MeKi: Memory-based Expert Knowledge Injection for Efficient LLM Scaling
作者: Ning Ding, Fangcheng Liu, Kyungrae Kim, Linji Hao, Kyeng-Hun Lee, Hyeonmok Ko, Yehui Tang
分类: cs.LG, cs.AI, cs.CL
发布日期: 2026-02-03
🔗 代码/项目: GITHUB
💡 一句话要点
MeKi:利用存储空间扩展LLM,解决边缘设备上LLM部署难题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 边缘计算 模型压缩 知识注入 内存扩展
📋 核心要点
- 现有LLM扩展方法依赖增加参数或计算量,不适用于资源受限的边缘设备。
- MeKi通过token级内存专家注入预存语义知识,利用存储空间扩展LLM容量。
- MeKi通过重参数化和知识卸载,实现零推理延迟,显著优于同速的密集LLM。
📝 摘要(中文)
大型语言模型(LLM)的扩展通常依赖于增加参数数量或测试时的计算量来提高性能。然而,由于有限的RAM和NPU资源,这些策略对于边缘设备部署是不切实际的。尽管存在硬件限制,但在智能手机等边缘设备上部署高性能LLM对于用户体验至关重要。为了解决这个问题,我们提出了一种新颖的系统MeKi(基于内存的专家知识注入),该系统通过存储空间而非FLOPs来扩展LLM容量。MeKi为每个Transformer层配备了token级别的内存专家,将预先存储的语义知识注入到生成过程中。为了弥合训练容量和推理效率之间的差距,我们采用了一种重参数化策略,将训练期间使用的参数矩阵折叠成一个紧凑的静态查找表。通过将知识卸载到ROM,MeKi将模型容量与计算成本分离,引入了零推理延迟开销。大量的实验表明,MeKi显著优于具有相同推理速度的密集LLM基线,验证了基于内存的扩展范式对于片上LLM的有效性。
🔬 方法详解
问题定义:论文旨在解决在资源受限的边缘设备上部署大型语言模型(LLM)的问题。现有方法通过增加模型参数或计算量来提升性能,但这在边缘设备上不可行,因为边缘设备的RAM和NPU资源有限。因此,如何在不增加计算负担的前提下,提升边缘设备上LLM的性能是一个关键挑战。
核心思路:MeKi的核心思路是利用存储空间(ROM)来扩展LLM的容量,而不是依赖于计算资源(FLOPs)。通过将预先训练好的知识存储在ROM中,并在推理时按需注入到Transformer层中,MeKi可以在不增加推理延迟的情况下,提升模型的性能。这种方法将模型容量与计算成本解耦,使得在资源受限的设备上部署大型模型成为可能。
技术框架:MeKi的技术框架主要包括以下几个部分:1) Token-level Memory Experts:每个Transformer层都配备了多个token级别的内存专家,每个专家存储了特定的语义知识。2) Knowledge Injection:在推理过程中,根据当前token的上下文,选择合适的内存专家,并将专家中的知识注入到Transformer层的计算中。3) Re-parameterization:为了将训练期间使用的参数矩阵折叠成一个紧凑的静态查找表,MeKi采用了一种重参数化策略。4) Knowledge Offloading:将重参数化后的知识存储在ROM中,以便在推理时快速访问。
关键创新:MeKi的关键创新在于它提出了一种基于内存的LLM扩展范式。与传统的基于计算的扩展方法不同,MeKi利用存储空间来增加模型容量,从而避免了增加推理延迟。此外,MeKi的重参数化策略和知识卸载机制使得可以在不增加计算负担的情况下,将大量的知识注入到模型中。
关键设计:MeKi的关键设计包括:1) Memory Expert Selection:如何选择合适的内存专家来注入知识是一个关键问题。论文可能采用了某种注意力机制或路由算法来实现专家的选择。2) Knowledge Injection Method:如何将内存专家中的知识注入到Transformer层的计算中也是一个关键设计。论文可能采用了某种加权求和或拼接的方式来实现知识的注入。3) Re-parameterization Strategy:具体的重参数化策略细节,例如如何将参数矩阵折叠成静态查找表,以及如何保证重参数化后的模型性能。
🖼️ 关键图片
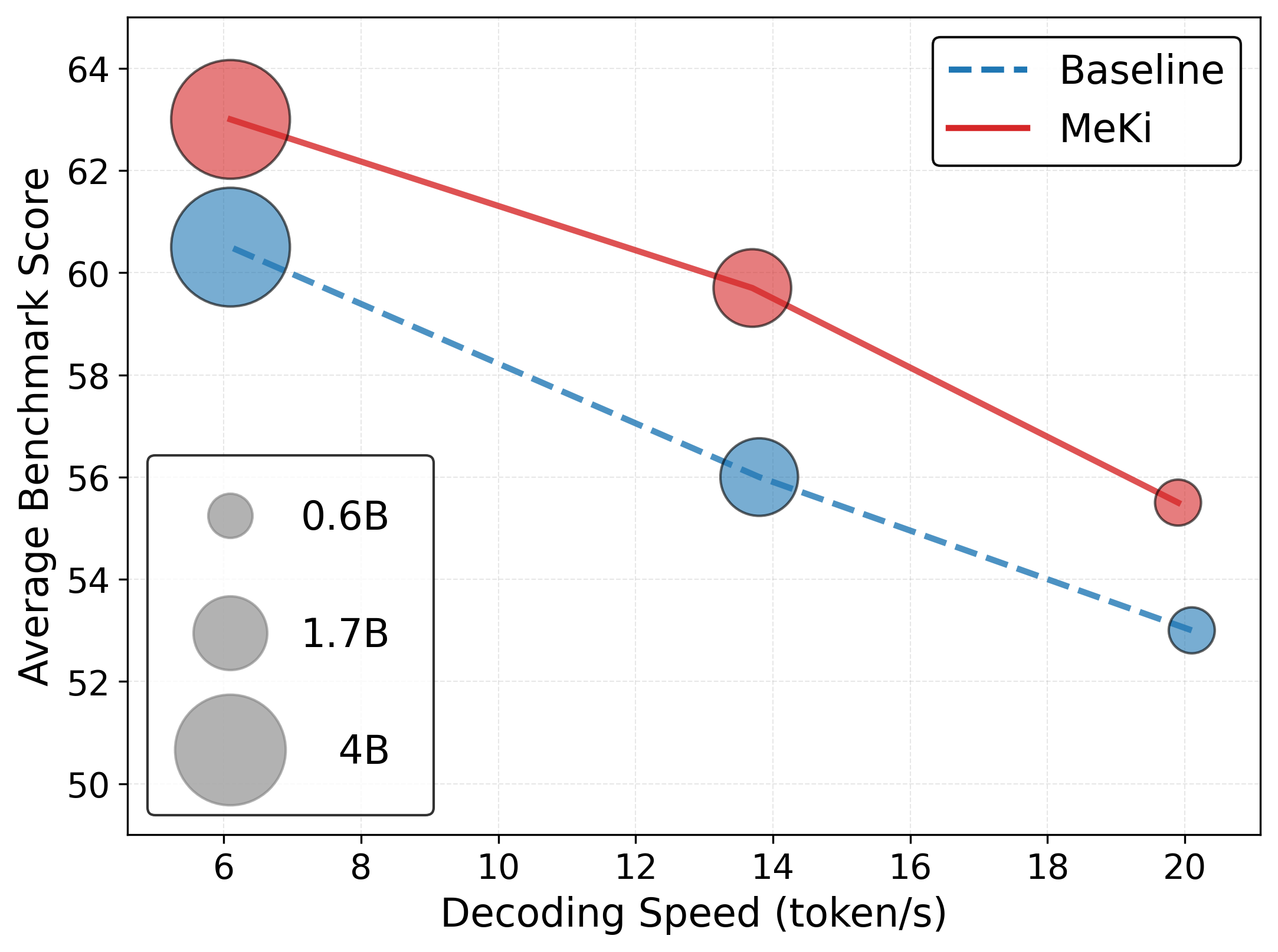
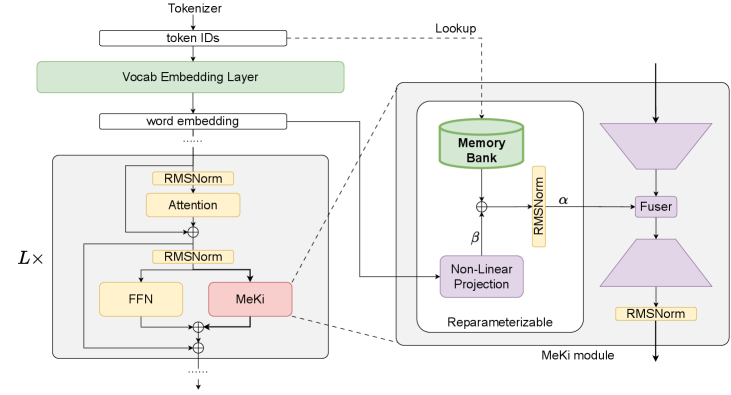

📊 实验亮点
实验结果表明,MeKi在保持相同推理速度的前提下,显著优于传统的密集LLM。具体来说,MeKi在多个NLP任务上取得了明显的性能提升,验证了基于内存的扩展范式对于片上LLM的有效性。论文中给出了具体的性能数据和对比基线,展示了MeKi的优越性。
🎯 应用场景
MeKi在边缘设备上的LLM部署具有广泛的应用前景,例如智能手机、物联网设备和可穿戴设备。它可以提升这些设备上的自然语言处理能力,例如语音助手、机器翻译和文本摘要。通过在本地运行LLM,MeKi还可以提高用户隐私和数据安全性,避免将数据上传到云端。
📄 摘要(原文)
Scaling Large Language Models (LLMs) typically relies on increasing the number of parameters or test-time computations to boost performance. However, these strategies are impractical for edge device deployment due to limited RAM and NPU resources. Despite hardware constraints, deploying performant LLM on edge devices such as smartphone remains crucial for user experience. To address this, we propose MeKi (Memory-based Expert Knowledge Injection), a novel system that scales LLM capacity via storage space rather than FLOPs. MeKi equips each Transformer layer with token-level memory experts that injects pre-stored semantic knowledge into the generation process. To bridge the gap between training capacity and inference efficiency, we employ a re-parameterization strategy to fold parameter matrices used during training into a compact static lookup table. By offloading the knowledge to ROM, MeKi decouples model capacity from computational cost, introducing zero inference latency overhead. Extensive experiments demonstrate that MeKi significantly outperforms dense LLM baselines with identical inference speed, validating the effectiveness of memory-based scaling paradigm for on-device LLMs. Project homepage is at https://github.com/ningding-o/MeKi.