medR: Reward Engineering for Clinical Offline Reinforcement Learning via Tri-Drive Potential Functions
作者: Qianyi Xu, Gousia Habib, Feng Wu, Yanrui Du, Zhihui Chen, Swapnil Mishra, Dilruk Perera, Mengling Feng
分类: cs.LG
发布日期: 2026-02-03
💡 一句话要点
medR:通过三驱动势函数进行临床离线强化学习的奖励工程
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 奖励工程 大型语言模型 动态治疗方案 临床应用
📋 核心要点
- 临床强化学习面临奖励工程的挑战,即如何定义安全有效的奖励信号,现有方法依赖手动启发式,泛化性差。
- 论文提出利用大型语言模型(LLMs)自动进行离线奖励设计和验证,构建包含生存、置信度和能力的势函数。
- 通过定量指标评估和选择最佳奖励结构,并利用LLM驱动的领域知识,提升特定疾病的策略性能。
📝 摘要(中文)
强化学习(RL)为优化动态治疗方案(DTRs)提供了一个强大的框架。然而,临床RL从根本上受到奖励工程的瓶颈限制:即在复杂、稀疏的离线环境中定义能够安全有效地指导策略学习的信号的挑战。现有的方法通常依赖于无法推广到不同病理的手动启发式方法。为了解决这个问题,我们提出了一个自动化的流程,利用大型语言模型(LLMs)进行离线奖励设计和验证。我们使用由生存、置信度和能力三个核心组件组成的势函数来构建奖励函数。我们进一步引入了定量指标,以便在部署之前严格评估和选择最佳奖励结构。通过整合LLM驱动的领域知识,我们的框架可以自动设计针对特定疾病的奖励函数,同时显著提高最终策略的性能。
🔬 方法详解
问题定义:临床强化学习旨在优化动态治疗方案,但奖励函数的设计是关键瓶颈。现有方法依赖人工设计的启发式规则,难以泛化到不同的疾病和治疗场景,且缺乏有效的验证手段,导致策略学习效率低下甚至产生不良后果。因此,如何自动、安全、有效地设计奖励函数是亟待解决的问题。
核心思路:论文的核心思路是利用大型语言模型(LLMs)的领域知识,自动生成和验证奖励函数。通过将奖励函数分解为生存、置信度和能力三个核心组件,并使用势函数进行建模,从而实现对治疗效果的综合评估。同时,引入定量指标来评估奖励函数的质量,确保策略学习的安全性。
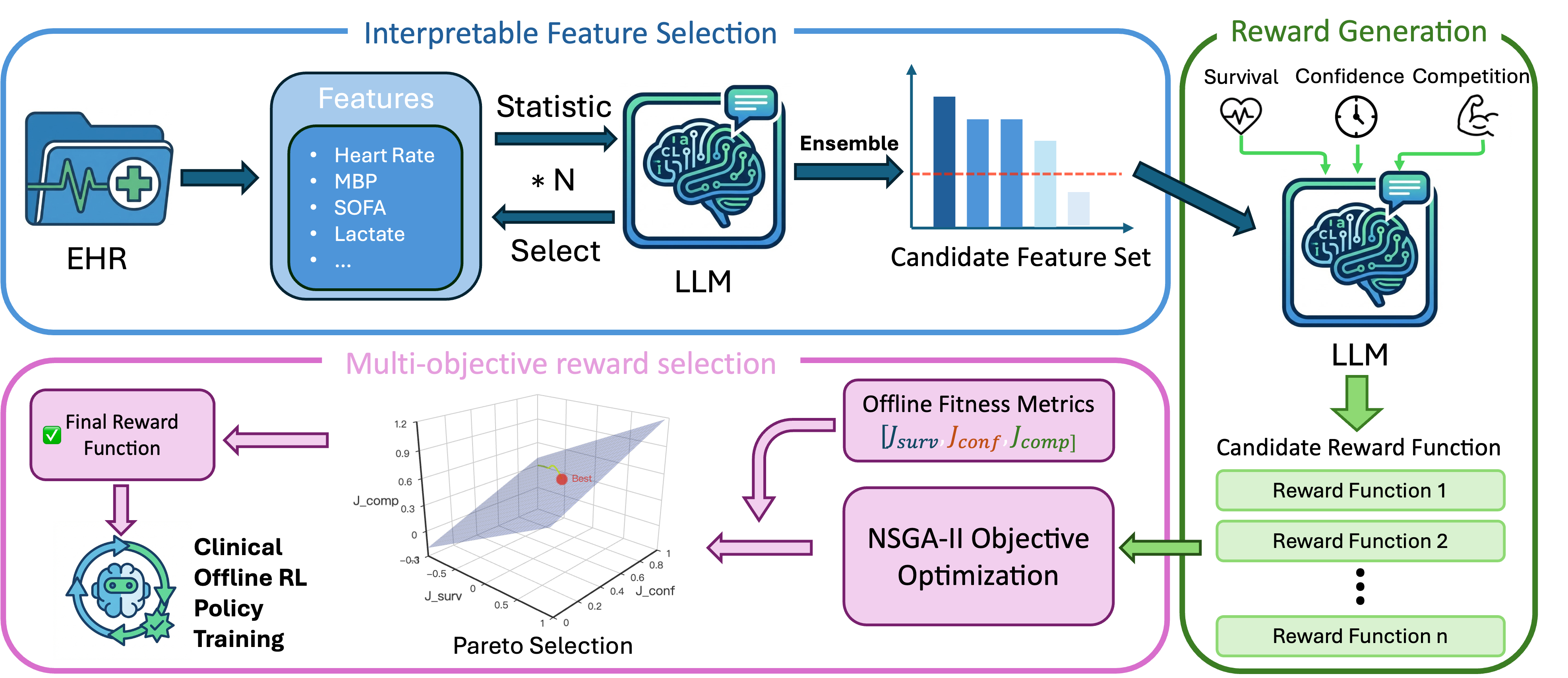
技术框架:该框架包含以下几个主要阶段:1) LLM驱动的奖励函数设计:利用LLM生成候选的奖励函数,这些函数基于医学知识和临床指南。2) 势函数构建:将奖励函数分解为生存、置信度和能力三个组件,并使用势函数进行建模。3) 奖励函数评估:使用定量指标评估候选奖励函数的质量,例如奖励的稀疏性、方差等。4) 奖励函数选择:根据评估结果选择最佳的奖励函数。5) 离线强化学习:使用选择的奖励函数训练强化学习策略。
关键创新:该论文的关键创新在于:1) 自动化奖励函数设计:利用LLM自动生成候选奖励函数,减少了人工干预。2) 三驱动势函数:将奖励函数分解为生存、置信度和能力三个核心组件,并使用势函数进行建模,从而实现对治疗效果的综合评估。3) 定量奖励函数评估:引入定量指标来评估奖励函数的质量,确保策略学习的安全性。
关键设计:论文使用生存、置信度和能力三个组件构建势函数。生存组件旨在鼓励延长患者的生存时间;置信度组件旨在衡量治疗方案的确定性;能力组件旨在评估治疗方案的有效性。这些组件通过加权求和的方式组合成最终的奖励函数。此外,论文还定义了一系列定量指标,例如奖励的稀疏性、方差、相关性等,用于评估奖励函数的质量。
🖼️ 关键图片
📊 实验亮点
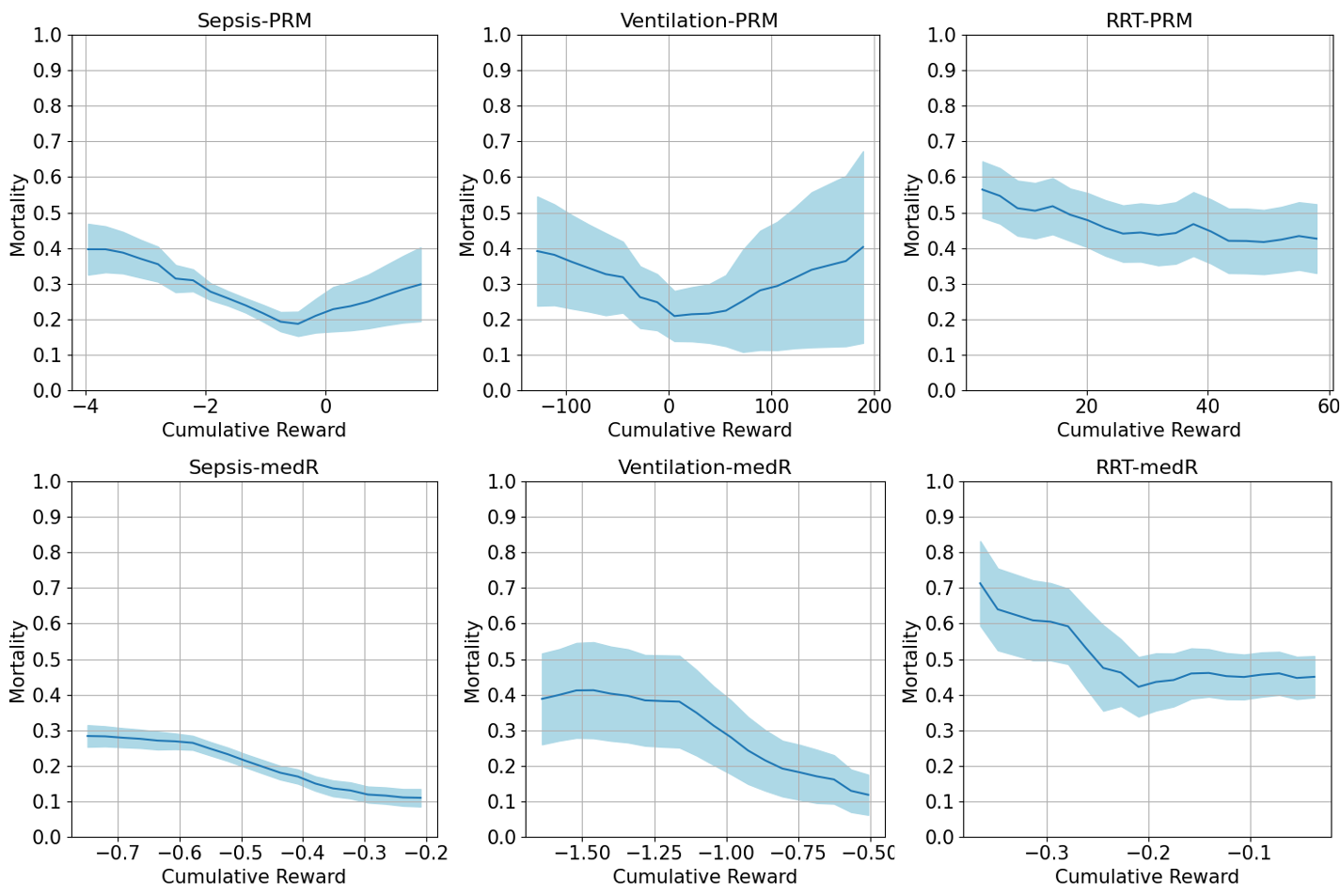
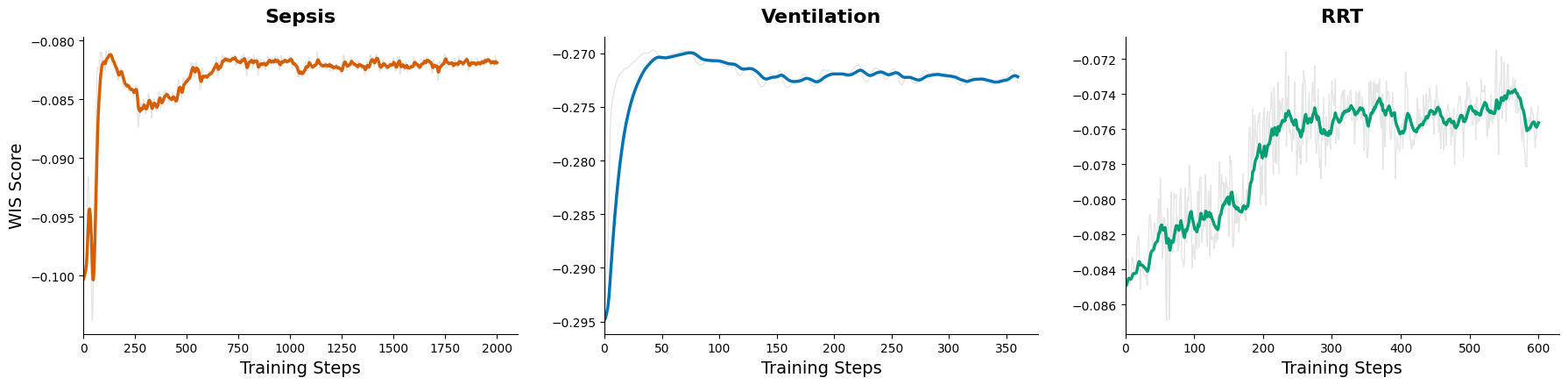
论文通过实验验证了所提出的medR框架的有效性。实验结果表明,与传统的手动设计的奖励函数相比,medR框架能够显著提高强化学习策略的性能。具体而言,medR框架在生存率、治疗效果等方面均取得了显著提升,并且能够更好地适应不同的疾病和治疗场景。
🎯 应用场景
该研究成果可应用于多种疾病的动态治疗方案优化,例如癌症、糖尿病、心血管疾病等。通过自动设计和验证奖励函数,可以显著提高治疗效果,降低医疗成本,并为患者提供个性化的治疗方案。未来,该方法有望推广到更广泛的医疗领域,例如药物研发、疾病预测等。
📄 摘要(原文)
Reinforcement Learning (RL) offers a powerful framework for optimizing dynamic treatment regimes (DTRs). However, clinical RL is fundamentally bottlenecked by reward engineering: the challenge of defining signals that safely and effectively guide policy learning in complex, sparse offline environments. Existing approaches often rely on manual heuristics that fail to generalize across diverse pathologies. To address this, we propose an automated pipeline leveraging Large Language Models (LLMs) for offline reward design and verification. We formulate the reward function using potential functions consisted of three core components: survival, confidence, and competence. We further introduce quantitative metrics to rigorously evaluate and select the optimal reward structure prior to deployment. By integrating LLM-driven domain knowledge, our framework automates the design of reward functions for specific diseases while significantly enhancing the performance of the resulting policies.