Chain-of-Goals Hierarchical Policy for Long-Horizon Offline Goal-Conditioned RL
作者: Jinwoo Choi, Sang-Hyun Lee, Seung-Woo Seo
分类: cs.LG, cs.AI
发布日期: 2026-02-03
备注: 22 pages
💡 一句话要点
提出链式目标分层策略(CoGHP)以解决离线长程目标条件强化学习问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 离线强化学习 分层强化学习 目标条件强化学习 长程任务 自回归模型 链式思考 MLP-Mixer
📋 核心要点
- 现有分层强化学习方法在长程任务中表现不佳,因为它们依赖于分离的网络且仅生成单个子目标。
- CoGHP将分层决策建模为自回归序列生成,利用潜在子目标链作为推理步骤,指导后续动作。
- 实验表明,CoGHP在导航和操作任务中显著优于现有离线强化学习基线,尤其是在长程任务上。
📝 摘要(中文)
离线目标条件强化学习在长程任务中仍然面临挑战。分层方法通过分解任务来缓解这个问题,但大多数现有方法依赖于独立的高层和低层网络,并且只生成单个中间子目标,这使得它们不足以应对需要协调多个中间决策的复杂任务。为了解决这个局限性,我们从链式思考范式中汲取灵感,提出了一种新的框架——链式目标分层策略(CoGHP),它将分层决策制定重新定义为统一架构中的自回归序列建模。给定一个状态和一个最终目标,CoGHP自回归地生成一个潜在子目标序列,然后是原始动作,其中每个潜在子目标都充当条件后续预测的推理步骤。为了有效地实现这一点,我们率先使用MLP-Mixer骨干网络,该网络支持跨token通信并捕获状态、目标、潜在子目标和动作之间的结构关系。在具有挑战性的导航和操作基准测试中,CoGHP始终优于强大的离线基线,证明了其在长程任务中性能的提升。
🔬 方法详解
问题定义:论文旨在解决离线目标条件强化学习中,长程任务难以学习的问题。现有分层强化学习方法通常依赖于独立的高层和低层网络,并且仅生成单个中间子目标,无法有效处理需要多个中间决策的复杂任务。这些方法难以捕捉长程任务中的依赖关系,导致性能下降。
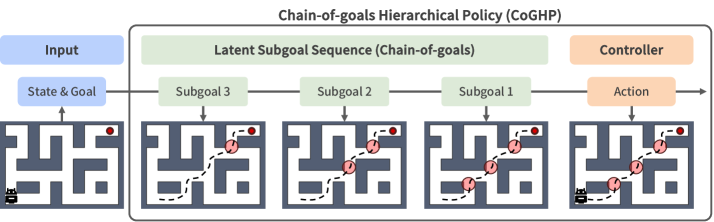
核心思路:论文的核心思路是将分层决策过程建模为自回归序列生成。受链式思考(Chain-of-Thought)的启发,CoGHP生成一系列潜在子目标,每个子目标都作为推理步骤,指导后续子目标的生成,最终生成原始动作。这种链式推理的方式能够更好地捕捉长程任务中的依赖关系,从而提高学习效率和性能。
技术框架:CoGHP的整体架构是一个统一的自回归模型。给定当前状态和最终目标,模型首先自回归地生成一系列潜在子目标。然后,模型根据当前状态和已生成的子目标序列,预测下一步的原始动作。整个过程可以看作是一个序列到序列的生成过程,其中输入是状态和目标,输出是子目标序列和动作。
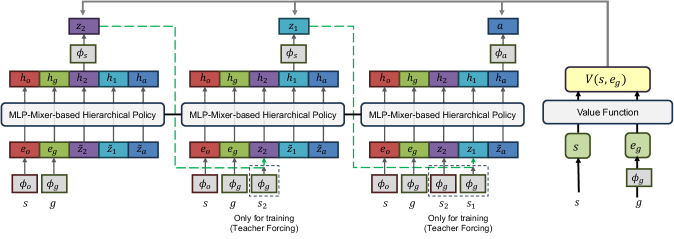
关键创新:CoGHP的关键创新在于将分层决策建模为自回归序列生成,并引入了潜在子目标链的概念。与现有方法不同,CoGHP能够生成多个中间子目标,并利用这些子目标作为推理步骤,指导后续决策。此外,论文还率先使用MLP-Mixer作为骨干网络,以支持跨token通信并捕获状态、目标、子目标和动作之间的结构关系。
关键设计:CoGHP使用MLP-Mixer作为骨干网络,用于编码状态、目标、子目标和动作。损失函数包括子目标预测损失和动作预测损失。子目标预测损失用于训练模型生成合理的子目标序列,动作预测损失用于训练模型根据当前状态和子目标序列预测下一步的动作。具体参数设置和训练细节在论文中有详细描述。
🖼️ 关键图片

📊 实验亮点
CoGHP在具有挑战性的导航和操作基准测试中表现出色,显著优于现有的离线强化学习基线。实验结果表明,CoGHP在长程任务中性能提升尤为明显。例如,在某些任务中,CoGHP的成功率比最佳基线提高了10%以上。这些结果验证了CoGHP在长程离线目标条件强化学习中的有效性。
🎯 应用场景
CoGHP具有广泛的应用前景,例如机器人导航、操作、游戏AI等。它可以应用于需要长程规划和复杂决策的任务中,例如自动驾驶、智能制造、家庭服务机器人等。通过学习离线数据,CoGHP可以快速适应新的环境和任务,降低了部署成本和风险。未来,CoGHP可以与其他技术相结合,例如模仿学习、强化学习等,进一步提高性能和泛化能力。
📄 摘要(原文)
Offline goal-conditioned reinforcement learning remains challenging for long-horizon tasks. While hierarchical approaches mitigate this issue by decomposing tasks, most existing methods rely on separate high- and low-level networks and generate only a single intermediate subgoal, making them inadequate for complex tasks that require coordinating multiple intermediate decisions. To address this limitation, we draw inspiration from the chain-of-thought paradigm and propose the Chain-of-Goals Hierarchical Policy (CoGHP), a novel framework that reformulates hierarchical decision-making as autoregressive sequence modeling within a unified architecture. Given a state and a final goal, CoGHP autoregressively generates a sequence of latent subgoals followed by the primitive action, where each latent subgoal acts as a reasoning step that conditions subsequent predictions. To implement this efficiently, we pioneer the use of an MLP-Mixer backbone, which supports cross-token communication and captures structural relationships among state, goal, latent subgoals, and action. Across challenging navigation and manipulation benchmarks, CoGHP consistently outperforms strong offline baselines, demonstrating improved performance on long-horizon tasks.