Entropy-Gated Selective Policy Optimization:Token-Level Gradient Allocation for Hybrid Training of Large Language Models
作者: Yuelin Hu, Zhengxue Cheng, Wei Liu, Li Song
分类: cs.LG, cs.AI
发布日期: 2026-02-03
备注: accepted by cscwd2026
💡 一句话要点
提出熵门控选择性策略优化EGSPO,用于大语言模型混合训练中的token级梯度分配。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 混合训练 强化学习 监督微调 梯度分配
📋 核心要点
- 现有大语言模型混合训练方法通常在样本级别混合监督微调和强化学习,缺乏token级别的细粒度控制。
- EGSPO通过预测熵引导梯度分配,对高熵token进行充分PPO更新以鼓励探索,对低熵token进行衰减PPO更新以减少方差。
- 实验表明,EGSPO在数学推理任务上取得了显著提升,且计算开销增加有限,验证了其有效性。
📝 摘要(中文)
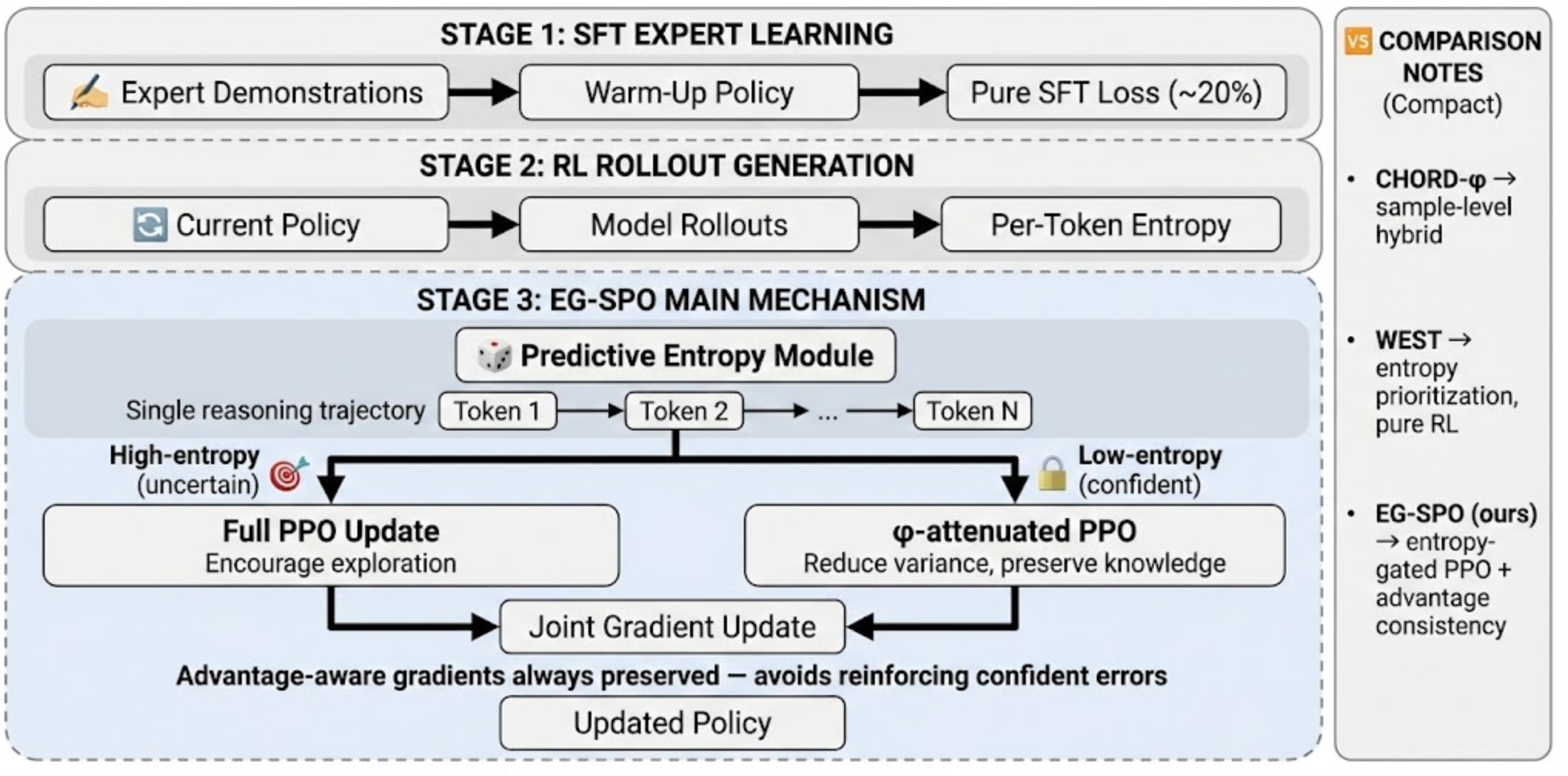
本文提出了一种名为熵门控选择性策略优化(EGSPO)的三阶段框架,用于大语言模型的混合训练。该方法在样本级别混合的基础上,进一步引入了token级别的梯度调制。第一阶段,通过纯监督微调(SFT)损失,利用专家演示数据建立可靠的预热策略。第二阶段,通过强化学习(RL)rollout生成,从当前策略中采样轨迹,并计算每个token的预测熵。第三阶段,EGSPO机制应用熵门控梯度分配:预测熵模块将高熵token路由到完整的PPO更新,以鼓励探索;将低熵token路由到衰减的PPO更新,以减少方差并保留知识。重要的是,两个分支都包含优势函数A_t,确保不正确的轨迹接收到一致的负学习信号,并防止强化自信的错误。EGSPO在数学推理基准测试中取得了持续的改进,在AIME上比CHORD phi基线提高了3.8%,在MATH上提高了2.9%,而计算开销仅增加了3.4%。
🔬 方法详解
问题定义:现有的大语言模型混合训练方法,例如结合监督微调(SFT)和强化学习(RL),通常在样本级别进行混合。这种方法缺乏对模型生成过程中每个token的细粒度控制,无法区分模型在不同token上的置信度,可能导致对错误token的过度强化或对正确token的过度抑制。因此,如何更有效地利用SFT和RL的优势,实现token级别的梯度优化,是一个亟待解决的问题。
核心思路:EGSPO的核心思路是利用token级别的预测熵来指导梯度分配。预测熵可以反映模型对当前token预测的不确定性,高熵表示模型不确定,需要更多探索;低熵表示模型比较确定,应该减少扰动以保持知识。通过这种方式,EGSPO能够自适应地调整每个token的梯度更新幅度,从而更有效地进行模型训练。
技术框架:EGSPO是一个三阶段的训练框架: 1. SFT专家学习阶段:使用专家演示数据,通过标准的监督微调(SFT)训练模型,建立一个可靠的预热策略。 2. RL rollout生成阶段:从当前策略中采样轨迹,并计算每个token的预测熵。预测熵通过模型输出的softmax概率分布计算得到。 3. EGSPO机制阶段:根据token的预测熵,将token分为高熵和低熵两类。高熵token被路由到完整的PPO更新,以鼓励探索;低熵token被路由到衰减的PPO更新,以减少方差并保留知识。两个分支都使用优势函数A_t,确保学习信号的一致性。
关键创新:EGSPO的关键创新在于引入了token级别的梯度调制机制。与传统的样本级别混合训练方法不同,EGSPO能够根据每个token的预测熵,自适应地调整梯度更新幅度。这种细粒度的控制使得模型能够更有效地利用SFT和RL的优势,从而提高训练效果。
关键设计:EGSPO的关键设计包括: 1. 预测熵的计算:使用模型输出的softmax概率分布计算每个token的预测熵,作为梯度分配的依据。 2. 熵门控机制:根据预测熵,将token分为高熵和低熵两类,并分别进行不同的PPO更新。 3. 优势函数A_t的使用:在两个分支中都使用优势函数A_t,确保学习信号的一致性,避免强化自信的错误。 4. 衰减系数的选择:对于低熵token,需要选择合适的衰减系数,以平衡方差减少和知识保留。
🖼️ 关键图片
📊 实验亮点
EGSPO在数学推理基准测试中取得了显著的改进。在AIME数据集上,EGSPO比CHORD phi基线提高了3.8%;在MATH数据集上,EGSPO比CHORD phi基线提高了2.9%。这些结果表明,EGSPO能够有效地提高大语言模型在复杂推理任务上的性能,并且计算开销仅增加了3.4%。
🎯 应用场景
EGSPO方法可应用于各种需要结合专家知识和探索性学习的大语言模型训练场景,例如对话系统、代码生成、数学推理等。通过token级别的梯度调制,EGSPO能够更有效地利用SFT和RL的优势,提高模型的性能和泛化能力。该方法具有广泛的应用前景,可以促进大语言模型在各个领域的应用。
📄 摘要(原文)
Hybrid training methods for large language models combine supervised fine tuning (SFT) on expert demonstrations with reinforcement learning (RL) on model rollouts, typically at the sample level. We propose Entropy Gated Selective Policy Optimization (EGSPO), a three stage framework that extends sample level mixing with token level gradient modulation. Stage 1, SFT expert learning, establishes a reliable warm up policy using expert demonstrations with a pure SFT loss. Stage 2, RL rollout generation, samples trajectories from the current policy and computes per token predictive entropy. Stage 3, the EGSPO mechanism, applies entropy gated gradient allocation: a predictive entropy module routes high entropy tokens to full PPO updates to encourage exploration, and low entropy tokens to attenuated PPO updates to reduce variance and preserve knowledge. Critically, both branches incorporate the advantage function A_t, ensuring that incorrect trajectories receive consistent negative learning signals and preventing reinforcement of confident errors. EGSPO achieves consistent improvements on mathematical reasoning benchmarks, with gains of 3.8 percent on AIME and 2.9 percent on MATH over the CHORD phi baseline, while incurring only 3.4 percent additional computational overhead.