Reparameterization Flow Policy Optimization
作者: Hai Zhong, Zhuoran Li, Xun Wang, Longbo Huang
分类: cs.LG, cs.AI
发布日期: 2026-02-03
💡 一句话要点
提出RFO算法,结合流策略与重参数化梯度,提升模型强化学习的样本效率。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 重参数化梯度 流策略 模型学习 机器人控制
📋 核心要点
- 现有重参数化策略梯度方法主要依赖高斯策略,限制了性能,未能充分利用生成模型。
- 论文提出RFO算法,结合流策略与重参数化梯度,通过可微分ODE积分生成动作,提升样本效率。
- 实验表明,RFO在多种运动和操作任务中表现出色,尤其在软体四足动物控制任务中提升显著。
📝 摘要(中文)
重参数化策略梯度(RPG)已成为基于模型的强化学习的强大范例,通过可微分动力学反向传播梯度来实现高样本效率。然而,先前的RPG方法主要局限于高斯策略,限制了它们的性能,并且未能利用生成模型的最新进展。本文发现,通过可微分ODE积分生成动作的流策略,与RPG框架自然对齐,这是先前工作中未建立的联系。然而,简单地利用这种协同作用是无效的,常常遭受训练不稳定和缺乏探索的问题。我们提出了重参数化流策略优化(RFO)。RFO通过联合反向传播流生成过程和系统动力学来计算策略梯度,从而解锁高样本效率,而无需难以处理的对数似然计算。RFO包括两个为稳定性和探索量身定制的正则化项。我们还提出了一个带有动作分块的RFO变体。在涉及刚性和软体的各种运动和操作任务(具有状态或视觉输入)上的大量实验证明了RFO的有效性。值得注意的是,在一个控制软体四足动物的具有挑战性的运动任务中,RFO实现了几乎是现有最佳基线的2倍的奖励。
🔬 方法详解
问题定义:现有的重参数化策略梯度方法(RPG)主要局限于高斯策略,这限制了其在复杂环境中的表现。此外,这些方法未能充分利用近年来生成模型领域的进展,例如流模型。因此,如何将更强大的策略表示(如流策略)融入RPG框架,并克服训练不稳定和探索不足的问题,是本文要解决的核心问题。
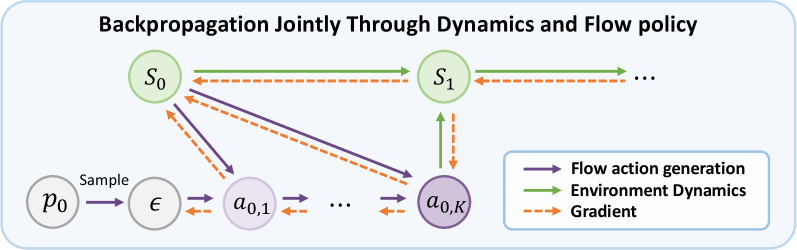
核心思路:论文的核心思路是将流策略与重参数化策略梯度相结合。流策略通过可微分的常微分方程(ODE)积分生成动作,天然地与RPG框架兼容。通过联合反向传播流生成过程和系统动力学,可以有效地计算策略梯度,从而实现高样本效率。此外,论文还引入了正则化项来解决训练不稳定和探索不足的问题。
技术框架:RFO算法的整体框架包括以下几个主要模块:1) 流策略网络:使用神经网络参数化一个ODE,通过积分该ODE生成动作。2) 动力学模型:用于预测给定状态和动作下的下一个状态。3) 奖励函数:用于评估策略的性能。4) 梯度计算:通过反向传播流策略网络和动力学模型,计算策略梯度。5) 策略更新:使用计算得到的梯度更新策略网络参数。
关键创新:论文的关键创新在于将流策略与重参数化策略梯度相结合,并提出了相应的优化算法RFO。与传统的基于高斯策略的RPG方法相比,RFO能够利用更强大的策略表示能力,从而在复杂环境中取得更好的性能。此外,RFO还引入了两个定制的正则化项,分别用于稳定训练和促进探索。
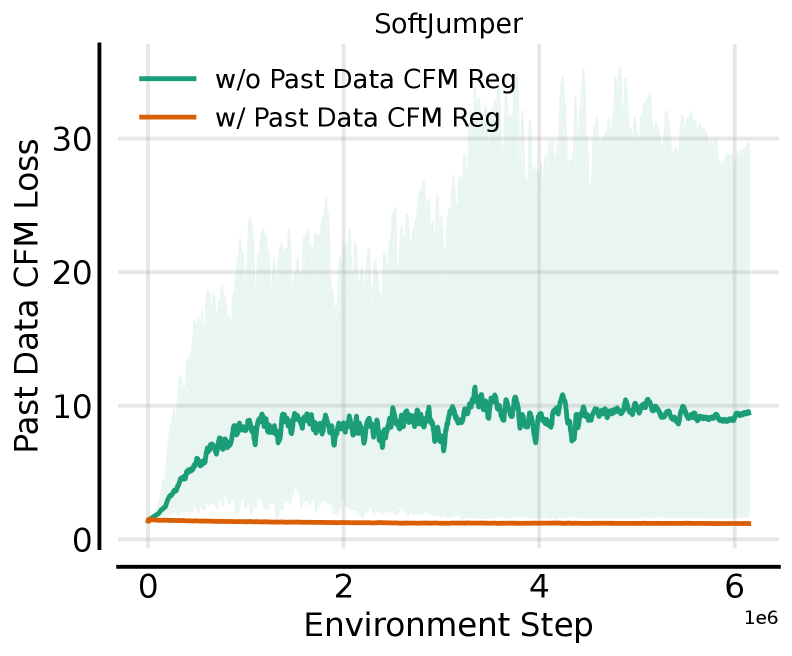
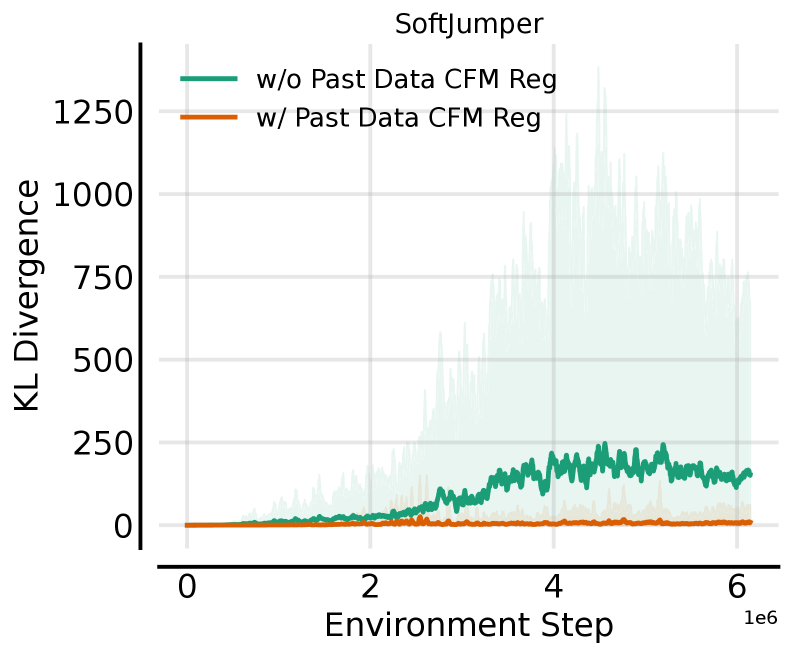
关键设计:RFO的关键设计包括:1) 使用神经网络参数化ODE,从而实现灵活的策略表示。2) 引入两个正则化项:一个用于约束流的Jacobian矩阵的奇异值,从而稳定训练;另一个用于鼓励策略探索。3) 提出了一种动作分块的变体,可以进一步提高样本效率。损失函数包括奖励函数、两个正则化项以及可选的动作分块损失。
🖼️ 关键图片
📊 实验亮点
在软体四足动物运动控制任务中,RFO算法的性能显著优于现有最佳基线,实现了接近2倍的奖励提升。此外,在其他运动和操作任务中,RFO也表现出良好的性能和样本效率,证明了其在复杂环境下的有效性。
🎯 应用场景
该研究成果可应用于机器人控制、游戏AI、自动驾驶等领域。通过结合流策略和重参数化梯度,可以训练出更高效、更鲁棒的智能体,从而解决复杂环境下的控制问题。例如,可以用于训练软体机器人的运动控制策略,或者用于训练自动驾驶汽车在复杂交通环境下的决策策略。
📄 摘要(原文)
Reparameterization Policy Gradient (RPG) has emerged as a powerful paradigm for model-based reinforcement learning, enabling high sample efficiency by backpropagating gradients through differentiable dynamics. However, prior RPG approaches have been predominantly restricted to Gaussian policies, limiting their performance and failing to leverage recent advances in generative models. In this work, we identify that flow policies, which generate actions via differentiable ODE integration, naturally align with the RPG framework, a connection not established in prior work. However, naively exploiting this synergy proves ineffective, often suffering from training instability and a lack of exploration. We propose Reparameterization Flow Policy Optimization (RFO). RFO computes policy gradients by backpropagating jointly through the flow generation process and system dynamics, unlocking high sample efficiency without requiring intractable log-likelihood calculations. RFO includes two tailored regularization terms for stability and exploration. We also propose a variant of RFO with action chunking. Extensive experiments on diverse locomotion and manipulation tasks, involving both rigid and soft bodies with state or visual inputs, demonstrate the effectiveness of RFO. Notably, on a challenging locomotion task controlling a soft-body quadruped, RFO achieves almost $2\times$ the reward of the state-of-the-art baseline.