Not All Negative Samples Are Equal: LLMs Learn Better from Plausible Reasoning
作者: Zixiang Di, Jinyi Han, Shuo Zhang, Ying Liao, Zhi Li, Xiaofeng Ji, Yongqi Wang, Zheming Yang, Ming Gao, Bingdong Li, Jie Wang
分类: cs.LG, cs.AI
发布日期: 2026-02-03
💡 一句话要点
提出PNS方法,通过高质量负样本提升LLM的推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 负样本学习 强化学习 数学推理 偏好优化
📋 核心要点
- 现有方法在利用负样本提升LLM推理能力时,忽略了负样本质量的重要性,将所有错误答案视为同等信息量。
- PNS方法通过逆向强化学习,生成格式和结构与正确答案相似,但结果错误的“貌似合理”的负样本。
- 实验表明,PNS作为一种即插即用的数据源,在数学推理任务上显著优于其他负样本合成方法,平均提升2.03%。
📝 摘要(中文)
本文提出了一种名为Plausible Negative Samples (PNS) 的方法,旨在通过学习负样本来提升大型语言模型 (LLM) 的推理能力。与现有方法将所有错误答案视为同等信息量不同,PNS 合成高质量的负样本,这些样本在格式和结构上与正确答案相似,但最终结果是错误的。PNS 通过反向强化学习 (RL) 训练一个专用模型,该模型由一个复合奖励引导,该奖励结合了格式合规性、准确性反转、奖励模型评估和思维链评估,从而生成几乎与正确解决方案无法区分的响应。在七个数学推理基准测试中,PNS 作为一种即插即用的数据源,在三个骨干模型上进行了偏好优化验证。结果表明,PNS 始终优于其他负样本合成方法,与经过 RL 训练的模型相比,平均提高了 2.03%。
🔬 方法详解
问题定义:现有方法在利用负样本提升LLM推理能力时,存在一个关键的痛点:它们将所有不正确的答案都视为同等重要的负样本。这种做法忽略了负样本的质量差异,导致模型无法有效地从高质量的、具有迷惑性的错误答案中学习,从而限制了模型推理能力的提升。
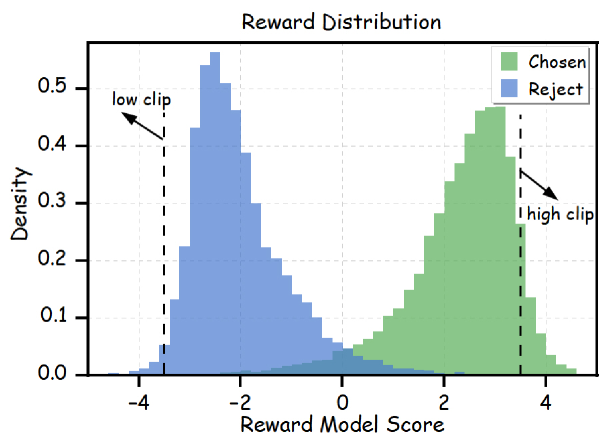
核心思路:PNS的核心思路是生成“貌似合理”的负样本,即这些负样本在格式、结构和推理过程上都与正确的答案非常相似,但最终的答案是错误的。通过让模型学习区分这些高质量的负样本和正确的答案,可以更有效地提升模型的推理能力。这种方法模拟了人类学习过程中从错误中学习的过程,即从那些看起来很合理但最终错误的答案中吸取教训。
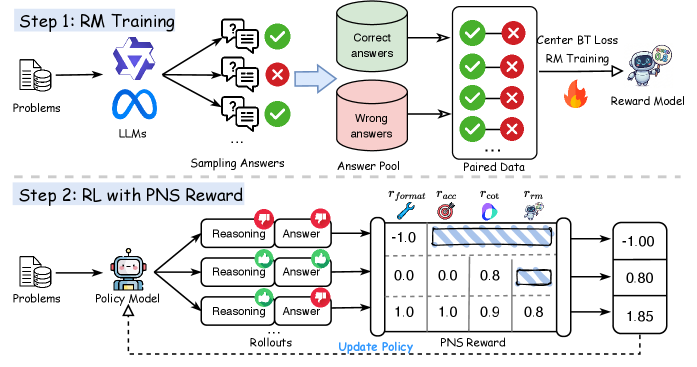
技术框架:PNS的技术框架主要包括以下几个步骤:首先,使用一个专门训练的模型来生成负样本。这个生成模型通过反向强化学习进行训练,其目标是生成既符合格式要求,又能够迷惑模型的错误答案。强化学习的奖励函数由多个部分组成,包括格式合规性奖励、准确性反转奖励、奖励模型评估奖励和思维链评估奖励。这些奖励共同引导生成模型生成高质量的负样本。然后,将生成的负样本作为训练数据,用于优化LLM的偏好。
关键创新:PNS最重要的技术创新点在于其生成高质量负样本的方法。与以往的负样本生成方法不同,PNS不仅仅关注答案的正确性,还关注答案的格式、结构和推理过程。通过反向强化学习和精心设计的奖励函数,PNS能够生成与正确答案非常相似,但最终错误的负样本,从而更有效地提升LLM的推理能力。
关键设计:PNS的关键设计包括:1) 使用反向强化学习来训练负样本生成模型;2) 设计一个复合奖励函数,该函数包括格式合规性奖励、准确性反转奖励、奖励模型评估奖励和思维链评估奖励;3) 将生成的负样本作为训练数据,用于优化LLM的偏好。奖励函数中的各个部分的权重需要仔细调整,以确保生成高质量的负样本。
🖼️ 关键图片

📊 实验亮点
实验结果表明,PNS方法在七个数学推理基准测试中,始终优于其他负样本合成方法。具体来说,与经过RL训练的模型相比,PNS方法平均提高了2.03%。这一结果表明,PNS方法能够有效地生成高质量的负样本,并利用这些负样本提升LLM的推理能力。此外,实验还验证了PNS方法作为一种即插即用的数据源的有效性,可以方便地应用于不同的LLM模型。
🎯 应用场景
PNS方法具有广泛的应用前景,可以应用于各种需要LLM进行推理的任务中,例如数学问题求解、代码生成、知识问答等。通过使用PNS方法生成的高质量负样本,可以显著提升LLM在这些任务上的性能。此外,PNS方法还可以用于评估LLM的鲁棒性,通过生成对抗性的负样本,可以发现LLM的潜在弱点,并进一步提升其安全性。
📄 摘要(原文)
Learning from negative samples holds great promise for improving Large Language Model (LLM) reasoning capability, yet existing methods treat all incorrect responses as equally informative, overlooking the crucial role of sample quality. To address this, we propose Plausible Negative Samples (PNS), a method that synthesizes high-quality negative samples exhibiting expected format and structural coherence while ultimately yielding incorrect answers. PNS trains a dedicated model via reverse reinforcement learning (RL) guided by a composite reward combining format compliance, accuracy inversion, reward model assessment, and chain-of-thought evaluation, generating responses nearly indistinguishable from correct solutions. We further validate PNS as a plug-and-play data source for preference optimization across three backbone models on seven mathematical reasoning benchmarks. Results demonstrate that PNS consistently outperforms other negative sample synthesis methods, achieving an average improvement of 2.03% over RL-trained models.