Beyond Variance: Prompt-Efficient RLVR via Rare-Event Amplification and Bidirectional Pairing
作者: Xin Sheng, Jiaxin Li, Yujuan Pang, Ran Peng, Yong Ma
分类: cs.LG, cs.AI
发布日期: 2026-02-03
💡 一句话要点
提出基于罕见事件增强和双向配对的Prompt高效RLVR方法,提升大语言模型在确定性推理任务上的性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 可验证奖励 Prompt工程 大语言模型 数学推理
📋 核心要点
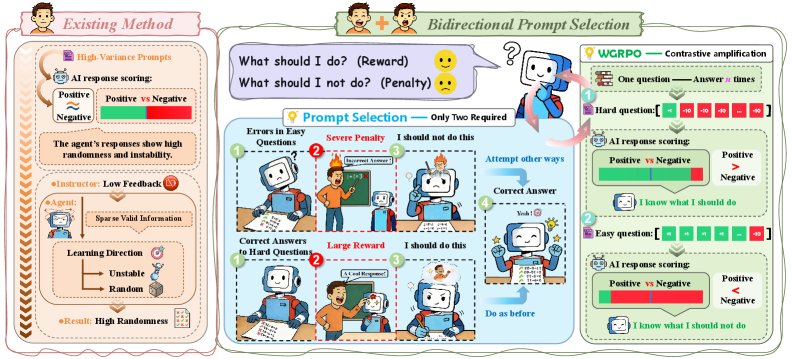
- 现有RLVR方法Prompt选择仅依赖训练准确率方差,导致优化不稳定和泛化能力弱。
- 提出正负配对策略,选择困难但可解的Prompt和容易但脆弱的Prompt,提供双向学习信号。
- 实验表明,该方法在数学推理任务上显著优于基线方法,且与大规模RLVR方法具有竞争力。
📝 摘要(中文)
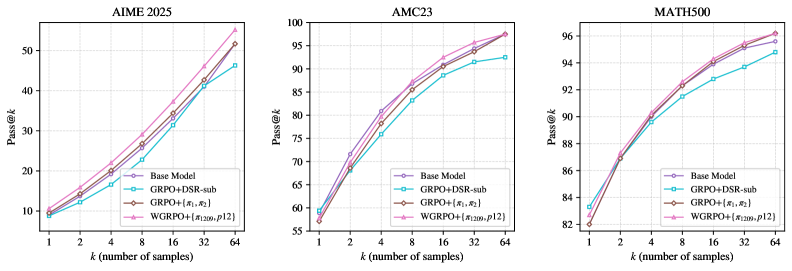
本文提出了一种Prompt高效的、基于可验证奖励的强化学习(RLVR)方法,用于训练大型语言模型在确定性结果推理任务上的能力。现有RLVR方法虽然可以使用少量Prompt,但Prompt选择通常仅基于训练准确率的方差,导致优化方向不稳定和泛化能力较弱。本文从机制层面重新审视Prompt选择,认为有效的minibatch应提供(i)可靠的正向锚点和(ii)来自罕见失败的显式负向学习信号。基于此,本文提出了正负配对:每次更新时,采样一个困难但可解的Prompt $q^{+}$和一个容易但脆弱的Prompt $q^{-}$(成功率高但非完美),分别对应于多次rollout下的低经验成功率和高经验成功率。此外,本文引入了Weighted GRPO,它在pair级别重新加权二元结果,并使用组归一化优势函数来将$q^{+}$上的罕见成功放大为清晰的正向指导,同时将$q^{-}$上的罕见失败转化为强烈的负向惩罚。这种双向信号为成功和失败都提供了信息丰富的学习反馈,提高了样本效率,且不抑制探索。在Qwen2.5-Math-7B上,每次更新使用单个配对minibatch始终优于通过常用方差选择启发式方法选择两个Prompt的GRPO基线:AIME 2025 Pass@8从16.8提高到22.2,AMC23 Pass@64从94.0提高到97.0,同时与从1209个训练Prompt池中训练的大规模RLVR保持竞争力。在Qwen2.5-Math-7B-Instruct上也观察到类似的增益。
🔬 方法详解
问题定义:论文旨在解决RLVR中Prompt选择不当导致的训练不稳定和泛化能力弱的问题。现有方法主要依赖于训练准确率的方差来选择Prompt,但这种方法忽略了Prompt的内在特性,容易导致优化方向不稳定,并且难以捕捉到罕见但重要的失败案例。
核心思路:论文的核心思路是构建一个包含正负样本的Prompt对,其中正样本是困难但可解的Prompt,负样本是容易但脆弱的Prompt。通过这种方式,可以同时利用成功和失败的信息,提供更丰富和稳定的学习信号。正样本的罕见成功可以被放大,提供清晰的正向指导;负样本的罕见失败可以转化为强烈的负向惩罚。
技术框架:整体框架包括以下几个主要步骤:1) Prompt采样:根据经验成功率选择困难但可解的Prompt ($q^{+}$) 和容易但脆弱的Prompt ($q^{-}$)。2) 数据收集:对每个Prompt进行多次rollout,收集二元结果(成功或失败)。3) 奖励加权:使用Weighted GRPO方法,在pair级别重新加权二元结果,并使用组归一化优势函数。4) 模型更新:利用加权后的奖励信号更新语言模型。
关键创新:论文的关键创新在于提出了正负配对的Prompt选择策略和Weighted GRPO方法。正负配对策略能够提供更全面和稳定的学习信号,而Weighted GRPO方法能够有效地放大罕见事件的影响,提高样本效率。与现有方法相比,该方法更加关注Prompt的内在特性,能够更好地指导模型的学习。
关键设计:关键设计包括:1) Prompt选择标准:选择低经验成功率的Prompt作为$q^{+}$,选择高经验成功率但非完美的Prompt作为$q^{-}$。2) Weighted GRPO:使用组归一化优势函数来放大罕见事件的影响。具体来说,对$q^{+}$上的成功赋予更高的权重,对$q^{-}$上的失败赋予更高的权重。3) 损失函数:使用标准的策略梯度损失函数,但使用加权后的奖励信号。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在Qwen2.5-Math-7B上,使用单个配对minibatch的该方法始终优于通过常用方差选择启发式方法选择两个Prompt的GRPO基线:AIME 2025 Pass@8从16.8提高到22.2,AMC23 Pass@64从94.0提高到97.0,同时与从1209个训练Prompt池中训练的大规模RLVR保持竞争力。在Qwen2.5-Math-7B-Instruct上也观察到类似的增益。
🎯 应用场景
该研究成果可应用于各种需要确定性推理的大语言模型训练场景,例如数学问题求解、代码生成、逻辑推理等。通过提高Prompt选择的效率和稳定性,可以降低训练成本,提升模型性能,并促进大语言模型在实际应用中的部署。
📄 摘要(原文)
Reinforcement learning with verifiable rewards (RLVR) is effective for training large language models on deterministic outcome reasoning tasks. Prior work shows RLVR works with few prompts, but prompt selection is often based only on training-accuracy variance, leading to unstable optimization directions and weaker transfer. We revisit prompt selection from a mechanism-level view and argue that an effective minibatch should provide both (i) a reliable positive anchor and (ii) explicit negative learning signals from rare failures. Based on this principle, we propose \emph{positive--negative pairing}: at each update, we sample a hard-but-solvable $q^{+}$ and an easy-but-brittle prompt $q^{-}$(high success rate but not perfect), characterized by low and high empirical success rates under multiple rollouts. We further introduce Weighted GRPO, which reweights binary outcomes at the pair level and uses group-normalized advantages to amplify rare successes on $q^{+}$ into sharp positive guidance while turning rare failures on $q^{-}$ into strong negative penalties. This bidirectional signal provides informative learning feedback for both successes and failures, improving sample efficiency without suppressing exploration. On Qwen2.5-Math-7B, a single paired minibatch per update consistently outperforms a GRPO baseline that selects two prompts via commonly used variance-based selection heuristics: AIME~2025 Pass@8 improves from 16.8 to 22.2, and AMC23 Pass@64 from 94.0 to 97.0, while remaining competitive with large-scale RLVR trained from a pool of 1209 training prompts. Similar gains are observed on Qwen2.5-Math-7B-Instruct.