CoCoEmo: Composable and Controllable Human-Like Emotional TTS via Activation Steering
作者: Siyi Wang, Shihong Tan, Siyi Liu, Hong Jia, Gongping Huang, James Bailey, Ting Dang
分类: cs.SD, cs.LG
发布日期: 2026-02-03
💡 一句话要点
提出CoCoEmo,通过激活调控实现可组合、可控的类人情感TTS
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱四:生成式动作 (Generative Motion) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 情感TTS 激活调控 混合情感合成 文本情感不匹配 语音合成 可控语音生成 情感韵律 混合TTS架构
📋 核心要点
- 现有情感TTS系统难以处理混合情感和文本情感不匹配的情况,限制了情感表达的丰富性。
- 提出CoCoEmo框架,通过激活调控实现情感的可组合性和可控性,从而合成更自然的情感语音。
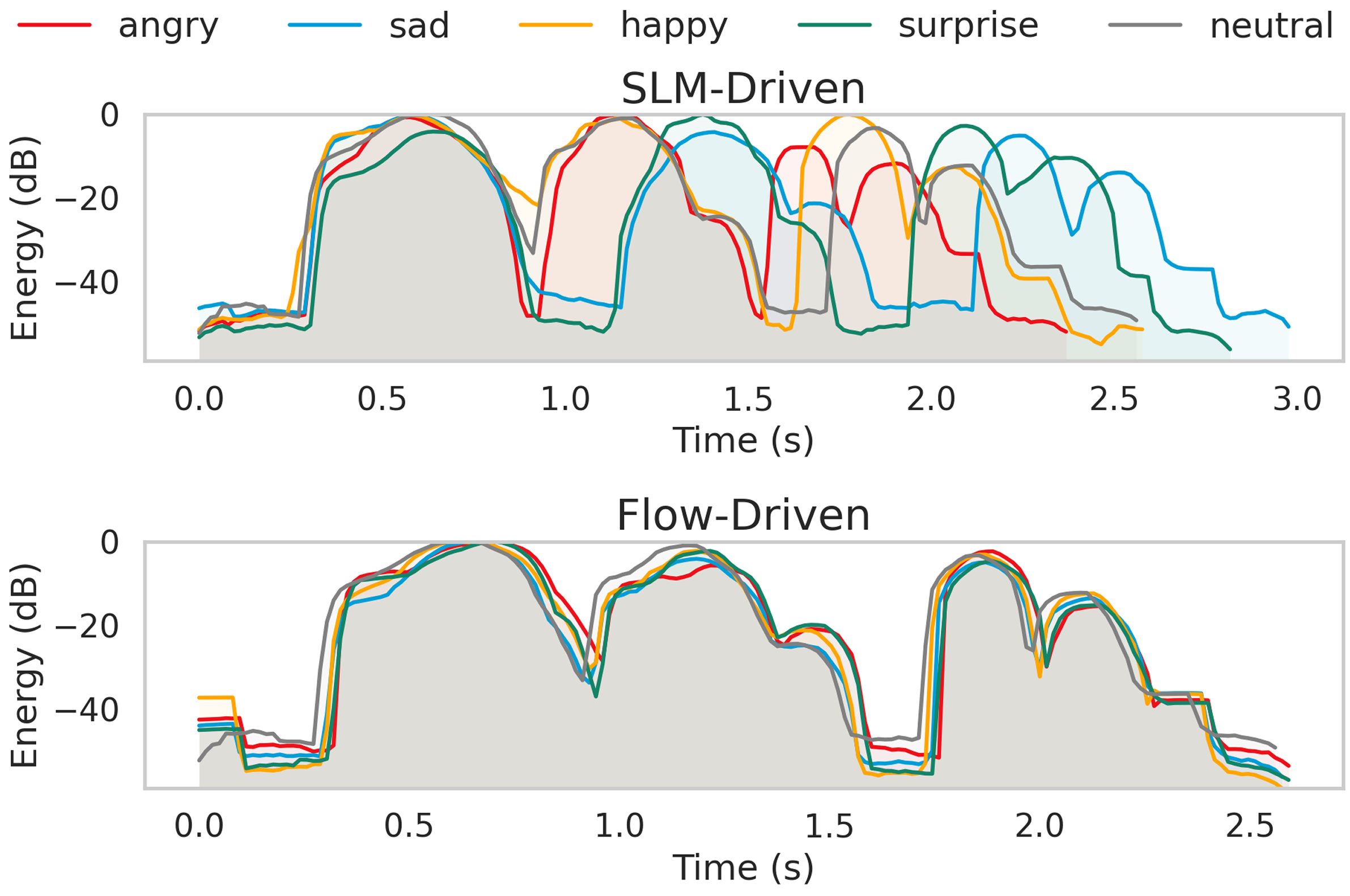
- 实验表明,情感韵律主要由TTS语言模块合成,并验证了CoCoEmo在混合情感和不匹配情感合成方面的有效性。
📝 摘要(中文)
人类语音中的情感表达是细致且可组合的,通常涉及多种有时相互冲突的情感线索,这些线索可能与语言内容不一致。相比之下,大多数情感文本到语音系统 (TTS) 强制执行单一的语句级别情感,从而抑制了情感多样性以及混合或与文本情感不匹配的表达。虽然通过潜在方向向量进行激活调控提供了一个有希望的解决方案,但情感表示在TTS中是否可以线性调控,调控应该在混合TTS架构中如何应用,以及如何评估这种复杂的情感行为仍然不清楚。本文首次对混合TTS模型中的情感控制激活调控进行了系统分析,引入了一个定量的、可控的调控框架和多评分者评估协议,从而能够进行可组合的混合情感合成和可靠的文本情感不匹配合成。我们的结果首次证明,情感韵律和表达变异性主要由TTS语言模块而不是流匹配模块合成,并且还提供了一种轻量级的调控方法来生成自然、类人情感语音。
🔬 方法详解
问题定义:现有情感TTS系统通常只能生成单一情感的语音,无法处理人类语音中复杂的情感组合和情感与文本内容不一致的情况。这限制了TTS系统的表达能力和真实感,使其难以应用于需要细致情感控制的场景。现有方法缺乏对情感表示可控性的系统分析和评估。
核心思路:CoCoEmo的核心思路是通过激活调控(Activation Steering)来控制TTS模型的情感输出。具体来说,通过在模型的潜在空间中找到与特定情感相关的方向向量,并在推理时沿着这些方向向量调整激活值,从而实现对情感的精确控制。这种方法允许组合多个情感,并生成与文本情感不匹配的语音。
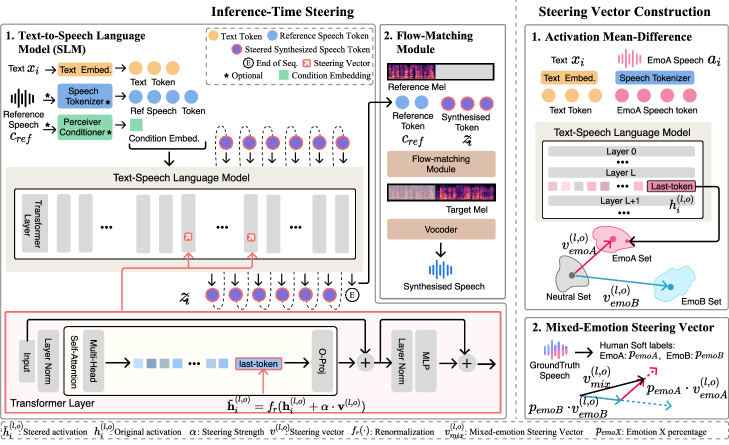
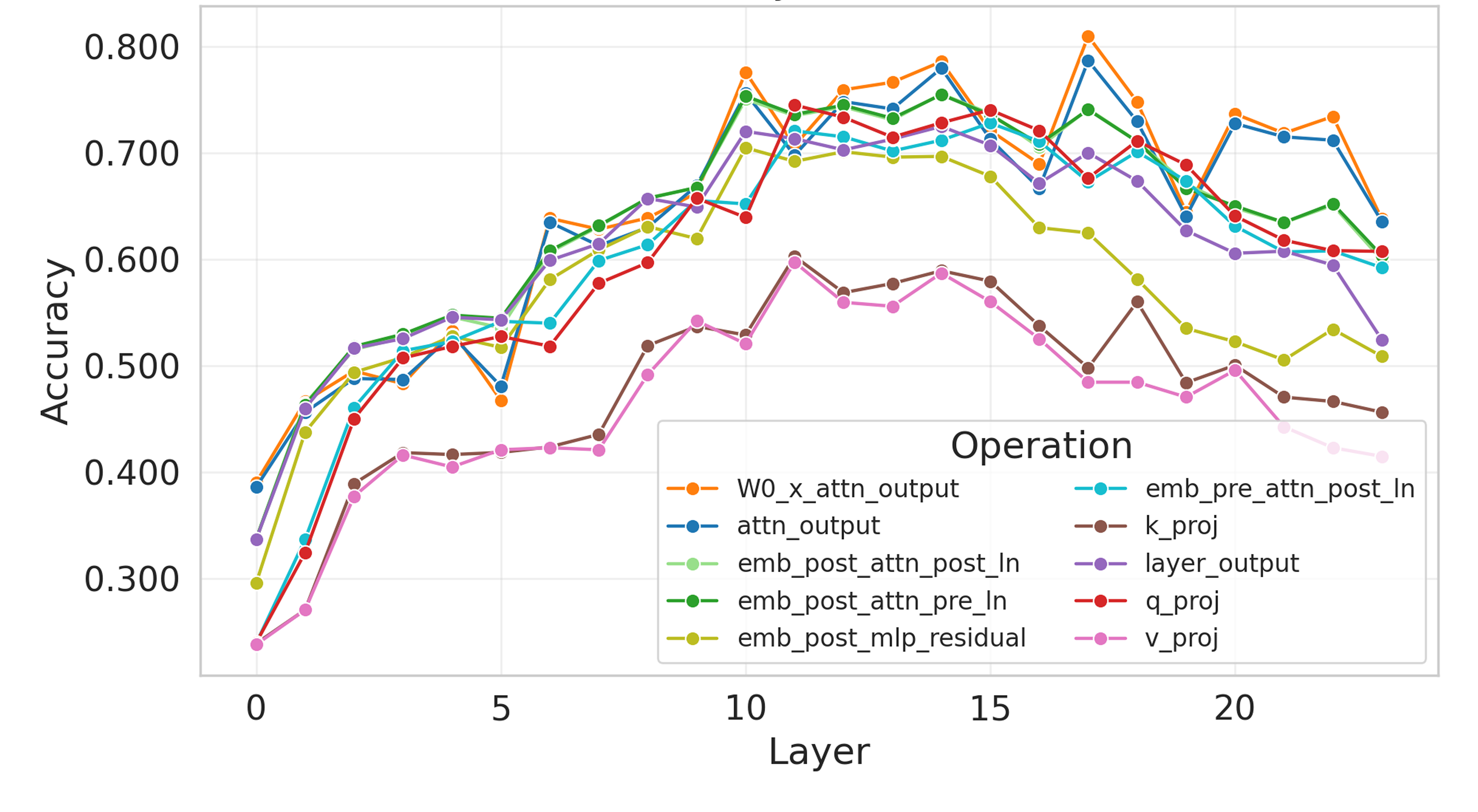
技术框架:CoCoEmo基于混合TTS架构,该架构通常包含一个语言模块(例如Transformer)和一个声码器(例如Flow-matching模型)。论文的关键发现是情感韵律主要由语言模块合成,因此激活调控主要应用于语言模块的中间层。整个流程包括:1) 训练一个情感TTS模型;2) 通过实验确定情感方向向量;3) 在推理时,根据目标情感组合,沿着相应的情感方向向量调整语言模块的激活值;4) 使用声码器将调整后的语言模块输出转换为语音。
关键创新:CoCoEmo的关键创新在于:1) 首次系统地分析了激活调控在混合TTS模型中的情感控制能力;2) 提出了一个定量、可控的调控框架,可以实现可组合的混合情感合成和文本情感不匹配合成;3) 揭示了情感韵律主要由TTS语言模块合成的结论,为情感TTS的研究提供了新的视角。
关键设计:论文使用多评分者评估协议来评估合成语音的质量和情感表达的准确性。情感方向向量的确定通过实验进行,例如通过计算不同情感类别激活值的平均差异。激活调控的强度通过一个可调节的参数来控制,该参数决定了沿着情感方向向量移动的距离。损失函数方面,论文沿用基线TTS模型的损失函数,没有引入额外的损失函数。
🖼️ 关键图片
📊 实验亮点
实验结果表明,CoCoEmo能够合成具有可组合混合情感和文本情感不匹配的语音,并且情感表达的准确性得到了多评分者评估的验证。论文首次证明了情感韵律主要由TTS语言模块合成,为情感TTS的研究提供了新的方向。该方法提供了一种轻量级的调控方法,可以生成自然、类人情感语音。
🎯 应用场景
CoCoEmo可应用于需要细致情感控制的语音合成场景,例如:个性化语音助手、情感化游戏角色、以及辅助情感障碍患者进行交流的工具。通过精确控制语音的情感表达,可以提升人机交互的自然性和用户体验。未来,该技术有望应用于更广泛的领域,例如:情感化广告、有声读物等。
📄 摘要(原文)
Emotional expression in human speech is nuanced and compositional, often involving multiple, sometimes conflicting, affective cues that may diverge from linguistic content. In contrast, most expressive text-to-speech systems enforce a single utterance-level emotion, collapsing affective diversity and suppressing mixed or text-emotion-misaligned expression. While activation steering via latent direction vectors offers a promising solution, it remains unclear whether emotion representations are linearly steerable in TTS, where steering should be applied within hybrid TTS architectures, and how such complex emotion behaviors should be evaluated. This paper presents the first systematic analysis of activation steering for emotional control in hybrid TTS models, introducing a quantitative, controllable steering framework, and multi-rater evaluation protocols that enable composable mixed-emotion synthesis and reliable text-emotion mismatch synthesis. Our results demonstrate, for the first time, that emotional prosody and expressive variability are primarily synthesized by the TTS language module instead of the flow-matching module, and also provide a lightweight steering approach for generating natural, human-like emotional speech.