Lookahead Path Likelihood Optimization for Diffusion LLMs
作者: Xuejie Liu, Yap Vit Chun, Yitao Liang, Anji Liu
分类: cs.LG
发布日期: 2026-02-03
💡 一句话要点
提出POKE-SMC,通过Path LL优化扩散LLM的逆掩码路径选择,提升推理精度。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 扩散模型 大语言模型 逆掩码顺序 路径对数似然 序列蒙特卡罗 推理优化 价值估计
📋 核心要点
- 扩散LLM的推理性能受逆掩码顺序影响,现有方法仅优化局部置信度,缺乏全局一致性。
- 提出Path LL作为轨迹条件目标,与下游精度相关,并设计POKE预测未来Path LL。
- 构建POKE-SMC搜索框架,动态识别最佳逆掩码路径,实验表明精度提升显著。
📝 摘要(中文)
扩散大语言模型(dLLMs)支持任意顺序的生成,但其推理性能严重依赖于逆掩码顺序。现有策略依赖于贪婪地优化局部置信度的启发式方法,对于识别全局一致和准确的逆掩码路径提供的指导有限。为了弥补这一差距,我们引入了路径对数似然(Path LL),这是一个轨迹条件目标,与下游精度密切相关,并能够有原则地选择逆掩码路径。为了在推理时优化Path LL,我们提出了一种有效的价值估计器POKE,它可以预测部分解码轨迹的预期未来Path LL。然后,我们将这种前瞻信号集成到POKE-SMC中,这是一个基于序列蒙特卡罗的搜索框架,用于动态识别最佳逆掩码路径。在6个推理任务上的大量实验表明,POKE-SMC持续提高精度,在LLaDA模型上以相当的推理开销实现了比强解码时缩放基线平均2%-3%的增益,并提高了精度-计算Pareto前沿。
🔬 方法详解
问题定义:扩散语言模型(dLLMs)的推理过程依赖于逆掩码顺序,即决定哪些token被逐步揭示。现有方法通常采用贪婪策略,基于局部置信度选择下一个要揭示的token,但这种局部优化往往无法保证全局一致性和最终的生成质量。因此,如何找到最优的逆掩码路径,最大化生成文本的准确性,是当前面临的关键问题。现有方法的痛点在于缺乏对未来token选择的全局视角,容易陷入局部最优。
核心思路:论文的核心思路是引入“路径对数似然”(Path LL)的概念,将其作为衡量逆掩码路径优劣的指标。Path LL代表了给定逆掩码路径下,生成目标文本的概率。通过优化Path LL,可以选择更可能生成正确文本的路径。为了高效地估计和优化Path LL,论文提出了POKE(Path log-likelihood Optimization with lookahead Estimation),利用前瞻估计来预测未来路径的潜在收益,从而指导逆掩码路径的选择。这样设计的目的是为了克服贪婪策略的局限性,实现全局优化。
技术框架:POKE-SMC的整体框架基于序列蒙特卡罗(SMC)方法。SMC维护一组候选的逆掩码路径,并在每一步迭代中,根据POKE估计的Path LL对这些路径进行加权和重采样。具体流程如下: 1. 初始化:随机生成一组初始逆掩码路径。 2. 前瞻估计:使用POKE估计每条路径在未来步骤中可能获得的Path LL。 3. 加权:根据POKE估计的Path LL,对每条路径进行加权。 4. 重采样:根据权重,对路径进行重采样,选择更有希望的路径进行下一步扩展。 5. 扩展:对选定的路径进行扩展,生成新的候选路径。 6. 迭代:重复步骤2-5,直到生成完整的文本序列。
关键创新:论文最重要的技术创新点在于Path LL的引入和POKE价值估计器的设计。Path LL提供了一个全局优化的目标,而POKE则提供了一种高效估计未来Path LL的方法。与现有方法相比,POKE-SMC不再局限于局部置信度的优化,而是能够基于对未来收益的预测,做出更明智的逆掩码路径选择。POKE通过学习一个价值函数,预测给定部分解码轨迹的预期未来Path LL,从而指导搜索过程。
关键设计:POKE的关键设计在于其价值函数的学习。论文采用了一种基于Transformer的架构来构建POKE,输入是部分解码的文本序列和当前的逆掩码路径,输出是未来Path LL的估计值。POKE的训练目标是最小化预测Path LL与真实Path LL之间的差距。此外,POKE-SMC还采用了多种优化策略,例如动态调整搜索宽度、使用剪枝技术等,以提高搜索效率。
🖼️ 关键图片
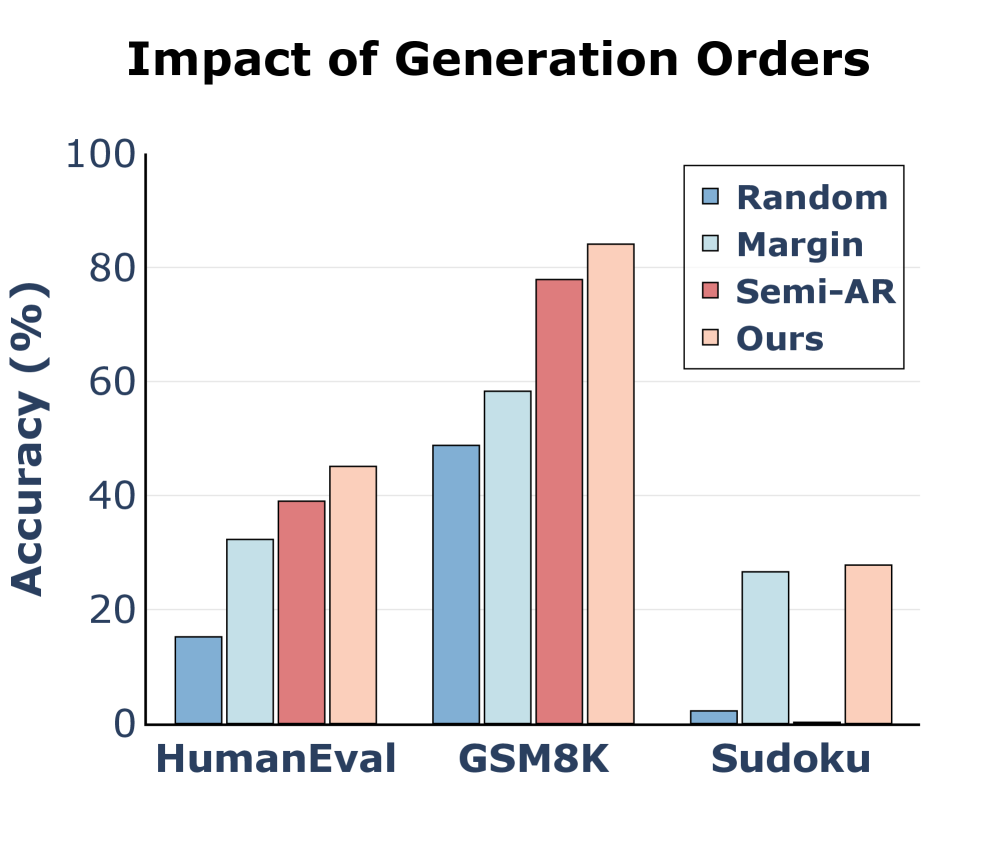
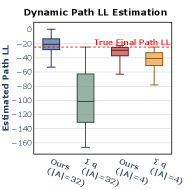

📊 实验亮点
实验结果表明,POKE-SMC在6个推理任务上 consistently 提高了精度,相比于强大的解码时缩放基线,平均提升了2%-3%。在LLaDA模型上,POKE-SMC在相似的推理开销下,显著提高了精度,并推进了精度-计算Pareto前沿。这些结果表明,POKE-SMC是一种有效的逆掩码路径优化方法,能够显著提高扩散LLM的生成质量。
🎯 应用场景
该研究成果可应用于各种需要高质量文本生成的场景,例如机器翻译、文本摘要、对话系统和代码生成等。通过优化逆掩码路径,可以显著提高生成文本的准确性和流畅性,从而提升用户体验。此外,该方法还可以应用于其他类型的生成模型,例如图像生成和音频生成,具有广泛的应用前景。
📄 摘要(原文)
Diffusion Large Language Models (dLLMs) support arbitrary-order generation, yet their inference performance critically depends on the unmasking order. Existing strategies rely on heuristics that greedily optimize local confidence, offering limited guidance for identifying unmasking paths that are globally consistent and accurate. To bridge this gap, we introduce path log-likelihood (Path LL), a trajectory-conditioned objective that strongly correlates with downstream accuracy and enables principled selection of unmasking paths. To optimize Path LL at inference time, we propose POKE, an efficient value estimator that predicts the expected future Path LL of a partial decoding trajectory. We then integrate this lookahead signal into POKE-SMC, a Sequential Monte Carlo-based search framework for dynamically identifying optimal unmasking paths. Extensive experiments across 6 reasoning tasks show that POKE-SMC consistently improves accuracy, achieving 2%--3% average gains over strong decoding-time scaling baselines at comparable inference overhead on LLaDA models and advancing the accuracy--compute Pareto frontier.