R1-SyntheticVL: Is Synthetic Data from Generative Models Ready for Multimodal Large Language Model?
作者: Jingyi Zhang, Tianyi Lin, Huanjin Yao, Xiang Lan, Shunyu Liu, Jiaxing Huang
分类: cs.LG, cs.AI, cs.CL, cs.CV
发布日期: 2026-02-03
💡 一句话要点
提出CADS框架,用于合成高质量多模态数据,提升MLLM在复杂现实任务中的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 数据合成 对抗学习 大型语言模型 集体智能
📋 核心要点
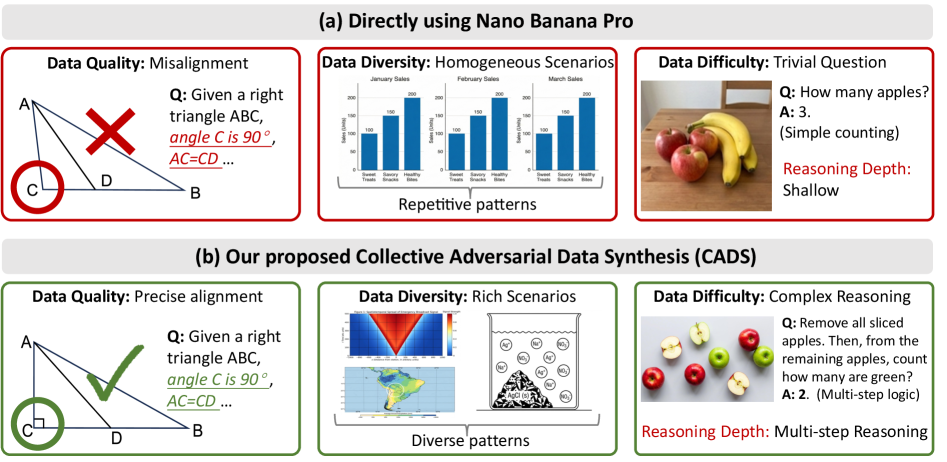
- 现有方法难以合成高质量、多样且具挑战性的多模态数据,限制了MLLM在复杂任务中的性能。
- CADS利用集体智能进行数据生成和质量评估,并通过对抗学习生成更具挑战性的样本。
- 实验表明,基于CADS合成数据训练的R1-SyntheticVL模型在多个基准测试中表现优异。
📝 摘要(中文)
本文旨在开发有效的数据合成技术,自主合成多模态训练数据,以增强多模态大型语言模型(MLLM)解决复杂现实世界任务的能力。为此,我们提出了一种新颖且通用的方法,即集体对抗数据合成(CADS),用于合成高质量、多样化和具有挑战性的多模态数据,以供MLLM使用。CADS的核心思想是利用集体智能来确保高质量和多样化的生成,同时探索对抗学习来合成具有挑战性的样本,从而有效地推动模型改进。具体而言,CADS包含两个循环阶段,即集体对抗数据生成(CAD-Generate)和集体对抗数据判断(CAD-Judge)。CAD-Generate利用集体知识共同生成新的和多样化的多模态数据,而CAD-Judge协同评估合成数据的质量。此外,CADS引入了一种对抗上下文优化机制,以优化生成上下文,从而鼓励生成具有挑战性和高价值的数据。借助CADS,我们构建了MMSynthetic-20K数据集,并训练了我们的模型R1-SyntheticVL,该模型在各种基准测试中表现出卓越的性能。
🔬 方法详解
问题定义:论文旨在解决多模态大型语言模型(MLLM)训练数据不足的问题,尤其是在复杂现实世界任务中。现有方法难以生成高质量、多样化且具有挑战性的多模态数据,导致MLLM在这些任务上的性能受限。痛点在于如何自动生成能够有效提升MLLM性能的合成数据。
核心思路:论文的核心思路是利用集体智能和对抗学习相结合的方式,提出集体对抗数据合成(CADS)框架。通过集体智能确保生成数据的质量和多样性,通过对抗学习生成具有挑战性的样本,从而更有效地驱动模型改进。这种设计旨在克服传统数据合成方法的局限性,生成更具价值的训练数据。
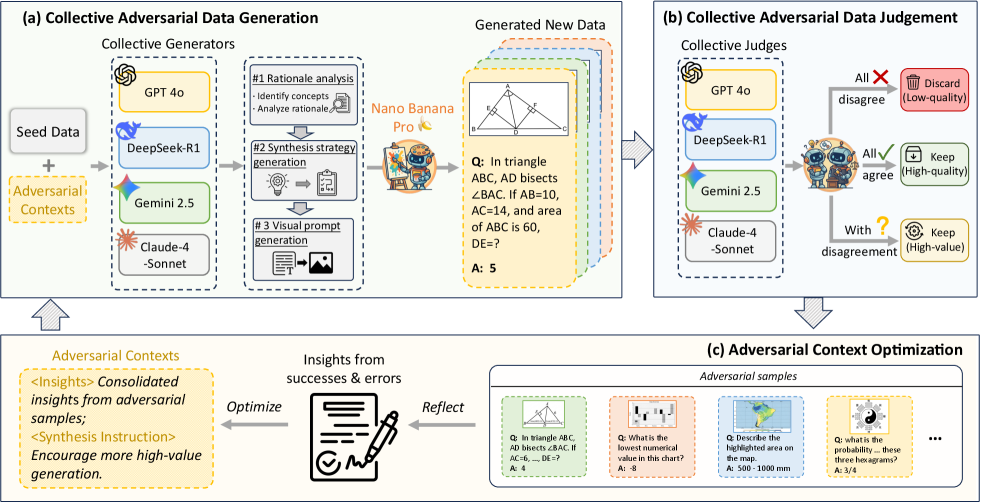
技术框架:CADS框架包含两个循环阶段:集体对抗数据生成(CAD-Generate)和集体对抗数据判断(CAD-Judge)。CAD-Generate阶段利用集体知识共同生成新的和多样化的多模态数据。CAD-Judge阶段协同评估合成数据的质量。此外,CADS还引入了对抗上下文优化机制,用于优化生成上下文,鼓励生成更具挑战性和高价值的数据。整个流程通过循环迭代,不断提升合成数据的质量和难度。
关键创新:CADS的关键创新在于其集体对抗学习机制。与传统的单一代模型生成数据不同,CADS利用多个模型协同生成和评估数据,从而提高了数据的质量和多样性。对抗上下文优化机制则进一步提升了生成数据的难度,使得模型能够学习到更鲁棒的特征。
关键设计:对抗上下文优化机制是关键设计之一,通过优化生成上下文,引导模型生成更具挑战性的样本。具体实现细节(如损失函数、网络结构等)论文中可能未详细展开,属于实现层面的细节。数据集MMSynthetic-20K的构建也是一个关键设计,为后续实验提供了数据基础。
🖼️ 关键图片
📊 实验亮点
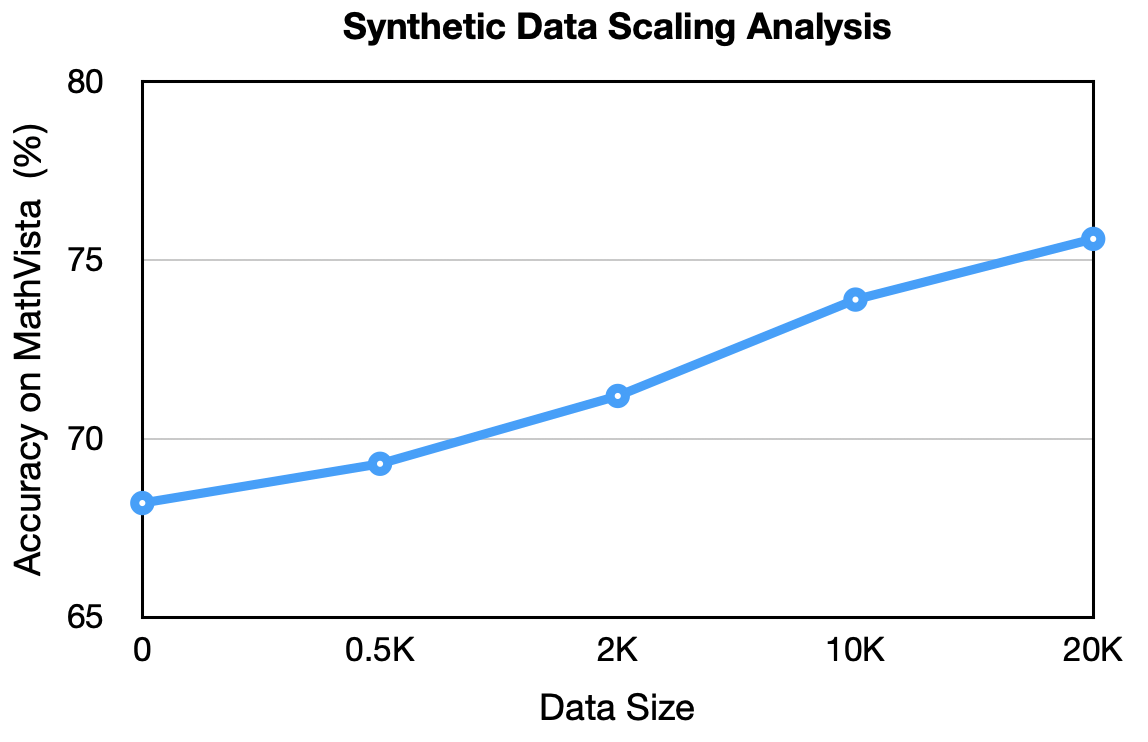
论文构建了MMSynthetic-20K数据集,并基于此训练了R1-SyntheticVL模型。实验结果表明,R1-SyntheticVL在多个多模态基准测试中表现出卓越的性能,验证了CADS框架的有效性。具体的性能提升数据需要在论文中查找,这里无法给出。
🎯 应用场景
该研究成果可广泛应用于需要多模态信息理解和推理的领域,例如智能客服、自动驾驶、医疗诊断等。通过合成高质量的多模态数据,可以降低模型训练的成本,提高模型的泛化能力,并促进相关领域的发展。未来,该方法有望扩展到更多模态和更复杂的任务中。
📄 摘要(原文)
In this work, we aim to develop effective data synthesis techniques that autonomously synthesize multimodal training data for enhancing MLLMs in solving complex real-world tasks. To this end, we propose Collective Adversarial Data Synthesis (CADS), a novel and general approach to synthesize high-quality, diverse and challenging multimodal data for MLLMs. The core idea of CADS is to leverage collective intelligence to ensure high-quality and diverse generation, while exploring adversarial learning to synthesize challenging samples for effectively driving model improvement. Specifically, CADS operates with two cyclic phases, i.e., Collective Adversarial Data Generation (CAD-Generate) and Collective Adversarial Data Judgment (CAD-Judge). CAD-Generate leverages collective knowledge to jointly generate new and diverse multimodal data, while CAD-Judge collaboratively assesses the quality of synthesized data. In addition, CADS introduces an Adversarial Context Optimization mechanism to optimize the generation context to encourage challenging and high-value data generation. With CADS, we construct MMSynthetic-20K and train our model R1-SyntheticVL, which demonstrates superior performance on various benchmarks.