An Approximate Ascent Approach To Prove Convergence of PPO
作者: Leif Doering, Daniel Schmidt, Moritz Melcher, Sebastian Kassing, Benedikt Wille, Tilman Aach, Simon Weissmann
分类: cs.LG, cs.AI, math.OC
发布日期: 2026-02-03
💡 一句话要点
提出近似上升方法,证明PPO收敛性,并解决优势函数估计问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 近端策略优化 PPO 强化学习 收敛性分析 策略梯度 优势函数估计 广义优势估计 权重校正
📋 核心要点
- PPO算法虽然应用广泛,但缺乏坚实的理论基础,收敛性证明和优势分析是关键挑战。
- 论文将PPO的策略更新解释为近似策略梯度上升,通过控制替代梯度偏差证明了PPO的收敛性。
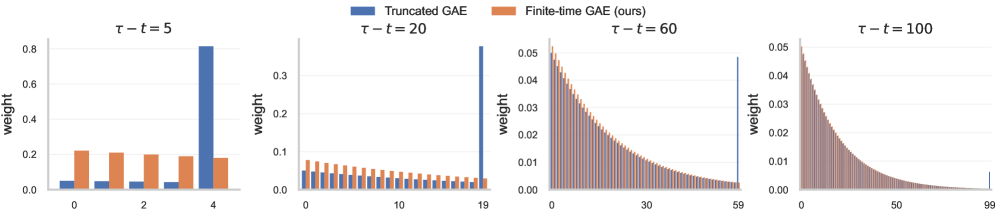
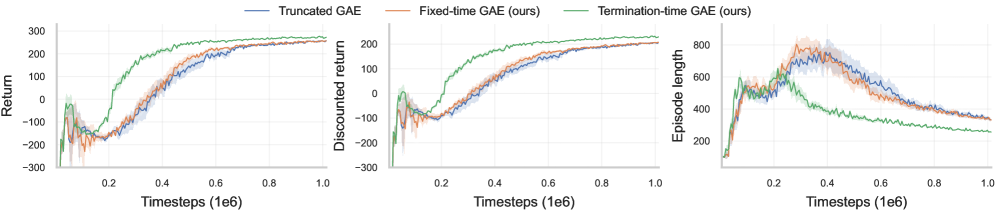
- 论文指出了截断广义优势估计的缺陷,并提出权重校正方法,在Lunar Lander等环境中取得显著改进。
📝 摘要(中文)
近端策略优化(PPO)是最广泛使用的深度强化学习算法之一,但其理论基础仍不完善。最重要的是,PPO的收敛性和基本优势的理解仍然是开放问题。在标准理论假设下,我们展示了PPO的策略更新方案(在具有替代梯度的多用途rollout上执行多个epoch的minibatch更新)如何被解释为近似策略梯度上升。我们展示了如何控制替代梯度累积的偏差,并使用随机重排技术来证明PPO的收敛定理,从而阐明PPO的成功。此外,我们还发现PPO中常用的截断广义优势估计中一个先前被忽视的问题:几何加权方案导致在episode边界上无限质量坍缩到最长的k步优势估计器上。经验评估表明,一个简单的权重校正可以在具有强终端信号的环境(如Lunar Lander)中产生显著的改进。
🔬 方法详解
问题定义:PPO算法虽然在实践中表现良好,但缺乏严格的收敛性证明。此外,常用的截断广义优势估计(GAE)在episode边界存在潜在问题,可能影响算法性能。现有方法未能充分理解PPO的收敛机制,也忽略了GAE的权重分配问题。
核心思路:论文的核心思路是将PPO的策略更新过程视为近似的策略梯度上升,通过分析和控制替代梯度带来的偏差,证明PPO的收敛性。同时,通过分析GAE的权重分配机制,发现其在episode边界存在权重坍缩问题,并提出相应的权重校正方法。
技术框架:论文主要包含以下几个部分:1) 将PPO的策略更新过程形式化为近似策略梯度上升;2) 分析替代梯度带来的偏差,并提出控制偏差的方法;3) 利用随机重排技术,证明PPO的收敛性;4) 分析GAE的权重分配机制,发现其在episode边界存在权重坍缩问题;5) 提出权重校正方法,并进行实验验证。
关键创新:论文最重要的技术创新点在于:1) 将PPO的策略更新过程与策略梯度上升联系起来,为PPO的收敛性分析提供了新的视角;2) 发现了GAE在episode边界存在权重坍缩问题,并提出了相应的权重校正方法。与现有方法相比,该论文更深入地理解了PPO的收敛机制,并解决了GAE的一个潜在问题。
关键设计:论文的关键设计包括:1) 使用KL散度约束来控制策略更新的幅度;2) 使用截断广义优势估计(GAE)来估计优势函数;3) 提出权重校正方法,以解决GAE在episode边界的权重坍缩问题。具体的权重校正方法未知,需要在论文中查找。
🖼️ 关键图片

📊 实验亮点
论文通过实验验证了所提出的权重校正方法在Lunar Lander等具有强终端信号的环境中的有效性,表明该方法可以显著提升PPO算法的性能。具体的性能提升数据未知,需要在论文中查找。
🎯 应用场景
该研究成果可应用于各种强化学习任务,尤其是在需要高稳定性和收敛性的场景中,例如机器人控制、自动驾驶、游戏AI等。通过改进优势函数估计,可以提升强化学习算法的性能和鲁棒性,使其在更复杂的环境中得到应用。
📄 摘要(原文)
Proximal Policy Optimization (PPO) is among the most widely used deep reinforcement learning algorithms, yet its theoretical foundations remain incomplete. Most importantly, convergence and understanding of fundamental PPO advantages remain widely open. Under standard theory assumptions we show how PPO's policy update scheme (performing multiple epochs of minibatch updates on multi-use rollouts with a surrogate gradient) can be interpreted as approximated policy gradient ascent. We show how to control the bias accumulated by the surrogate gradients and use techniques from random reshuffling to prove a convergence theorem for PPO that sheds light on PPO's success. Additionally, we identify a previously overlooked issue in truncated Generalized Advantage Estimation commonly used in PPO. The geometric weighting scheme induces infinite mass collapse onto the longest $k$-step advantage estimator at episode boundaries. Empirical evaluations show that a simple weight correction can yield substantial improvements in environments with strong terminal signal, such as Lunar Lander.