究表明,预训练的MAE在图像退化情况下仍能保持良好的分类性能,其鲁棒性优于标准ViT。通过方向对齐和特征保留指标的量化分析,证实了MAE学习到的表征具有很强的抗干扰能力。实验结果表明,MAE在网络深度上逐步构建类感知的潜在空间,且具有早期和持续的全局注意力。
🎯 应用场景
该研究成果可应用于图像识别、目标检测等计算机视觉任务中,尤其是在图像质量较差或存在遮挡的情况下。通过理解和利用MAE的鲁棒表征,可以提升模型在实际应用中的泛化能力和可靠性。此外,该研究也为设计更鲁棒的自监督学习模型提供了新的思路。
📄 摘要(原文)
Masked Autoencoders (MAEs) achieve impressive performance in image classification tasks, yet the internal representations they learn remain less understood. This work started as an attempt to understand the strong downstream classification performance of MAE. In this process we discover that representations learned with the pretraining and fine-tuning, are quite robust - demonstrating a good classification performance in the presence of degradations, such as blur and occlusions. Through layer-wise analysis of token embeddings, we show that pretrained MAE progressively constructs its latent space in a class-aware manner across network depth: embeddings from different classes lie in subspaces that become increasingly separable. We further observe that MAE exhibits early and persistent global attention across encoder layers, in contrast to standard Vision Transformers (ViTs). To quantify feature robustness, we introduce two sensitivity indicators: directional alignment between clean and perturbed embeddings, and head-wise retention of active features under degradations. These studies help establish the robust classification performance of MAEs.